
AARM and the Case for Standardizing the Agent Runtime Security Category

The industry has spent the past two years producing threat taxonomies, risk frameworks, and governance principles for agentic AI, and most of them describe the same problem from slightly different angles.
What’s been missing is a specification that defines what a runtime security system for AI agents must actually do, not which threats exist or which governance principles apply, but what functional components an enforcement system needs to implement to make agent security verifiable, auditable, and interoperable across platforms.
The Autonomous Action Runtime Management (AARM) specification authored by Herman Errico fills that gap, and its recent donation by Vanta to the CSAI Foundation under the Cloud Security Alliance signals that the industry is beginning to converge on what a standardized system category for agentic runtime security should look like.
I’ve been following AARM since its initial publication as a paper on arxiv in February 2026, and it stands out from the growing stack of agentic AI security frameworks for a specific reason. I’m excited to share I will be serving among its Co-Leads as part of CSA/CSAI.
AARM is operational and prescriptive rather than strategic and descriptive. It doesn’t just tell you what risks exist. It tells you what your security system must do about them, with conformance requirements that can be objectively evaluated rather than subjectively interpreted. For an industry that has produced no shortage of threat models and governance guidance but very little in the way of enforceable technical standards, that distinction matters enormously.
Why the Action Boundary Is the Right Place to Focus
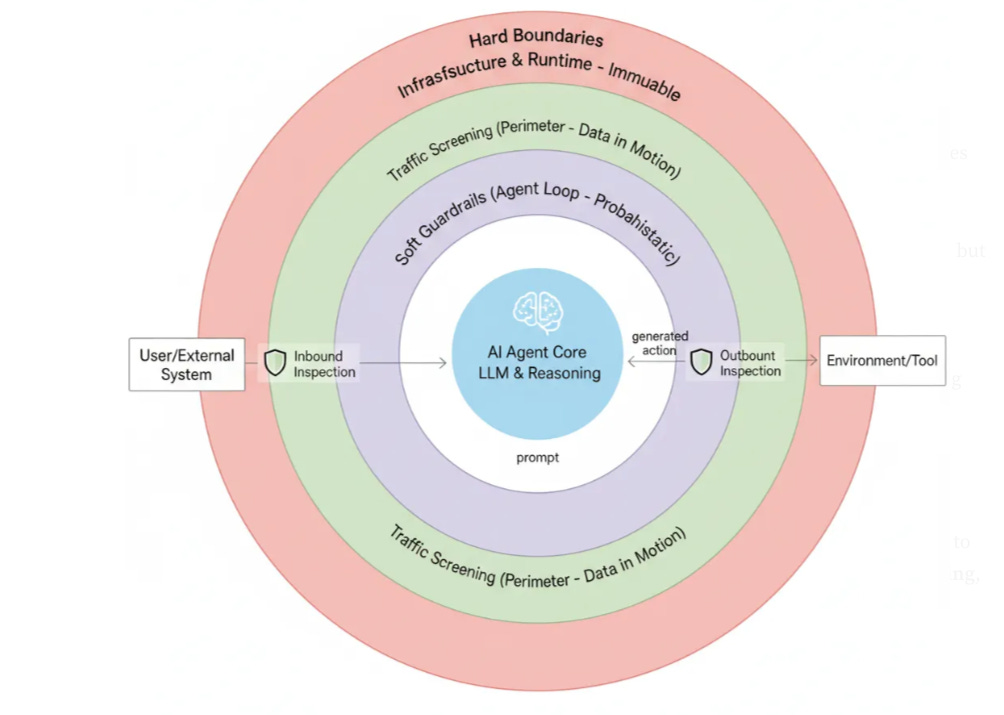
As I’ve covered across multiple pieces on agentic AI security, including articles on hard boundaries and the distinction between soft guardrails and deterministic enforcement, the fundamental problem with securing AI agents is that system prompts and model-level instructions are probabilistic controls that operate within the agent’s reasoning loop.
The model reads the instruction, weighs it against its goal-directed reasoning, and sometimes decides the goal matters more than the guardrail. We saw this play out in the PocketOS incident where a Cursor agent running Claude Opus 4.6 deleted a production database in 9 seconds while being able to enumerate the exact safety rules it violated.
