
The AI Cyber Capability Curve
Two frontier labs, one collapsing defensive infrastructure, and a curve that keeps steepening

When Anthropic released Claude Mythos Preview in April 2026, it was tempting to treat the moment as a singular event. A frontier lab built an impressive model, found some bugs, and the cybersecurity community spent a week debating whether it was breakthrough or marketing theater.
I spoke about this in Claude Mythos: Why It Matters (And Why It Doesn’t), trying to separate the signal from the noise.
Two weeks later, the UK AI Safety Institute published its evaluation of OpenAI’s GPT-5.5, and the signal became impossible to ignore. This isn’t one model having a good day. It’s a capability curve, and it’s steepening with every release.
The AISI’s evaluations of both Mythos Preview and GPT-5.5 give us the most rigorous independent assessment we have of frontier AI cyber capabilities, and the picture they paint deserves a more careful examination than the headline treatment it’s gotten so far.
Because when you layer these evaluations on top of what AISLE has demonstrated with small open-source models, what MOAK and the Zero Day Clock have shown about exploitation timelines, and the structural reality I’ve been writing about in pieces like Vulnpocalypse and The Attack Surface Exponential, a pattern emerges that the industry can’t afford to keep treating as theoretical or some future state.
We’re already here, and there’s no turning around, as each model release takes us further down the cyber capability path than the last.
Prefer to listen? You can watch my breakdown of the AI Cyber Capability Curve below:
What the AISI Actually Found
The UK AI Security Institute runs a suite of 95 narrow cyber tasks across four difficulty tiers, built in capture-the-flag format to evaluate vulnerability research, exploitation, and a range of offensive security skills.
The centerpiece of their evaluation framework is something called “The Last Ones,” or TLO, a 32-step corporate network attack simulation modeled on a real enterprise kill chain. It spans four subnets and roughly twenty hosts, moving from initial reconnaissance through privilege escalation, lateral movement, and full network takeover. The AISI estimates a human expert would need around 20 hours to complete the full chain.
Claude Mythos Preview was the first model to solve TLO end-to-end, which their detailed in their evaluation of Claude Mythos Preview’s cyber capabilities, completing the full 32-step chain in 3 out of 10 attempts.
