
The Vulnpocalypse Goes GA
Fable 5, Vulnmaxxing, and the Circular Economics of AI-Driven Security

When Anthropic launched Claude Mythos Preview through Project Glasswing in April, the vulnerability discovery capabilities were staggering but access was restricted. Glasswing partners discovered over 10,000 high-or-critical-severity vulnerabilities across systemically important software, including 271 zero-days in Firefox alone and a 27-year-old bug in OpenBSD that had survived decades of human review.
As of today, the core model behind those capabilities is generally available. Claude Fable 5, a Mythos-class model wrapped in safety classifiers, is now accessible to anyone with an API key at $10 per million input tokens and $50 per million output tokens. The capabilities that were gated behind government partnerships and vetted research programs two months ago are now commercially available.

As I wrote in Claude Mythos: Why It Matters (And Why It Doesn’t), the significance of Mythos was never just about one model’s benchmarks. It was about what those benchmarks signaled for the structural economics of vulnerability discovery and exploitation.
With Fable 5, that signal goes from preview to production. The Vulnpocalypse I’ve been writing about, the structural asymmetry between AI-accelerated discovery and the capacity to remediate, just became accessible to every organization and every adversary with a credit card.
The Benchmarks
Fable 5 leads or matches the best available models across virtually every coding and reasoning benchmark.
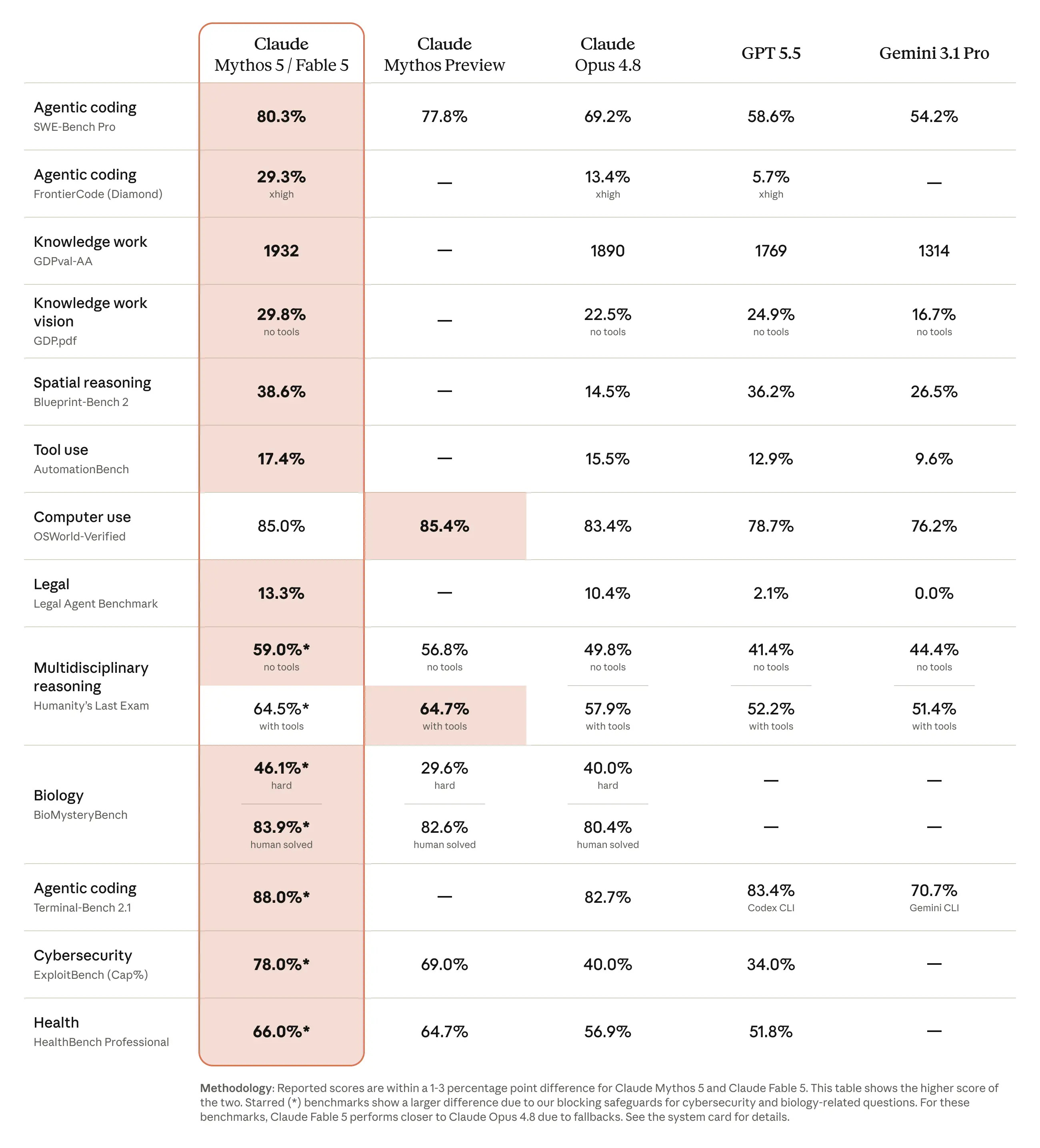