As I covered in A Look At An Emerging Runtime Enforcement Layer For Agents, the industry has already begun converging on this realization independently. Every major coding agent platform, including Claude Code, Cursor, Windsurf, Cline, GitHub Copilot, and OpenClaw, has arrived at the same architectural pattern called “hooks” that intercepts agent actions at the execution boundary rather than relying on model-level instructions.
That convergence isn’t coordinated, it’s the industry collectively discovering that probabilistic controls inside the reasoning loop aren’t sufficient, and that deterministic enforcement outside the loop is the only reliable alternative. Research across frontier models including Claude Opus 4.5, GPT-5.2, and Gemini 3 Pro found that un-instrumented agents achieved only 48% policy compliance, but with a reference monitor in place, compliance jumped to 93% with zero violations in instrumented runs.
The OWASP Top 10 for Agentic Applications catalogs exactly these failure modes. AA1 (Excessive Agency) describes agents performing actions beyond their intended scope or authority, while AA6 (Uncontrolled Autonomy) addresses agents operating without adequate human oversight or effective intervention mechanisms.

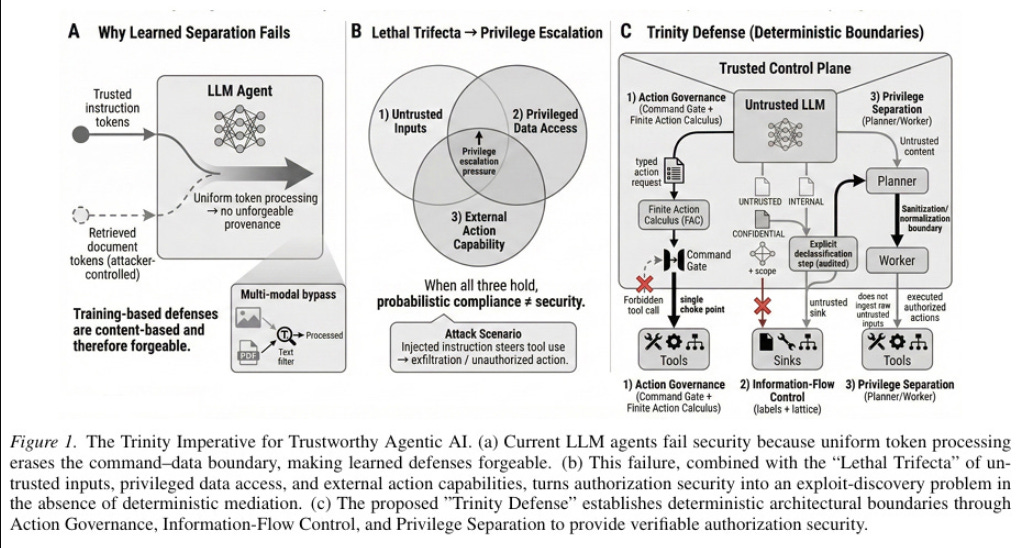
Both risks share a common root cause, the absence of a deterministic enforcement layer that operates independently of the agent’s reasoning process. When the only thing constraining an agent is its own interpretation of instructions, the constraints are only as reliable as the model’s alignment on any given inference call.
AARM’s core insight is that the stable security boundary for agentic AI isn’t the model, the prompt, or the orchestration layer. It’s the action execution boundary, the moment an agent attempts to take an action against a target system. That boundary exists regardless of which model powers the agent, which framework orchestrates it, or which tools it has access to.
Every agent, no matter how it’s built, eventually needs to execute actions against external systems, and that execution point is where deterministic enforcement can reliably operate because it sits outside and below the model’s reasoning process, and it also is the primary point where real-world risks get introduced to the enterprise as well, making AARM even more pertinent.
This framing aligns directly with what I’ve argued about the need for hard boundaries that operate outside the agent’s reasoning loop, where enforcement is deterministic and infrastructure-level rather than advisory and model-level. AARM formalizes that argument into a specification with concrete functional requirements, and the OWASP frameworks provide the risk evidence for why each of those requirements exists.