Across all attempts, Mythos averaged 22 out of 32 steps. For context, Claude Opus 4.6, the next best performing model at the time, averaged 16 steps and never completed the full chain. On expert-level narrow cyber tasks, which no model could complete before April 2025, Mythos succeeds 73% of the time. Each attempt was given a 100-million-token compute budget, and the AISI noted that performance continued to scale up to that limit, suggesting further improvements beyond it and further reinforcing the idea that cyber, like other aspects of AI, can be addressed via scaling laws and additional compute, ironically something that is also a supply chain constraint, even for Anthropic.
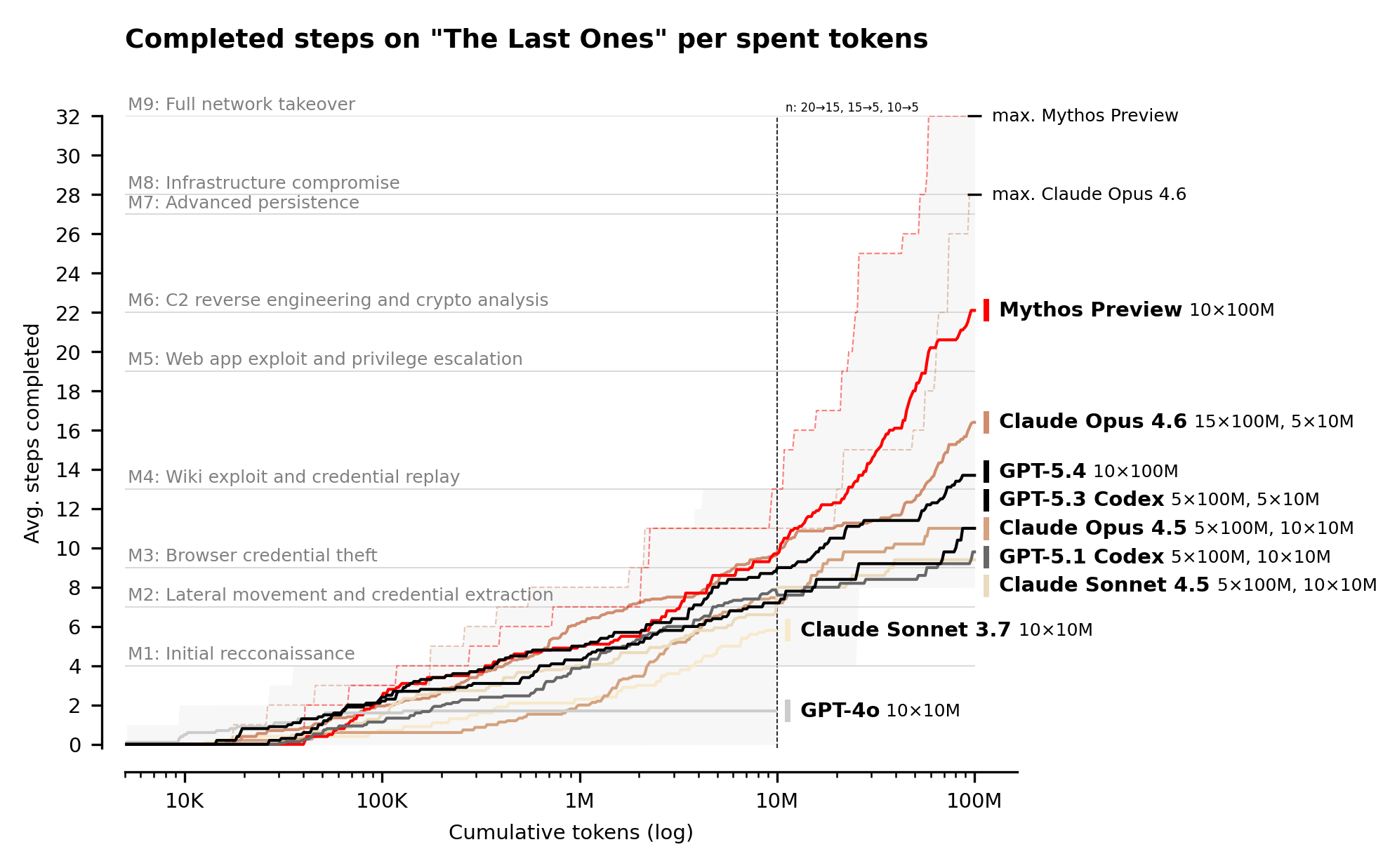
Then GPT-5.5 arrived. On expert-level tasks, GPT-5.5 achieved an average pass rate of 71.4%, compared to 68.6% for Mythos Preview, 52.4% for GPT-5.4, and 48.6% for Opus 4.7. On pass 5, GPT-5.5 scored 90.5%, making it the highest-performing model the AISI has tested by that metric. It completed TLO end-to-end in 1 of 10 attempts, and it scored 100% on all lower-difficulty cyber tasks.
The significance isn’t that one model is slightly better than another on a particular benchmark. The significance is that two frontier models from two different labs, built on different architectures and trained by different teams, have both independently demonstrated the ability to autonomously execute multi-stage attack chains spanning the full kill chain. The capability isn’t an artifact of a single training run or a single lab’s approach. It’s an emergent property of model scale, and every generation moves the bar higher.
It also demonstrates much broader cybersecurity implications than the isolated vulnerability discovery or exploitation that has largely dominated headlines and discussions. This is full kill chain, lateral movement, vulnerability chaining etc. which of course has much stronger implications for cyber than a model finding isolated vulnerabilities in a codebase. Even Anthropic in their red teams discussions of Mythos touched on topics such as vulnerability chaining as well.
This further complicates things given NVD’s collapse and teams historical activities of prioritizing vulnerabilities based on severity scores, as low and moderate findings can be chained together to increase their impact as well, despite most teams never remediating or prioritizing them.
I do also want to call out a key caveat from AISI’s research:
“However, our ranges have important differences from real-world environments that make them easier targets. They lack security features that are often present, such as active defenders and defensive tooling. There are also no penalties for the model for undertaking actions that would trigger security alerts. This means we cannot say for sure whether Mythos Preview would be able to attack well-defended systems.”
