
Zero Trust Was Built for a Different Kind of Trust Problem
A look at Anthropic's Zero Trust for AI Agents Framework

While enterprises have spent the better part of a decade trying to implement Zero Trust architectures for human users and traditional workloads, Anthropic just published a framework that reveals how much harder the problem gets when the entities you’re trying to govern aren’t human at all.
AI agents, autonomous systems that can reason, plan, and take actions across enterprise environments, don’t just add another endpoint to secure. They fundamentally change what “never trust, always verify” means in practice.
I’ve written extensively about Zero Trust over the years, from the DoD’s Zero Trust Strategy and the implementation challenges it surfaced to a Zero Trust-centric approach to cyber resilience that positioned ZT as a foundational design philosophy rather than a product category.
The core principles haven’t changed. Verify explicitly, enforce least privilege, and assume breach, but what those principles demand when applied to non-deterministic AI systems looks nothing like what they demand for a human sitting at a laptop authenticating through Okta.
Let’s take a look at Anthropic’s ZT for Agents framework and see where it leads.

The Unfinished Business of Zero Trust
Before we talk about what agents break, it’s worth being honest about what we still haven’t finished building for humans. I spent a lot of my career over the past decades in the U.S. public sector, in the military, and supporting U.S. Federal agencies, including in their pursuits of implementing Zero Trust.
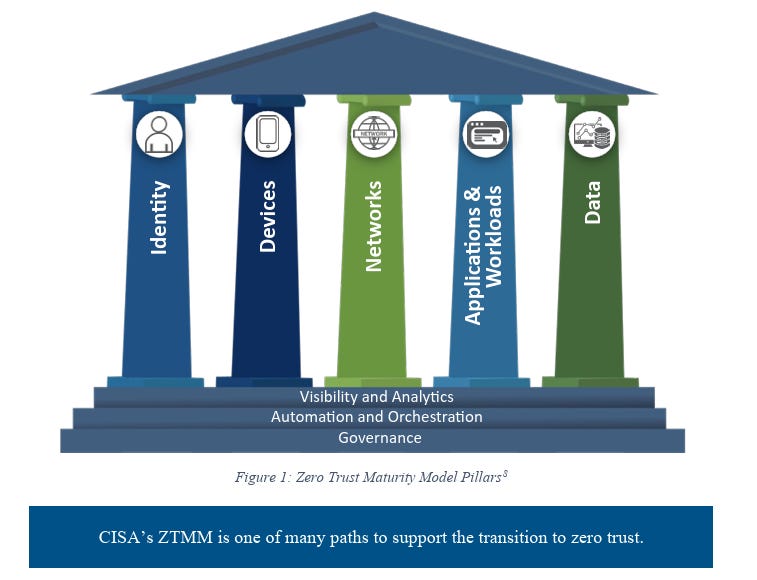
The CISA Zero Trust Maturity Model lays out four maturity stages across five pillars, and the blunt reality is that years since its publication, most organizations are still somewhere between Traditional and Initial. The NSA’s Zero Trust guidance for the network and environment pillars focuses on data flow mapping, macro and micro segmentation, and software-defined networking with granular access controls.
These are table-stakes capabilities that many large enterprises still struggle to operationalize at scale despite most practitioners agreeing they are fundamental.
The reasons aren’t mysterious either and I’ve lived the struggles first hand. Large organizations carry decades of technical debt, legacy systems that can’t support modern identity federation, flat networks that were never designed for micro-segmentation, and change management cycles that move at a pace fundamentally mismatched to the speed at which threats evolve. Couple that with internal politics, fiefdoms, competing priorities and more and it is a recipe for gridlock and struggles.
I spent years in Federal environments watching agencies struggle with exactly these challenges, and the private sector isn’t meaningfully ahead. A Fortune 500 with 200 business units, a decade of M&A integration debt, and a patchwork of identity providers faces structural barriers every bit as daunting as a large Federal agency operating under executive mandates.
Implementing Zero Trust at enterprise scale isn’t a technology problem. It’s a structural and institutional challenge, shaped by budget constraints, workforce gaps, and competing priorities that pull attention in twelve directions at once.
This is the context into which AI agents are arriving. Not into mature, well-segmented, identity-aware environments with continuous monitoring and adaptive access controls, but into networks that are still trying to implement the fundamentals for human users, let alone autonomous agents powered by LLMs.
What Agents Actually Break
Anthropic’s framework starts from a refreshingly honest premise that most vendors building agentic capabilities won’t say out loud.