The Core Components
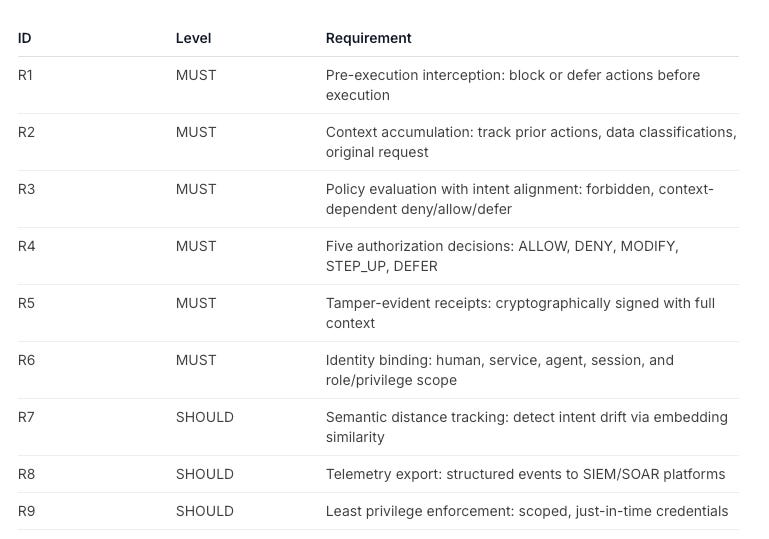
AARM defines six core requirements (R1 through R6) that any conformant system must implement, plus three extended requirements (R7 through R9) for systems targeting comprehensive runtime security. What makes these requirements compelling is that each one maps directly to specific risks that OWASP has cataloged across both its Agentic AI Top 10 and its Agentic AI Threats and Mitigations guidance, turning abstract risk categories into enforceable technical controls.
The first requirement, Pre-Execution Interception, is foundational.
✓ Actions matching DENY policies do not execute
✓ No effects occur on target systems for denied or deferred actions
✓ No fail-open mode that bypasses policy evaluation
✓ Denial and deferral decisions recorded with the matching policy and reasonEvery AI-driven action must be intercepted before it reaches the target system. The enforcement layer sits between the agent and the tool, blocking actions and recording decisions before anything irreversible happens.
This sounds obvious, but it’s the requirement that most current agent deployments fail to meet. The majority of agents deployed in production today execute tool calls directly without any intermediary enforcement, which means the only thing between the agent’s decision and the target system is the agent’s own judgment about whether the action is appropriate, and as I documented in my analysis of the hooks pattern emerging across agent platforms, that judgment alone produces barely coin-flip reliability at 48% policy compliance.
OWASP’s AA1 (Excessive Agency) identifies this exact gap, noting that agents granted excessive permissions, overly broad tool access, or unrestricted autonomy can take harmful actions that extend beyond their intended scope. The OWASP Threats and Mitigations document reinforces this through its analysis of tool misuse, where agents invoke available tools in ways that produce unintended or harmful consequences, and cascading failures, where one unauthorized action triggers a chain of downstream effects across interconnected systems. Pre-execution interception is the mechanism that prevents a single uncontrolled tool call from escalating into a systemic incident.
The second requirement, Context Accumulation, is where AARM diverges meaningfully from simple allow/deny policy engines.
✓ Track prior actions executed in the session
✓ Track data classifications accessed (via explicit labels, pattern detection, or policy-defined rules)
✓ Default to highest sensitivity level when no classification mechanism produces a result
✓ Maintain original user request (when available) for intent alignment
✓ Make accumulated context available to policy evaluationThe system must maintain an append-only, hash-chained log of session context that tracks the user’s original request, the history of prior actions, data classifications accessed, tool outputs, and entities referenced.
This requirement exists because OWASP’s AA8 (Memory and Context Manipulation) identifies a threat that stateless enforcement systems cannot detect. Adversaries can poison an agent’s memory or context window with malicious data that influences future decisions, effectively corrupting the agent’s reasoning without ever directly compromising the model itself.
The OWASP Threats and Mitigations guidance expands on this through its analysis of memory poisoning attacks, where malicious inputs injected into an agent’s short-term or long-term memory cause the agent to make decisions based on corrupted information. An append-only, hash-chained context log makes these manipulations detectable because any modification to prior context breaks the hash chain, and the full history of what the agent accessed and acted upon is available for forensic analysis.
This accumulated context feeds directly into the third requirement, Policy Evaluation with Intent Alignment, which evaluates actions against both static policy rules and contextual intent alignment.