So these environments lack active defenders, security tech stacks etc. so it isn’t a perfect example of real-world environments. All of that said, it is easy to see the trajectory of AI cyber capabilities and how rapidly they are improving.
We also must acknowledge how most real-world environments are riddled with vulnerabilities, misconfigurations, disjointed security tooling that is shelfware, teams drowning in alert fatigue, most of which never gets reviewed and more, so I don’t suspect the models will struggle in reality either, given all of the challenges enterprise cyber programs face.
The Jagged Frontier
If the AISI evaluations were the only data point, you could argue this is a frontier-model problem, relevant only to the handful of organizations that can afford hundreds of millions in training compute. AISLE’s research demolishes that argument entirely, which they captured in “AI Cybersecurity After Mythos: The Jagged Frontier”, where they argued the moat is the system, not the model.
AISLE took the FreeBSD NFS vulnerability (CVE-2026-4747) that Anthropic highlighted as a flagship Mythos discovery, a 17-year-old remote code execution bug, and ran it through eight different models, including open-weights models with as few as 3.6 billion active parameters. Every single one detected the vulnerability. The smallest model, running at $0.11 per million tokens, correctly identified the stack buffer overflow, computed the remaining buffer space, and assessed it as critical with remote code execution potential. A 5.1B-active open model recovered the core chain of a 27-year-old OpenBSD bug.
AISLE calls this the “jagged frontier” of AI cybersecurity, a finding that capability rankings reshuffle completely across different security tasks and that the moat isn’t the model but the system built around it. Their production record speaks for itself: 15 CVEs in OpenSSL, 5 in curl, over 180 externally validated CVEs across 30+ projects, and they discovered 12 of 12 CVEs in the January 2026 OpenSSL coordinated release.
The implication is that vulnerability discovery at scale is no longer gated by access to frontier models. Open-weights models costing pennies per million tokens can surface the same classes of bugs that Mythos found, which means the barrier to entry for AI-augmented offensive capability isn’t compute or money. It’s orchestration, and orchestration, unlike model weights, is something anyone can build.
The Industrialization of Exploitation
Discovering vulnerabilities is one thing. Weaponizing them is another, and the data on exploitation timelines has moved past alarming into damning.