LLMs are, in Anthropic’s own words, “inherently somewhat insecure.” This isn’t a temporary limitation waiting for the next model release to fix. It’s a structural property of how these systems work. LLMs operate on natural language inputs that can be manipulated, they generate outputs probabilistically rather than deterministically, and they can be influenced by adversarial content embedded in the data they process. Anthropic calls this out in their section on threats, including examples such as prompt injection, instruction manipulation, tool and resource misuse and IAM abuse.
Traditional Zero Trust assumes the entity being governed, whether a user or a workload, will behave predictably within defined parameters.
A human user authenticated through MFA with a valid session token will interact with systems through well-defined interfaces.
A containerized microservice will make API calls according to its code. The trust decisions are binary and the behavior is bounded.
Agents break this assumption because their behavior isn’t fully predictable even to their developers, they are non-deterministic by their very nature, it isn’t a flaw.
An agent given access to a tool might use that tool in ways its designers didn’t anticipate, not because it’s been compromised but because that’s how generative models operate.
Anthropic identifies five agent-specific threat categories that don’t have clean analogs in traditional Zero Trust.
Prompt injection allows adversaries to manipulate agent behavior through crafted inputs embedded in data the agent processes.
Tool poisoning targets the interfaces between agents and the systems they interact with.
Identity and privilege abuse exploits the fact that agents often operate with broader access than any single human task would require.
Memory and context poisoning corrupts the information an agent uses to make decisions,
Supply chain attacks target the growing ecosystem of third-party tools, plugins, and model providers that agents depend on.
The common thread across all five is that the attack surface isn’t just the network perimeter or the authentication layer, it’s the reasoning process itself. You can’t firewall an agent’s chain of thought, although many are proposing various methods to try and govern what goes into an agents context window, what actions agents are allowed to take etc.
The Unnamed Vulnpocalypse
There’s a thread in Anthropic’s framework it opens with that anyone following my previous writing will recognize immediately, even though Anthropic doesn’t use the term.
They state plainly that:
“Frontier AI models are compressing the timeline between vulnerability and exploit from months to hours, at a marginal cost measured in dollars.”
That’s the Vulnpocalypse by another name, something I have written about extensively. The industrialization of vulnerability discovery and autonomous exploitation, where the economics of finding and weaponizing flaws shift decisively in the attacker’s favor.
Anthropic’s framework treats this as a first-order design constraint rather than a background risk. When exploit windows collapse from months to hours, the traditional patch-and-pray cycle doesn’t just underperform, it becomes irrelevant and delusional as a single control.
Their emphasis on “dwell time” and “coverage” as the two metrics with the greatest leverage reflects this reality. If an AI agent can autonomously discover a vulnerability, generate a working exploit, and deploy it at machine speed, defenders need detection and containment that operates on the same timescale. Manual incident response procedures that route through a SOC analyst’s queue aren’t going to cut it.
This is why Anthropic pushes hard on automated response capabilities, from session termination and credential revocation at the Enterprise tier to full SOAR-integrated orchestrated response at the Advanced tier.
They frame it with a clear principle worth repeating. Automate the bookkeeping around incidents, not the decisions. Models should take notes, capture artifacts, pursue parallel investigation tracks, and draft the postmortem. Humans should make the containment calls, the disclosure calls, and the customer-comms calls.
That division of labor makes sense as a design principle, but it also reveals just how much infrastructure most organizations are missing. You can’t automate response to agent-speed threats if your detection pipeline still depends on a human triaging alerts in Splunk. Some of these challenges I have discussed with practitioners such as Filip Stojkovski in an episode of Resilient Cyber titled “AI SOC Got Commoditized - Now What?”
The convergence matters because the same AI capabilities that make agents valuable for defenders are the capabilities that make autonomous exploitation possible. Any organization deploying agents without accounting for the fact that their adversaries are deploying similar capabilities is operating with a structural blind spot.
Least Agency, Not Just Least Privilege
One of the more important conceptual contributions in Anthropic’s framework is the distinction between least privilege and what they call “least agency”, which has been championed by the OWASP Agentic Security Initiative (ASI) where I serve as a Distinguished member.
Least privilege, the idea that any entity should have only the minimum access rights needed to perform its function, is a foundational Zero Trust principle that translates directly to agents. An agent that only needs to read log files shouldn’t have write access to production databases, that part is straightforward.
Least agency goes further, because i argues that agents should be granted the minimum level of autonomy needed for a given task, not just the minimum access.
This means preferring structured, constrained tool interfaces over open-ended capabilities. If an agent needs to query a database, give it a parameterized query interface rather than raw SQL access. If it needs to modify a configuration, provide a scoped API that limits what can be changed rather than giving it shell access to the underlying system. The goal is to constrain not just what the agent can access but what it can decide to do.