On SWE-bench Verified it scores 95.0%, and on SWE-bench Pro it hits 80.3%, compared to 69.2% for Claude Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. On Terminal-Bench 2.1 it scores 88.0%, on CursorBench it reaches 72.9% at max effort.
These aren’t marginal improvements, the gap between Fable 5 and the next best competitor on coding tasks is significant enough that it represents a qualitative shift in what autonomous coding agents can accomplish in production environments. In the PR from Anthropic they discuss how Stripe reported that Fable 5 completed a 50-million-line Ruby codebase migration in a single day, work that would have required two months of team effort.
The cybersecurity benchmarks come from the Mythos lineage, since Fable 5 and Mythos 5 share the same underlying model. During the Mythos Preview period, the model achieved a 73% success rate on expert-level CTF challenges, making it the first AI model to solve challenges at that difficulty tier. It completed a 32-step corporate network takeover simulation end-to-end as I discussed previously, in reporting from the UK’s AI Security Institute (AISI).
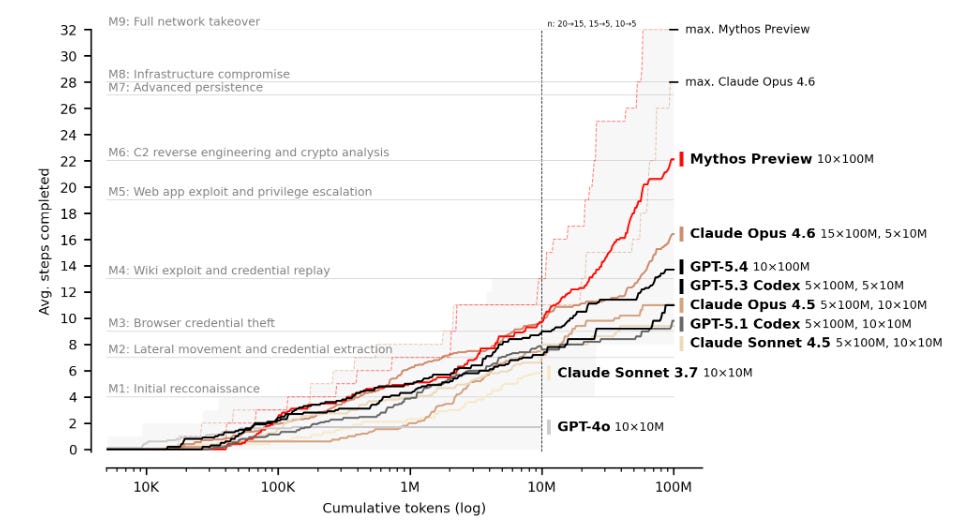
On ExploitGym, it successfully exploited 157 of 898 real-world vulnerabilities and developed 181 working exploits including a 20-gadget ROP chain against FreeBSD and a four-vulnerability browser sandbox escape. As I covered in The AI Cyber Capability Curve, the capability curve for frontier models on cyber tasks has been steepening with every release. Fable 5 represents another significant step up that curve, and this time the step is commercially available rather than gated.