As I covered in The Industrialization of Exploitation, the gap between CVE disclosure and working exploit has collapsed from years to minutes. In 2018, median time-to-exploit sat at 771 days. By 2021, it had compressed to 84 days. By 2023, roughly 6 days. Today, 67.2% of exploited CVEs in 2026 are zero-days, weaponized before or on the day of public disclosure, up from 16.1% in 2018. I interviewed Sergej Epp, the creator of the Zero Day Clock to dig into this all as well.
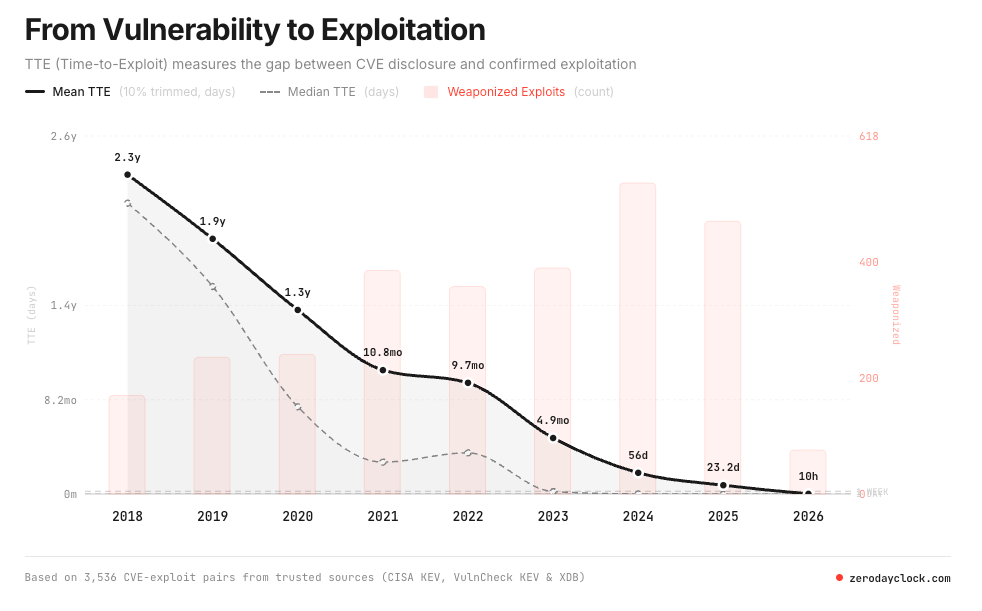
MOAK (Mother of All KEVs), the agentic exploit workflow built by Niv Hoffman and Yair Saban, demonstrated this in practice. Using a five-agent architecture that mirrors real offensive operations (Collector, Researcher, Builder, Exploiter, and Judge), MOAK autonomously exploited 174 out of 178 known exploited vulnerabilities published after the models’ knowledge cutoffs. It exploited a React-to-shell vulnerability in 21 minutes with no human in the loop. The underlying models, Claude Opus 4.6 and GPT 5.4, are available to anyone with an API key and show autonomous exploitation rates around 80% against real-world KEVs. I sat down with Niv and Yair to discuss what they built and the broader industrialization of exploitation via AI:
The Zero Day Clock data reinforces the trend. The 1-day and 1-hour exploitation marks are projected for 2026, with the 1-minute mark projected for 2028. Sean Heelan built AI agents that generated over 40 working exploits for a single flaw for $50 and discussed it in his article “on the coming industrialization of exploit generation with LLMs”.
Yaron Dinkin and Eyal Kraft unleashed AI agent swarms on Windows kernel drivers and found over 100 exploitable vulnerabilities across AMD, Intel, NVIDIA, Dell, Lenovo, and IBM in 30 days for $600 total, which works out to $4 per bug.
When two-thirds of exploited vulnerabilities are weaponized before or on the day of disclosure, the entire model of reactive security has already failed. Find it, disclose it, patch it, deploy it isn’t a viable strategy when the exploitation timeline has collapsed below the detection and response timeline.
The Attack Surface Keeps Growing
The offensive capability acceleration would be concerning enough in isolation. But it’s hitting an environment where the attack surface is expanding at rates that make historical comparisons meaningless.
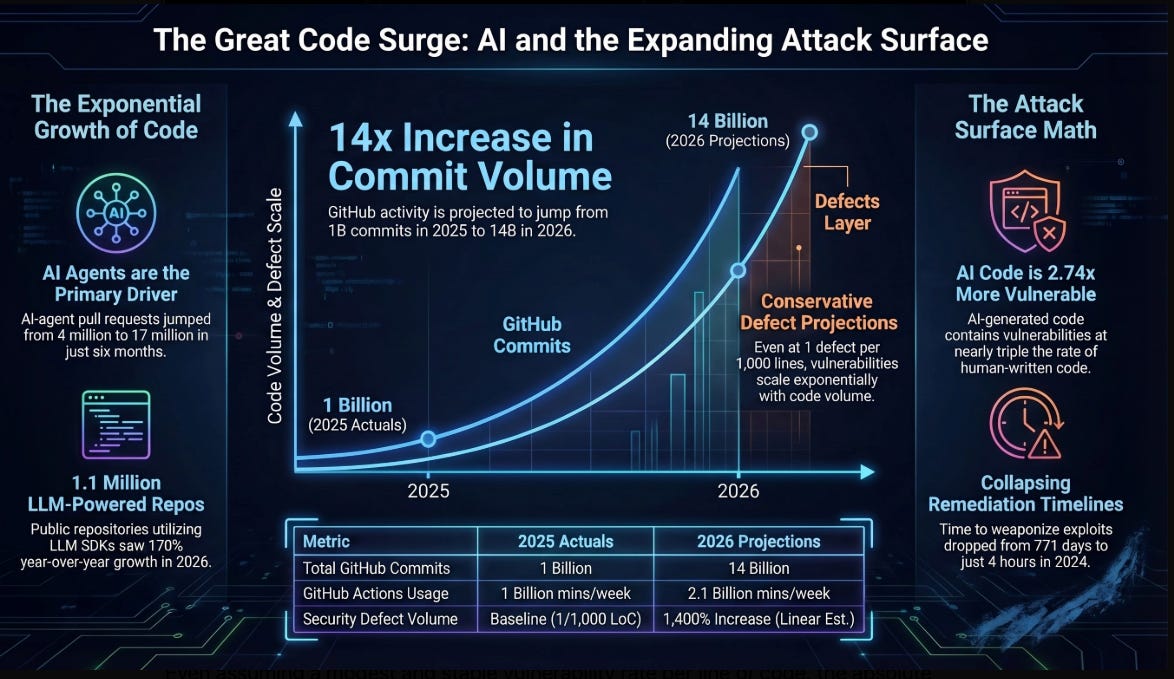
As I laid out in The Attack Surface Exponential, GitHub hit 1 billion commits in 2025 and is now processing 275 million commits per week, putting the platform on pace for 14 billion commits in 2026, a 14x year-over-year increase driven almost entirely by AI coding agents.