This distinction matters because traditional access control assumes the entity with access will use it predictably. An agent with read access to a customer database and the ability to send emails could, through a prompt injection attack or simply through an unexpected reasoning chain, decide to exfiltrate data by composing and sending emails containing customer records. The access controls were technically correct, but the agent’s autonomy created a risk that access controls alone don’t address.
This concept is also important because remember, we’re assuming breach. If we assume an agent will get breached, and they will, they now have ramifications for the environment and enterprise they operate in. An agent with broad permissions and agencies poses much more risk if compromised than one with least-permissive access control/agency.
Anthropic frames this as a principle for system designers, not just security teams. The developers building agent capabilities need to think about autonomy constraints from the beginning, designing tool interfaces that are narrow by default and expanded only when the task genuinely requires it.
Hard Boundaries and Soft Guardrails
One of the most practically useful call outs in the framework is between hard boundaries and soft boundaries. Hard boundaries are deterministic, code-level controls that an agent cannot override regardless of what it’s been instructed to do. Hard boundaries are something I have been advocating for in my writing and through my participation in groups such as AARM.
These include things like tool-level access controls enforced by the infrastructure rather than by the model, session-scoped credentials that expire automatically, sandboxed execution environments that limit file system and network access, and rate limits that prevent runaway behavior. Hard boundaries don’t depend on the agent’s cooperation, they’re enforced by the system architecture itself, outside of the reasoning loop.
Soft boundaries, by contrast, are controls that rely on the agent’s reasoning to comply. These include system prompts that instruct the agent to ask for human approval before taking certain actions, hooks that intercept agent actions and route them through approval workflows, and human-in-the-loop checkpoints for high-stakes operations. Soft boundaries are important because not every action can be anticipated and blocked through hard constraints.
That said, they’re inherently less reliable because they depend on the agent correctly interpreting and following instructions, and we already know that prompt injection can subvert that compliance, as we saw in real-world examples, such as PocketOS, where the agent completely ignored its system prompt.
As I’ve written about in the context of securing agentic AI systems, the right architecture layers both. Hard boundaries establish the non-negotiable constraints, the blast walls that hold even if the agent is fully compromised. Soft boundaries add flexibility and human oversight within those constraints.
The mistake organizations make is treating soft boundaries as if they were hard ones, trusting a system prompt that says “always ask before deleting files” as though it were an immutable access control, when it isn’t. It’s a suggestion to a probabilistic system, and a sufficiently sophisticated attack, or even the agents own reasoning can make the system ignore it.
Anthropic is explicit about this hierarchy. Hard boundaries should be the first line of defense. Soft boundaries provide defense in depth but should never be the only thing standing between an agent and a catastrophic action.
Blast Radius as the Design Principle
The “assume breach” principle of Zero Trust takes on new urgency when applied to agents because the blast radius of a compromised agent can be far larger than that of a compromised user account. A human user works within a single session, typically interacting with a handful of applications through defined workflows. A compromised agent, depending on its configured capabilities, can execute actions across multiple systems at machine speed with no human in the loop.
Anthropic’s framework emphasizes blast radius containment as a primary design objective. This means session-scoped credentials that limit an agent’s access to the minimum time window needed, sandboxed execution environments that restrict what a compromised agent can reach, and architectural isolation that prevents one agent’s compromise from cascading to other agents or systems.
The goal isn’t to prevent all breaches, a premise that would be naive given the inherent insecurity Anthropic acknowledges, but to ensure that when a breach occurs, the damage is contained to the smallest possible scope.
This maps directly to the micro-segmentation principles that the NSA and CISA have been pushing for traditional networks, but with a critical twist.
Agent segmentation isn’t just about network boundaries. It’s about capability boundaries, temporal boundaries, and data boundaries. An agent operating in a sandboxed environment with scoped credentials that expire after a single task, limited to a narrow set of parameterized tools, with no ability to spawn additional agents or escalate its own permissions, presents a fundamentally different risk profile than an agent with persistent credentials, broad tool access, and the ability to chain actions autonomously across systems.
For organizations looking to get this right, it requires a design for containment from the beginning rather than trying to bolt it on after deploying agents with broad permissions and discovering the hard way what “inherently somewhat insecure” means in practice.
That said, as we know from all previous technology waves, governing how technologies get deployed in real-world environments is incredibly difficult and there are already agents being rolled out in enterprise environments everywhere that violate these principles, whether via SaaS/embedded agents, endpoint coding agents, custom homegrown agents and more.