Anthropic’s own scan of over 1,000 open-source projects during the Glasswing preview estimated 23,019 total vulnerabilities, with 6,202 classified as high or critical. Cloudflare, one of the Glasswing partners, found 2,000 bugs across their codebase with 400 rated high or critical, and reported false positive rates better than human testers. Partners across the program saw greater than 10x improvement in bug-finding rates. These numbers should be familiar to readers who followed my coverage in The Receipts Are In, but they take on new weight now that the underlying model is generally available.
The Jagged Frontier
One of the most important counterpoints to the Fable 5 narrative comes from research that Anthropic itself published alongside the launch, and from independent work by researchers like Niels Provos and AISLE. The capability distribution across AI models for cybersecurity tasks isn’t a smooth curve where bigger and more expensive models always win. It’s what AISLE calls a “jagged frontier,” where rankings reshuffle completely depending on the specific task and where with effective harness engineering, zero day discovery can be available to anyone, even with older, smaller and less capable models.
The numbers here are striking as well. A 3.6-billion parameter model, running at $0.11 per million tokens, which is 600x cheaper than Mythos, correctly detected Mythos’s flagship FreeBSD exploit, identifying the stack buffer overflow, computing remaining buffer space, and assessing it as critical with RCE potential.
Eight out of eight models AISLE tested detected the same vulnerability, including open-weights models like GPT-OSS-120B with only 5.1 billion active parameters. Niels Provos built an open-source framework called IronCurtain that achieved autonomous discovery of new zero-days in foundational software using a mix of commercial and open-weight models, leading him to argue that “vulnerability discovery is an orchestration problem, not a frontier-model problem.” Vidoc Security independently reproduced Anthropic’s Mythos findings with publicly available models, reaching the same conclusion.
Both AISLE and Vidoc concluded that the real moat isn’t the model, it’s the security expertise to operationalize the bug discovery process, building the harness, validating the results, and triaging findings against actual exploitability.
This matters because it directly challenges one of the two core narratives that emerged from the Mythos marketing campaign, that only the most powerful and expensive frontier models can do this work, and that they do it autonomously. The research shows that cheaper models can find the same vulnerabilities, and that the orchestration and expertise surrounding the model matters more than the model itself.
But the practical reality for most attackers and security researchers is more nuanced. Building the orchestration harnesses, targeting logic, iterative deepening, validation pipelines, and triage workflows that Provos describes in his IronCurtain framework is itself a significant engineering effort.
Most researchers and most attackers won’t build that infrastructure. They’ll use the most capable generally available model they can access through an API, and as of today, that model is Fable 5. The jagged frontier is real and the research matters, but the GA release of a Mythos-class model changes the practical calculus for the vast majority of users who want capability without building custom harnesses.
The Hype Cycle as Lead Funnel
There’s a pattern worth examining honestly in how this release played out and it is one skeptics have been pointing out and I want to acknowledge it as well. In April, Anthropic gated Mythos behind a government partnership, published benchmark results showing unprecedented vulnerability discovery capabilities, and framed the model as too dangerous for general release. Two months later, the same underlying model is available to anyone with an API key. The framing shifted from “this is so dangerous we can’t release it publicly” to “here it is, with safety classifiers, for $10 per million input tokens.”
Adrian Sanabria wrote about this dynamic in his piece on what he calls “vulnmaxxing,” and his analysis raises some excellent points. Sanabria’s argument is that the Mythos launch wasn’t just a marketing campaign, it was a lead funnel.
Convince the world’s largest software makers that they need Mythos-class capabilities to find vulnerabilities in their code, and then you’ve created demand for the same AI to fix those vulnerabilities, because the volume of findings is too high for human remediation alone. The circular logic is hard to ignore, as AI finds the bugs, for a price and then AI fixes the bugs, for a price, and both sides of that equation run through the same vendor’s API.