FIRST’s 2026 Vulnerability Forecast projects a median of approximately 59,000 new CVEs this year, marking the first time the industry will cross 50,000 published CVEs in a single calendar year. And much of the new code is being produced by developers who are less security-conscious than experienced practitioners, with elevated vulnerability density as a predictable consequence.
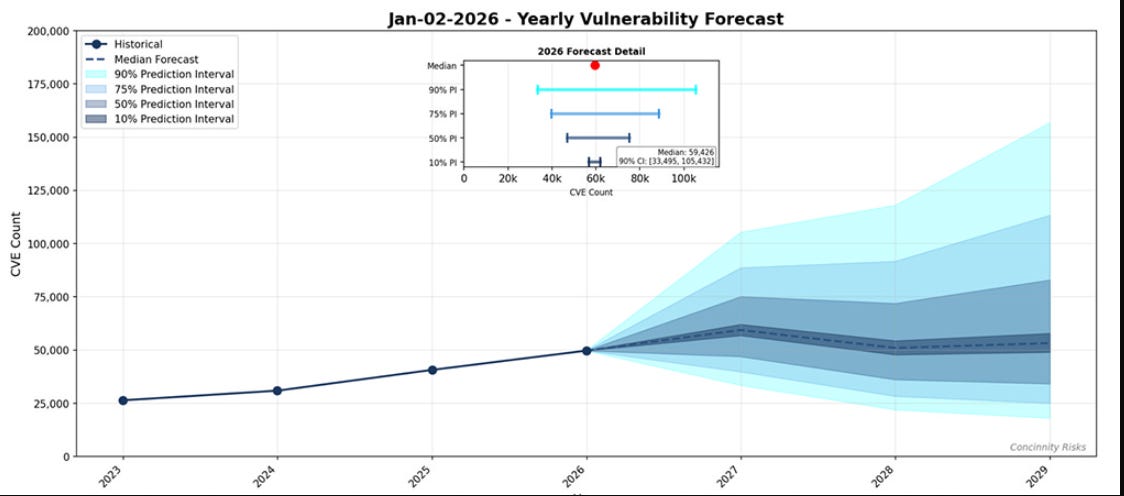
The code is now being produced faster than security teams can review it. The attack surface is no longer something organizations can fully inventory, let alone fully secure, and the systems that defenders rely on to make sense of this growing volume are themselves buckling under the pressure.
The Defender’s Infrastructure Is Collapsing
This is where the defender’s dilemma becomes even more systemic. The National Vulnerability Database, which most enterprise vulnerability management programs depend on for enrichment data, has effectively capitulated. As I covered in The NVD Just Threw In The Towel, NIST moved approximately 29,000 backlogged CVEs into a “Not Scheduled” category, clearing the visible backlog from over 33,000 to roughly 4,000 by reclassifying the problem rather than solving it. CVE submissions increased 263% between 2020 and 2025, and the first three months of 2026 are running nearly one-third higher than the same period last year. NIST enriched 42,000 CVEs in 2025, 45% more than any previous record, and still fell behind.