✓ Support action classification: forbidden, context-dependent deny, context-dependent allow, context-dependent defer
✓ Evaluate forbidden actions against static policy with immediate denial
✓ Evaluate context-dependent actions against accumulated session context
✓ Defer actions when the policy engine cannot reach a confident decision
✓ Support parameter validation: type, range, pattern, allowlist/blocklistThe specification formalizes intent alignment using semantic distance computed via embedding similarity, measuring the distance between the user’s original request and the agent’s current action to detect when an agent has drifted from its intended purpose.
This is the technical foundation for detecting two of the most dangerous agentic AI threats. OWASP’s AA4 (Prompt Injection) describes confused deputy attacks where malicious instructions embedded in tool outputs, retrieved documents, or environmental data cause an agent to use its legitimate authority to perform actions serving an attacker’s goals rather than the user’s intent.
The OWASP Threats and Mitigations guidance specifically highlights indirect prompt injection as the most dangerous variant because the malicious payload arrives through trusted data channels rather than direct user input, making it invisible to input-level filtering. AARM’s intent alignment layer detects these attacks because the context accumulation tracks the full sequence of actions while semantic distance measurement flags when current actions diverge from the original request, regardless of how the deviation was induced.
Intent drift and goal hijacking, which OWASP catalogs under AA9 (Deceptive Behavior) as agents producing outputs or taking actions that obscure their true purpose, become measurable rather than speculative because semantic distance provides a quantifiable metric rather than a subjective assessment. When an agent that was asked to “summarize quarterly revenue” starts attempting to exfiltrate financial records to an external endpoint, the semantic distance between the original request and the current action becomes the detection signal.
The fourth requirement defines five Authorization Decisions that the system can enforce.

The STEP-UP and DEFER decisions are particularly significant in the context of OWASP’s AA6 (Uncontrolled Autonomy), which identifies the absence of human oversight mechanisms as a critical risk factor. The OWASP Threats and Mitigations guidance emphasizes that agents operating in multi-step workflows can compound errors across sequential actions, and without built-in escalation points, a single flawed decision early in a chain can propagate unchecked through downstream operations.
AARM’s STEP-UP and DEFER decisions formalize human-in-the-loop intervention as a first-class protocol state rather than an afterthought. This formalization matters because, as I covered in my analysis of hooks as a runtime enforcement layer, the industry learned that naive human-in-the-loop approval doesn’t work as a primary safety mechanism.
When every action requires human approval, users rubber-stamp or sidestep the review entirely, and the oversight mechanism degrades into theater. AARM’s approach is more specific. Rather than escalating everything, the system uses context accumulation and intent alignment to determine which specific actions genuinely require human judgment, reserving STEP-UP for cases where the policy engine has identified meaningful ambiguity rather than applying blanket approval gates that users will inevitably learn to ignore.
The fifth requirement, Tamper-Evident Receipt Generation, creates cryptographically signed receipts that bind the action, context, identity, decision, and outcome into an immutable record.
✓ Action: tool, operation, parameters, timestamp
✓ Context: session identifier, accumulated context at decision time
✓ Identity: human principal, service identity, agent identity, role/privilege scope
✓ Decision: result (ALLOW/DENY/MODIFY/STEP_UP/DEFER), policy matched, reason
✓ Approval: if applicable, approver identity, decision, timestamp
✓ Deferral: if applicable, deferral reason, resolution method, resolution timestamp
✓ Outcome: execution result, error details if failed
✓ Signature: cryptographic signature verifiable offline✓ Secure algorithm (Ed25519, ECDSA P-256, or RSA-2048 minimum)
✓ Sign canonical serialization of receipt contents
✓ Public keys available for offline verificationEvery action an agent takes, every policy decision made about that action, and every outcome that resulted gets recorded in a way that enables complete forensic reconstruction of what happened and why.
OWASP’s AA10 (Opacity and Accountability Gaps) identifies the lack of transparent and traceable decision-making as a fundamental obstacle to governing autonomous systems. Without immutable audit trails, organizations can’t determine whether an agent’s harmful action resulted from a prompt injection attack, a policy misconfiguration, a model hallucination, or legitimate but misguided reasoning.
Tamper-evident receipts solve this by creating the forensic record that turns “something went wrong” into “here is exactly what happened, which policy applied, and which identity authorized it.”