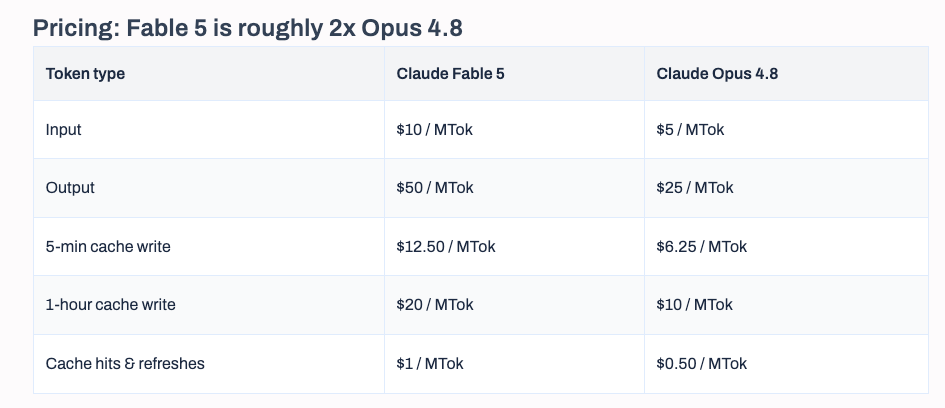
The pricing tells part of the story. Fable 5 at $10/$50 per million tokens is double the cost of Claude Opus 4.8 at $5/$25. Mythos Preview ran at $25/$125. Anthropic gave away $100 million in free Mythos credits during the Glasswing preview, which seeded adoption and generated the vulnerability findings that are now cited as evidence that organizations need Mythos-class capabilities. Whether you see this as responsible scaling or as market creation depends on how much credit you give to the security narrative versus the commercial incentive structure.
Sanabria raises a related concern around the security poverty line. The 1% of companies with the largest engineering budgets can afford a Mythos-level audit of their codebases and the AI-assisted remediation that follows.
Everyone else either builds their own harnesses using cheaper models, which requires security expertise and engineering investment most organizations don’t have, or falls further behind. The gap between organizations that can afford AI-augmented security and those that can’t may widen rather than narrow with each frontier model release.
There’s also a question about the value of what’s being found. Cyentia’s research shows that 98% or more of all vulnerabilities are of low-to-no concern from an attacker’s perspective. The findings from Glasswing and Fable 5 scans will follow this same distribution. Anthropic’s marketing uses the language of “zero-day discovery,” but as Sanabria points out, a vulnerability with no value to an attacker is a software bug, not a meaningful security finding.
The volume of discoveries is impressive but the fraction of those discoveries that represent genuine risk to the organizations affected is a different and much smaller number. Organizations that can’t distinguish between the two will burn tokens and remediation cycles on findings that don’t actually reduce their risk.
This makes concepts such as effective vulnerability management (literally the title of a book I wrote) along with vulnerability prioritization (e.g. KEV, EPSS, reachability, business context etc.) even more critical.
The Safeguards
Anthropic’s approach to releasing Mythos-class capabilities to the general public hinges on three safety classifiers built into Fable 5 that aren’t present in the gated Mythos 5 deployment. Nathan Lambert wrote an excellent piece diving into some of those safeguards titled “Claude Fab 5 and New AI Safety Fables”.
The cybersecurity classifier prevents exploitation and offensive cyber tasks, with Anthropic reporting over 1,000 hours of red-teaming that found no universal jailbreaks, and zero compliance on harmful single-turn cyberattack requests across 30 public jailbreak techniques.
The biology and chemistry classifier applies broad safeguards on dual-use research, tuned conservatively toward safety. The distillation prevention classifier blocks large-scale extraction attempts designed to train competing models, something we’ve even seen The White House release memos of concern on, especially when it comes to maintaining the edge in AI over China. When any classifier triggers, the request falls back to Claude Opus 4.8 rather than refusing outright, which Anthropic says happens in less than 5% of sessions on average.
Mythos 5, the version without these classifiers, remains gated. Cyber safeguards are lifted only for Project Glasswing partners working with the U.S. government. Biology and chemistry safeguards are lifted only for select researchers enrolled in Anthropic’s life sciences program.
This tiered approach, same model with different guardrail configurations depending on the use case and the vetting of the user, is Anthropic’s answer to the dual-use challenge.