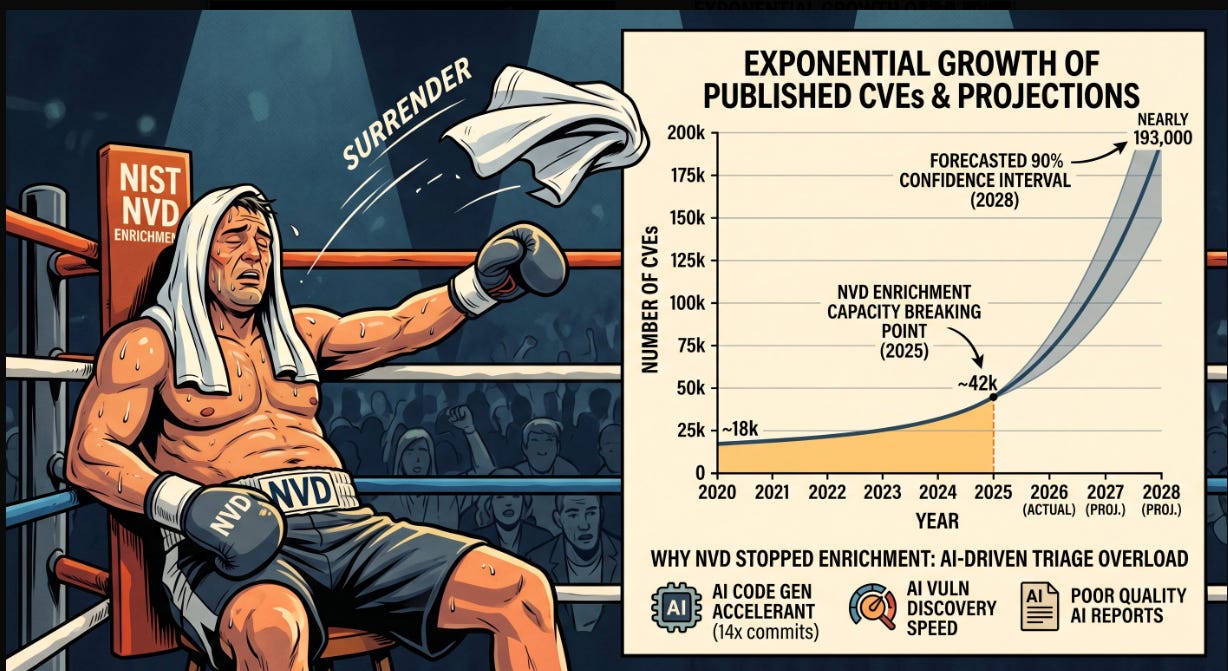
Going forward, the NVD will only prioritize CVEs in the CISA KEV catalog, CVEs affecting federal government software, and CVEs tied to critical software under Executive Order 14028. Everything else is effectively on its own. For the thousands of organizations that built their vulnerability management workflows around the assumption that the NVD would provide timely, comprehensive enrichment data, this is a foundational assumption that no longer holds.
Bug bounty programs are hitting the same wall from the demand side. HackerOne’s Internet Bug Bounty program paused accepting new vulnerability submissions in March 2026 because of a worsening imbalance between discovery volume and remediation capacity. HackerOne reported valid AI vulnerability reports up 210%, with autonomous agents submitting 560+ valid reports. 70% of surveyed researchers now use AI tools in their workflow. The bottleneck has shifted permanently, discovery has been industrialized, but the human and organizational capacity to triage, prioritize, and remediate has not scaled at all.
The Full Kill Chain Problem
This is the thread that connects the AISI evaluations back to the practical reality of enterprise defense. The conversation about AI cyber capabilities has mostly focused on vulnerability discovery, which is important but incomplete. What the AISI’s TLO benchmark demonstrates is something qualitatively different. These models aren’t just finding bugs, they’re executing complete attack chains, autonomously moving from initial reconnaissance through exploitation, privilege escalation, lateral movement across subnets, and objective completion.