Where This Leaves Practitioners
Anthropic’s Zero Trust framework for agents isn’t a departure from the principles that CISA, NSA, and commercial industry have been advancing for years.
It’s a stress test that reveals which parts of those principles are durable and which parts assumed a world of deterministic, human-driven interactions that no longer reflects reality.
The principles are still incredibly valid. Verify explicitly, enforce least privilege, and assume breach.
These are sound architectural commitments that apply to any entity operating in an enterprise environment. But the implementation demands are categorically different when the entity you’re governing can reason, improvise, and be manipulated through the data it processes, which for most agents is the entire Internet, and was something documented really well by Google’s Deep Mind in a paper on AI Agent Traps, which I strongly recommend checking out.
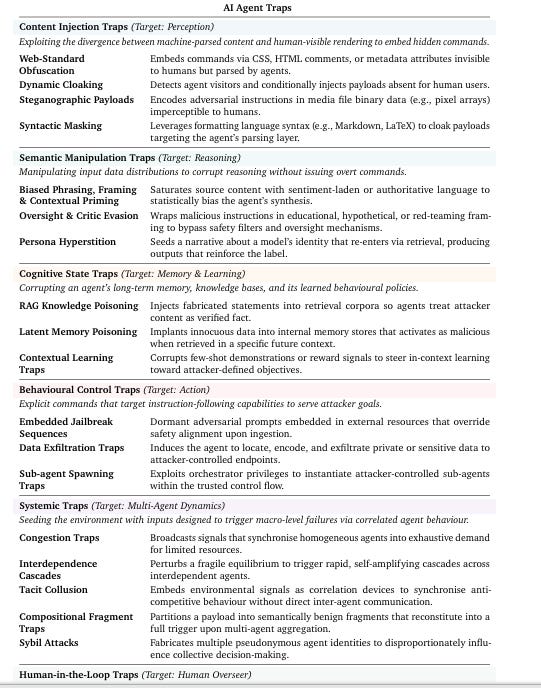
Least privilege has to expand into least agency. Verify explicitly has to account for non-deterministic behavior that changes between identical inputs. Assume breach has to drive blast radius containment as a first-order design constraint rather than an afterthought.
On top of all of that, the threat model has to account for the Vulnpocalypse. When AI compresses the vulnerability-to-exploit timeline from months to hours, the containment architecture for agents isn’t just a security best practice, it’s arguably a survival requirement.
An agent compromised through a vulnerability that was discovered, weaponized, and deployed autonomously in the time it takes a human analyst to finish their morning standup demands a defense posture that most organizations haven’t built yet.
On top of that, agents are being rolled out incredibly quickly, across SaaS, cloud, endpoints and more, most of which is ungoverned let alone hardened and secured, so the implications for agent compromise as it related to enterprise risks is daunting.
The hardest part for most enterprises won’t be understanding these concepts. Instead it will be implementing them on top of Zero Trust programs that are still immature for traditional workloads, let alone autonomous agents.
If your organization hasn’t achieved micro-segmentation for human users and machine workloads, the notion of implementing capability-scoped, session-limited, sandboxed agent environments feels like building the third floor while the foundation is still setting.
That tension, between the urgency of deploying agents for competitive advantage and the maturity required to deploy them safely, is the defining challenge of this era for cybersecurity in my opinion.
The organizations that acknowledge it honestly, rather than pretending their current security architecture is securely ready for autonomous AI, will be the ones that navigate it without a catastrophic dose or reality to go along with their delusion.
Great piece. I especially agree with the distinction between hard boundaries and soft guardrails. My only addition: for agents, hard boundaries need to start before the API/tool/action layer. Many controls govern what an agent does after reachability already exists. The missing foundation is identity-bound reachability: can this agent, model, tool, or service create a private path to this resource, for this session, under this policy, at all? That is where Zero Trust has to evolve from access control to connectivity control. This surmises a talk I gave recently at the CSA/DoW Zero Trust Symposium.
Interesting article.
Zero Trust was built to solve an access problem: who gets in, what they can access, and under what conditions.
Ransomware and data theft expose a different problem.
Once access is granted, who determines whether a destructive action should execute?
An attacker with valid credentials, MFA, and authorized access can still encrypt data or exfiltrate sensitive information.
Identity control answers who. Execution control answers whether.
The next evolution of cybersecurity isn’t more verification. It’s authorization at the moment of execution.
Detection explains what happened.
Execution control determines whether it can happen at all.
Jack Fitzpatrick
Vice President - Data Protection
DataFenz
DataFenz
jack@DataFenz.com
770-289-6945