Whether the cybersecurity classifiers hold against motivated adversaries over time is an open question that the red-teaming results can’t fully answer, because the adversarial community hasn’t had access to the GA model long enough to develop novel techniques against it. I will definitely be keeping an eye on this aspect of things in the coming days/weeks to see what jailbreaks do emerge as the community gets to it.
Policy Is Already Behind
The timing of this release is hard to ignore. The White House signed the “Promoting Advanced Artificial Intelligence Innovation and Security“ executive order just last week, on June 2nd.

For those not familiar with it, I provided a detailed video breakdown of the EO:
That EO directs NSA to develop a classified benchmarking process within 60 days to determine which AI models qualify as “covered frontier models” and directs Treasury, NSA, and CISA to stand up an AI cybersecurity clearinghouse to coordinate vulnerability scanning and remediation.
As I discussed in my written and video coverage of the EO, none of those constructs exist yet. The NSA hasn’t designated any covered frontier models or likely even codified the criteria. The clearinghouse hasn’t been formed, the benchmarking process hasn’t been developed, and today, a Mythos-class model went GA.
This is the structural challenge I’ve been writing about. Policy operates on 30-day and 60-day timelines at best, often longer, while model capabilities advance on continuous deployment cycles. The Agentic SDLC runs on an entirely different pace than the regulatory and policy lifecycle does.
The EO’s vulnerability clearinghouse is a good idea, and the early access provision that gives government defenders a 30-day preview of frontier models before public release is a genuinely novel mechanism. But Fable 5 is available today, and the governance infrastructure the EO envisions won’t be operational for weeks or months. The models don’t wait for the institutions to catch up.
Even then, the 30d preview period will do little to nothing for actual remediation in real-world government and critical infrastructure environments where I’ve spent most of my carer, as the AI-driven vulnerability discovery meets the analog reality of the people, process and technology paradigm and massive vulnerability backlogs that existed well before the rise of LLM’s and Mythos class models.
The EO’s voluntary framework for industry participation makes this gap even more visible. Anthropic is voluntarily implementing safety classifiers, voluntarily gating Mythos, and voluntarily partnering with the government through Glasswing.
These are real commitments from a company that has consistently invested in safety research. But the framework depends on the frontier labs choosing to cooperate, and as I explored in The Regulation Pendulum, the open-weights ecosystem and smaller labs operating outside the voluntary framework face no equivalent constraints. The next model with Fable 5-class vulnerability discovery capabilities might not come with safety classifiers or government partnerships attached.
What This Means for the Ecosystem
The GA release of Mythos-class capabilities creates pressure across the entire software ecosystem, and the pressure is compounded by the dynamics Adrian Sanabria identifies.
For open-source maintainers, this is an acceleration of a problem that was already overwhelming and which has been well documented by industry leaders such as cURL’s Daniel Stenberg.
The Glasswing preview showed what happens when frontier AI models are pointed at large open-source codebases. Hundreds of high-severity vulnerabilities surface in projects maintained by small teams or individual developers who are already stretched thin.
This creates unintended outcomes and challenges in the real world. Code repositories are already going private as maintainers try to survive what he calls the vulnpocalypse through obscurity. As I’ve written about since Death Knell of the NVD, the vulnerability data infrastructure is buckling under the volume of discoveries that existed before AI-accelerated scanning. The NVD backlog, the strain on CVE numbering authorities, and the remediation gap between discovery and fix are all structural problems that Fable 5’s general availability will intensify. The Attack Surface Exponential is real, and now anyone can point a Mythos-class model at it.
For enterprise security teams, the math gets harder in multiple dimensions. Organizations already drowning in vulnerability backlogs will face an acceleration in externally reported findings as researchers, bug bounty hunters, and automated scanning services adopt Fable 5.
The remediation capacity doesn’t scale at the same rate as the discovery capacity, and if the fix for AI-discovered vulnerabilities is AI-generated patches, organizations face a new set of unknowns. We have limited visibility into what vibe-coded patches are doing to the future security and stability of codebases, and the pace of AI-generated fixes may not leave time for the human review that historically catches the secondary bugs that patches introduce.