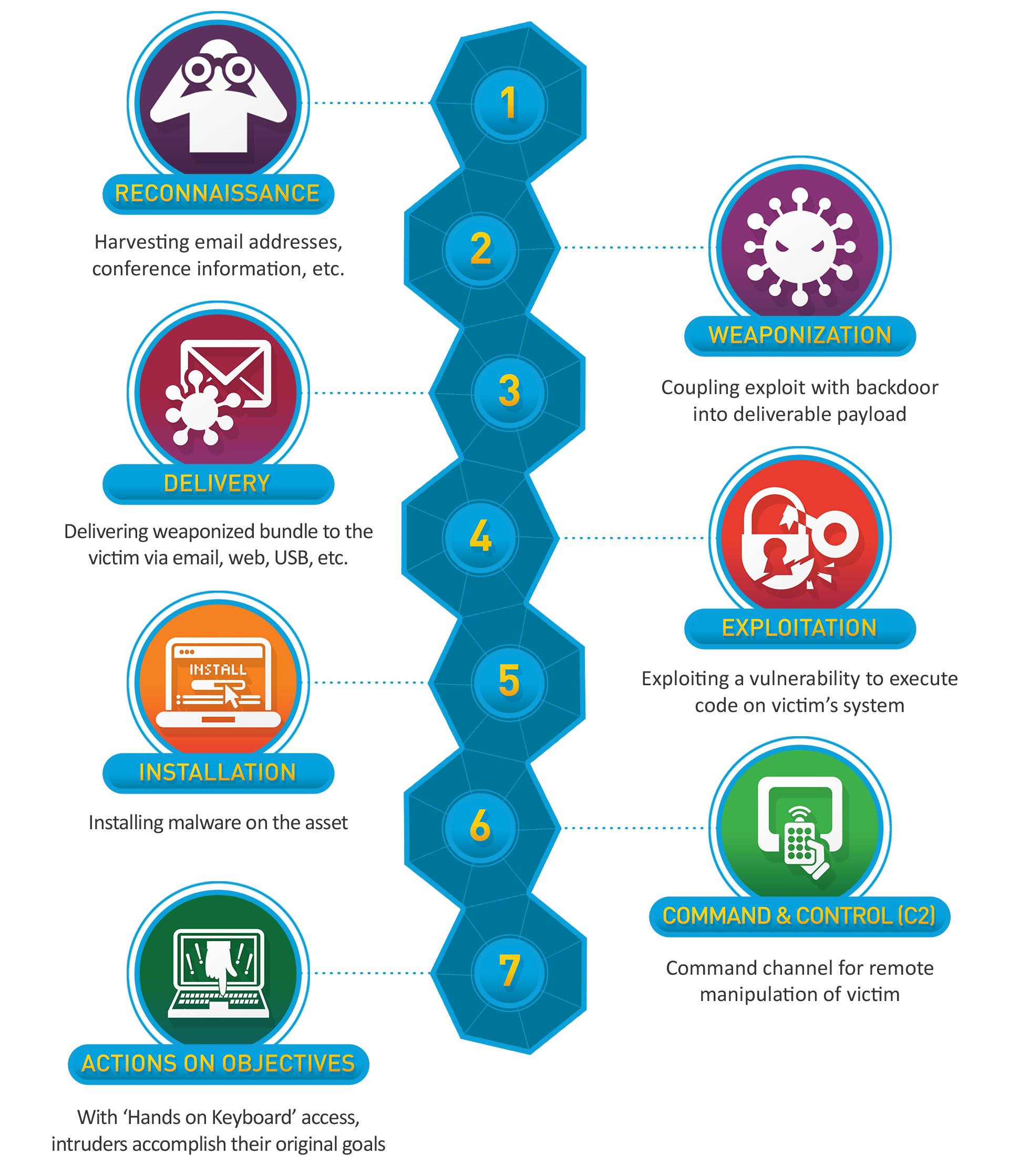
That’s the full kill chain, executed without human intervention, against a simulated but realistic corporate network environment. The AISI’s evaluation ranges lack live defenders, endpoint detection, and real-time incident response, which means these results establish capability against weakly defended systems rather than hardened enterprise networks. But the trajectory matters more than the current constraint. Claude Opus 4.6 averaged 16 out of 32 TLO steps. Mythos Preview averaged 22 and completed it 3 times out of 10. GPT-5.5 completed it once. Each model generation pushes further along the chain, and each generation arrives faster than the last.