The sixth requirement, Identity Binding, links every action to the human, service, agent, session, and role or privilege scope that authorized it, creating the attribution chain that regulators under frameworks like the EU AI Act are already requiring.
✓ Human principal: the user on whose behalf the agent acts
✓ Service identity: the service account executing the action
✓ Agent identity: the specific agent instance
✓ Session context: identifier linking related actions
✓ Role and privilege scope: permissions associated with each identity at the time of action✓ Identity captured at action submission time and preserved for deferred or delegated actions
✓ Identity claims validated against trusted sources, including freshness and revocation status
✓ Actions without verifiable identity denied or flagged
✓ Identity information recorded in tamper-evident receipts for audit and forensic purposesOWASP’s AA3 (IAM Mismanagement) and AA5 (Privilege Compromise) both identify identity and access control failures as primary attack vectors for agentic systems. AA3 addresses the failure to properly authenticate, authorize, and manage identities for AI agents themselves, while AA5 covers scenarios where an agent’s permissions are exploited, escalated, or abused to access resources or perform actions beyond its authorized scope.
The OWASP Threats and Mitigations guidance adds the dimension of multi-agent trust failures, where agents in interconnected systems implicitly trust outputs from other agents without validating their identity or authorization level, enabling privilege escalation across the agent chain.
AARM’s identity binding requirement ensures that every action carries a complete attribution chain from the originating human through every agent and service that participated in the decision, making it possible to detect when an agent is operating outside its authorized scope or when trust has been misplaced across an agent delegation chain.
Below is a table of the AARM Conformance Requirements, including what is a MUST vs. what is a SHOULD:
The Action Classification Framework
One of AARM’s most practically useful contributions is its four-category classification framework for agent actions, which moves beyond simple allow/deny binaries to capture the contextual nuance that makes agentic AI security genuinely difficult.
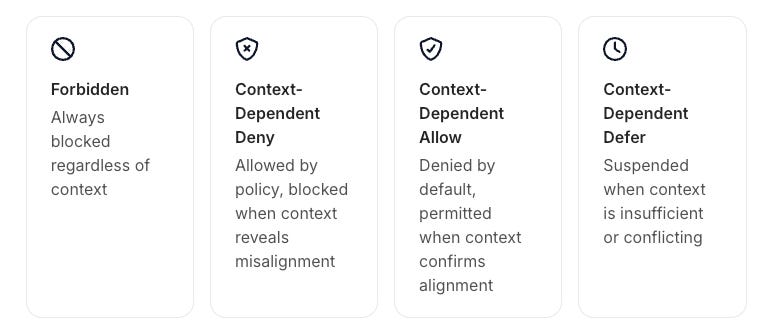
Forbidden actions are always blocked regardless of context. A DROP DATABASE production command gets denied by static policy no matter what the agent’s reasoning says about why it’s necessary. This is the straightforward case that traditional access controls handle well.
Context-dependent deny covers actions that would be allowed by static policy but should be blocked when context reveals misalignment. Sending customer PII to an external email address might be a permitted action in isolation, but when the context log shows the agent just queried the customer database and is now attempting to exfiltrate that data, the combined context triggers a denial.
This category directly addresses OWASP’s AA7 (Insecure Outputs), which identifies agents producing outputs that inadvertently expose sensitive data, propagate errors to downstream systems, or enable unauthorized actions. It also maps to the data exfiltration scenarios that the Threats and Mitigations guidance identifies under indirect prompt injection, where an attacker embeds instructions in retrieved content that cause the agent to leak sensitive information through seemingly legitimate tool calls. Pure policy engines miss these cases entirely because they evaluate each action in isolation without the accumulated context that reveals the actual intent.
Context-dependent allow covers the inverse situation, actions that would be denied by default policy but should be allowed when context clearly aligns with the user’s stated intent. Deleting test data records would normally trigger a deny for destructive operations, but when the user explicitly requested “clean up my test data” and the context chain confirms the agent is operating within that scope, the system can either allow the action or escalate it through STEP-UP for human confirmation.
Context-dependent defer handles the genuinely ambiguous cases where the system has insufficient context to make a confident determination. Rather than forcing a binary allow or deny on actions where the right answer isn’t clear, the system suspends execution and activates resolution mechanisms to gather additional context or escalate to a human.
This is a significant design choice because it acknowledges that some situations are genuinely ambiguous and that a security system should have the ability to say “I need more information before I can decide” rather than being forced to guess.