The core tension of the Vulnpocalypse, the gap between the velocity of findings and the velocity of quality fixes, just widened.
There is a genuine opportunity on the other side of this. The same capabilities that enable vulnerability discovery at scale can be turned inward. Organizations can use Fable 5 to scan their own codebases, identify high-severity vulnerabilities in their own products and internal tools, and fix them before external researchers or adversaries find them first.
Cloudflare’s results, 2,000 bugs identified with false positive rates better than human testers, show what AI-assisted internal hardening looks like when applied systematically, but we have to remember most security and engineering teams don’t look like Cloudflare’s.
Concerns about the security poverty line are real. The organizations best positioned to capture this opportunity are the ones with the engineering budgets, security expertise, and triage workflows to separate the 2% of findings that matter from the 98% that don’t.
For everyone else, the flood of AI-generated findings without the context to prioritize them risks becoming noise that makes an already impossible triage problem worse.
Where This Leaves Practitioners
The GA release of a Mythos-class model is a structural inflection point, but what practitioners do with that inflection depends on how clearly they see both the opportunity and the business model underneath it.
The capabilities are real, Fable 5 can find vulnerabilities that human reviewers miss, at a speed and scale that manual code review can’t match and genuinely do represent a step-change in frontier model capabilities.
The hardening opportunity is genuine, and organizations that use it to find and fix their own most critical vulnerabilities before adversaries do will have a meaningful defensive advantage, but the framing matters too.
Not every vulnerability AI discovers is a zero-day that demands urgent remediation. Most are software bugs that have no realistic exploitation path. The organizations that treat every AI-generated finding as a critical priority will burn budget and remediation capacity on work that doesn’t reduce risk. The ones that pair AI-assisted discovery with mature triage and exploitability analysis, informed by the same prioritization discipline practitioners have been building for years, will get the most value. This is also a topic my friend James Berthoty has discussed in various pieces of his own as well.
The policy infrastructure the AI EO envisions, from the NSA’s frontier model designation to the vulnerability clearinghouse, is necessary but not yet operational, and the models aren’t waiting.
The jagged frontier research from AISLE and Provos should inform how security teams think about their own tooling strategy, because it means you don’t necessarily need the most expensive model to get meaningful results if you have the expertise to build the orchestration around cheaper alternatives.
The circular economics of AI finding bugs that AI then fixes, with both sides running through the same vendor’s API at double the cost of the previous generation, should be weighed with the same skepticism practitioners apply to any vendor’s pitch about why you need their product to solve a problem their other product helped create.
The Vulnpocalypse went GA today.
What practitioners do with it, whether they use it to harden their own code, get buried under the volume of findings, or recognize the commercial dynamics shaping how these capabilities are marketed, will depend on whether they approach it as a tool or accept it as a narrative.
"Sanabria’s argument is that the Mythos launch wasn’t just a marketing campaign, it was a lead funnel."
Which is exactly what I said repeatedly: that Anthropic was using this to get in with the US government after the Pentagon fiasco.
And now Anthropic is not only providing Mythos to the US government - specifically the NSA - it is also deploying its engineers to assist the NSA on site.
The NSA is reported to be using Mythos for "offensive purposes."
So much for Anthropic being the "safety first" company.
As for the "guardrails", NIST just released this mathematical proof that guardrails do not and can not work. This has been known to some AI security experts for some time.
NIST Mathematical Proof Supports Transition to a Continuous-Monitor-and-Update Security Model for AI Systems
The proof provides a rigorous explanation of the importance of transitioning from a “one and done” security model.
June 9, 2026
A new proof shows that a fixed set of guardrails placed on AI is not universally robust against adaptive adversarial prompts.
The proof extends to AI the logic used by famed mathematician Kurt Gödel, whose incompleteness theorems have had a profound effect on math for nearly a century.
The findings show that developers and organizations deploying AI systems need to dedicate resources to finding prompts that would break the security of AI systems, and to address them before adversaries can exploit them.
https://www.nist.gov/news-events/news/2026/06/nist-mathematical-proof-supports-transition-continuous-monitor-and-update
Here is the referenced paper:
https://arxiv.org/pdf/2512.10100