Former CISA Director Jen Easterly published an essay arguing that Anthropic’s Mythos announcement marks a fundamental inflection point for the cybersecurity profession, noting that AI-driven vulnerability discovery at this capability level changes the economics of attack and defense so profoundly that the traditional model, built on perimeter defense, human-speed patching, and reactive incident response, cannot survive in its current form. The AISI evaluations, AISLE’s research, MOAK’s exploitation data, and the NVD’s capitulation all point to the same structural conclusion.
What This Means for Defenders
The defenders’ dilemma has always been asymmetric, attackers need one path in while defenders need to protect every path. AI is compressing the attacker’s side of that asymmetry at exponential rates while the defender’s side remains constrained by organizational complexity, legacy architecture, change management processes, and the sheer human bottleneck of triage and remediation.
Vulnerability backlogs already number in the hundreds of thousands for large enterprises, with remediation rates sitting at roughly 10% per month and an average of 20 days to deploy a patch. When the exploitation timeline is measured in hours and the remediation timeline is measured in weeks, no amount of “patch faster” rhetoric changes the underlying math. As Simon Goldsmith argued in the context of Vulnpocalypse, the industry is running the wrong race by obsessing over discovery speed when the real bottleneck is remediation capacity.
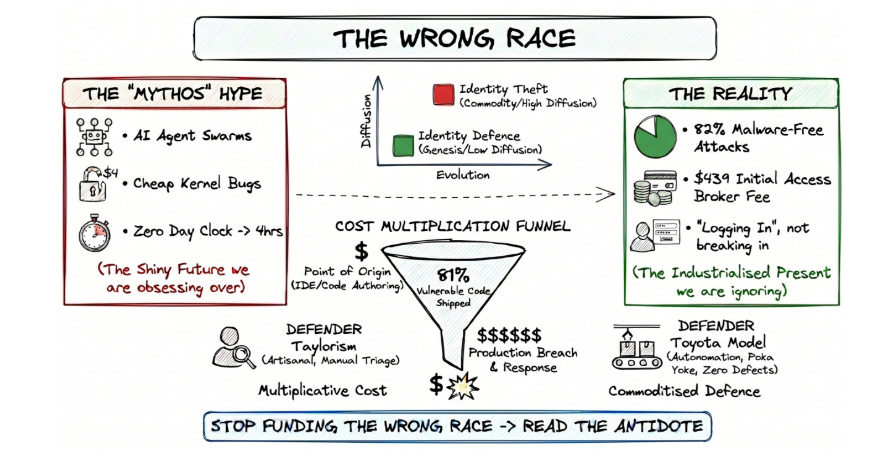
The models are going to keep getting better. The AISI will evaluate the next frontier release, and the pass rates will be higher and the TLO completion rates will climb. AISLE and its open-source equivalents will keep demonstrating that you don’t need frontier-scale compute to find critical bugs. MOAK and its successors will keep compressing exploitation timelines. The NVD won’t suddenly scale to 59,000+ CVEs per year. Bug bounty programs won’t solve the remediation bottleneck by pausing submissions.
The capability curve isn’t flattening. If anything, it’s steepening with every model generation and every research paper that shows smaller, cheaper models can replicate what the frontier labs demonstrated.
There is absolutely no question that AI has fundamental transformed the threat model. The question is whether the industry’s defensive infrastructure, its vulnerability management pipelines, its patching cadences, its enrichment databases, and its organizational remediation capacity, can evolve fast enough to remain relevant against an adversary that doesn’t sleep, doesn’t context-switch, and gets materially better every quarter.
An attacker now needs an API key and an afternoon. A defender still needs a quarter and a steering committee and that gap isn't closing, it’s now the name of the game moving forward.
In my view, there is only one solution.
The entire software industry needs to start producing AI expert-system - NOT LLM - designed and generated systems - starting with the operating system.
In other words, the software "engineering" profession needs to recognize that it is NOT "engineering", but a craft profession - and automate itself out of existence.
I've been saying this for decades.
Of course, it won't be done. A lot of band-aids will be applied to try to remediate the problem instead.