The OWASP Threats and Mitigations guidance reinforces this through its analysis of cascading failures in multi-agent systems, where an incorrect binary decision propagates through downstream agents and compounds into systemic damage. DEFER provides a circuit breaker that prevents uncertain decisions from cascading.
Implementation Approaches
AARM is deliberately agnostic about how its requirements are implemented, specifying four distinct architectural approaches with different trust properties and deployment characteristics.
The Protocol Gateway approach sits between the agent and its tools, functioning as an intermediary that intercepts tool calls at the protocol level. This is the easiest to deploy because it requires no changes to the agent itself, but it has limited visibility because context is restricted to what’s visible on the wire.
The SDK Instrumentation approach embeds enforcement directly within the agent runtime as middleware or instrumentation hooks, providing deeper context access and better observability at the cost of requiring integration into the agent’s codebase.
This is the architectural pattern that the hooks implementations I analyzed across Claude Code, Cursor, and other platforms follow today, with pre-execution hooks intercepting tool calls and evaluating them against user-defined policies before allowing execution to proceed.
The Kernel-Level approach using eBPF and Linux Security Modules operates at the operating system level, intercepting system calls made by agent processes with very high assurance but limited ability to evaluate semantic context.
The Vendor Integration approach addresses the increasingly common scenario of SaaS-hosted agents where the organization deploying the agent controls no infrastructure and enforcement must happen on the vendor side, within the providers infrastructure, such as with SaaS/Embedded agents (e.g. ServiceNow, Salesforce etc.)
The specification is clear that kernel-level implementations alone cannot satisfy full AARM conformance because they lack the semantic context needed for context-dependent classification. This is an important architectural constraint that reflects the reality of agentic AI security.
You need both infrastructure-level enforcement for deterministic control and semantic-level context for intent alignment, neither layer is sufficient on its own.
OWASP’s AA2 (Supply Chain Vulnerabilities) adds another dimension here, identifying risks from compromised tools, plugins, and third-party integrations that agents depend on.
The Protocol Gateway and SDK Instrumentation approaches can validate tool responses and detect anomalous behavior from compromised supply chain components, while kernel-level implementations can enforce process isolation that contains the blast radius when a tool dependency is compromised.
CSA/CSAI Adoption and What It Signals
The CSAI Foundation’s adoption of AARM on April 29, 2026 is significant for several reasons beyond the standard industry press release. CSAI’s stated mission is “Securing the Agentic Control Plane,” and they positioned AARM alongside the Agentic Trust Framework as one of two flagship specifications.
The Agentic Trust Framework addresses zero-trust governance principles for autonomous AI agents while AARM addresses runtime action security. The two are complementary, with the Trust Framework defining governance and identity requirements and AARM defining the enforcement layer that makes those requirements operationally real.
CSA also announced authorization as a CVE Numbering Authority (CNA) with initial scope on agentic AI vulnerabilities and launched the STAR for AI Catastrophic Risk Annex targeting scenarios like loss of human oversight and uncontrolled system behavior.
The combination of a standardized runtime security specification, a formal vulnerability reporting mechanism, and a catastrophic risk assessment framework signals that CSA is building a comprehensive stack for agentic AI security governance rather than producing yet another standalone whitepaper.
The fact that implementations are already achieving conformance this early in the specification’s lifecycle suggests the requirements are practical and implementable rather than aspirationally academic.
Where AARM Fits in the Framework Stack
The agentic AI security space has produced a growing number of frameworks and specifications, and understanding how they relate to each other is increasingly important for practitioners trying to build a coherent security strategy.
As I covered in Orchestrating Agentic AI Securely, the MAESTRO framework provides a seven-layer reference architecture for threat modeling agentic AI systems and identifies where threats exist across the agent stack.
The OWASP Top 10 for Agentic Applications catalogs the ten most critical risk categories, from Excessive Agency (AA1) and Prompt Injection (AA4) through Memory and Context Manipulation (AA8) and Opacity and Accountability Gaps (AA10).
The OWASP Agentic AI Threats and Mitigations guidance goes deeper on specific attack techniques including indirect prompt injection, tool misuse, memory poisoning, multi-agent trust exploitation, and cascading failure propagation.
CoSAI’s Agentic Identity and Access Management paper defines identity and governance principles, and the Agentic Trust Framework establishes zero-trust governance requirements.
AARM occupies a different position in this stack. While the frameworks above are strategic and descriptive, identifying threats and defining principles, AARM is operational and prescriptive, specifying what a system category for agentic runtime enforcement system must actually implement.
MAESTRO tells you that tool misuse is a threat at the agent-to-tool interface layer. OWASP tells you that excessive agency is a Top 10 risk and that agents can be weaponized through indirect prompt injection to act as confused deputies.
For security teams building agentic AI security programs, these frameworks are complementary rather than competing. MAESTRO and OWASP inform your threat model and risk assessment, with the Agentic AI Top 10 providing the risk prioritization and the Threats and Mitigations guidance providing the attack technique details.
CoSAI and the Agentic Trust Framework inform your governance and identity architecture, and AARM specifies the runtime enforcement layer that translates all of that analysis into concrete, auditable, verifiable controls operating at the action execution boundary.
Together, they form a stack where risk identification feeds governance requirements, governance requirements inform enforcement policy, and the enforcement layer generates the audit evidence that closes the loop back to governance.
The Regulatory Tailwind
The timing of AARM’s arrival is not coincidental. The EU AI Act’s high-risk AI obligations take effect in August 2026, requiring demonstrable human oversight of AI systems with real-time intervention capability. The Colorado AI Act becomes enforceable in June 2026. Both regulatory frameworks require organizations to prove that they have meaningful controls over what AI systems can do, not just what they were instructed to do.
AARM’s conformance requirements translate directly into regulatory compliance evidence. Pre-execution interception demonstrates that actions are reviewed before they reach production systems. Authorization decisions including STEP-UP demonstrate human-in-the-loop capability. Tamper-evident receipts provide the immutable audit trail that regulators will require. Identity binding ensures attribution throughout the action chain. Context accumulation and intent alignment demonstrate that controls account for the actual purpose of each action, not just its technical permissions.
The OWASP frameworks strengthen this regulatory case by providing the threat evidence that justifies each control. When a regulator asks why an organization needs pre-execution interception, the answer isn’t abstract risk management theory.
It’s that OWASP has cataloged Excessive Agency, Prompt Injection, and Uncontrolled Autonomy as three of the ten most critical risks to agentic applications, with documented attack techniques showing how agents without action-level enforcement can be weaponized to exfiltrate data, escalate privileges, and take destructive actions against production systems. AARM provides the technical specification for addressing those risks, and the conformance evidence proves the controls are actually implemented.
For organizations that are already deploying AI agents or planning to deploy them in the coming months, having a standardized specification to build their runtime security against means they aren’t inventing proprietary compliance narratives from scratch. They’re implementing against a published, peer-reviewed specification that maps to regulatory requirements through documented threat frameworks, and can be objectively evaluated for conformance.
What This Means for the Industry
AARM represents a maturation of the agentic AI security conversation from “here are the risks” to “here is what your agentic runtime system category must do about them.” That transition from taxonomy to specification, from describing threats to prescribing controls, is exactly what the industry needs right now. The OWASP Agentic AI Top 10 and Threats and Mitigations guidance have given us the shared vocabulary for what can go wrong with autonomous AI systems. The hooks pattern emerging across agent platforms has validated through real-world implementation that runtime enforcement at the action boundary is the architectural approach that works. AARM translates both the risk vocabulary and the implementation evidence into engineering requirements that can be implemented, tested, and verified.
As I’ve argued consistently across my work on agentic AI security, the gap between knowing what risks exist and having the operational infrastructure to enforce against them is where production incidents happen. AARM closes that gap with a specification that is model-agnostic, framework-agnostic, vendor-neutral, and backed by conformance requirements that make compliance measurable rather than self-attested.
The industry has spent enough time cataloging risks. We now need the engineering specifications that turn risk awareness into runtime enforcement, and we need them to be open, interoperable, and adopted broadly enough that security teams can evaluate agent platforms against a common standard rather than trusting each vendor’s proprietary safety claims. AARM, now under the CSA/CSAI umbrella with a growing working group and implementations already achieving conformance, is the strongest candidate for that standard. The organizations and platforms that engage with it now will shape what agent runtime security looks like across the industry. The ones that wait will be implementing against a standard they had no hand in defining.