
The NVD Just Threw In The Towel - Now What?

A little over a year ago, I wrote Death Knell of the NVD and even broke down the NVD chaos with Josh Bressers and Dan Lorenc:
The point was, the NIST National Vulnerability Database (NVD) was structurally incapable of keeping pace with the volume and velocity of modern vulnerability disclosures. It was underfunded, understaffed, and operating on a model designed for a world that no longer exists. The backlog was growing, the enrichment pipeline was breaking down, and the industry was placing its trust in a system that could not deliver on the promise of being the authoritative source of vulnerability intelligence.
The NVD was (and still is) dealing with a variety of challenges such as legacy manual processes, contractual hurdles, funding constraints, technical bottlenecks and an ever growing flow of CVE’s.
At the time, some people thought I was being dramatic, I was not. NVD’s problems have only persisted since then, and now seem to have come to a head.

(Image credit to my friend Patrick Garrity)
Interested in sponsoring an issue of Resilient Cyber?
This includes reaching over 31,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives
Reach out below!
NIST Makes It Official
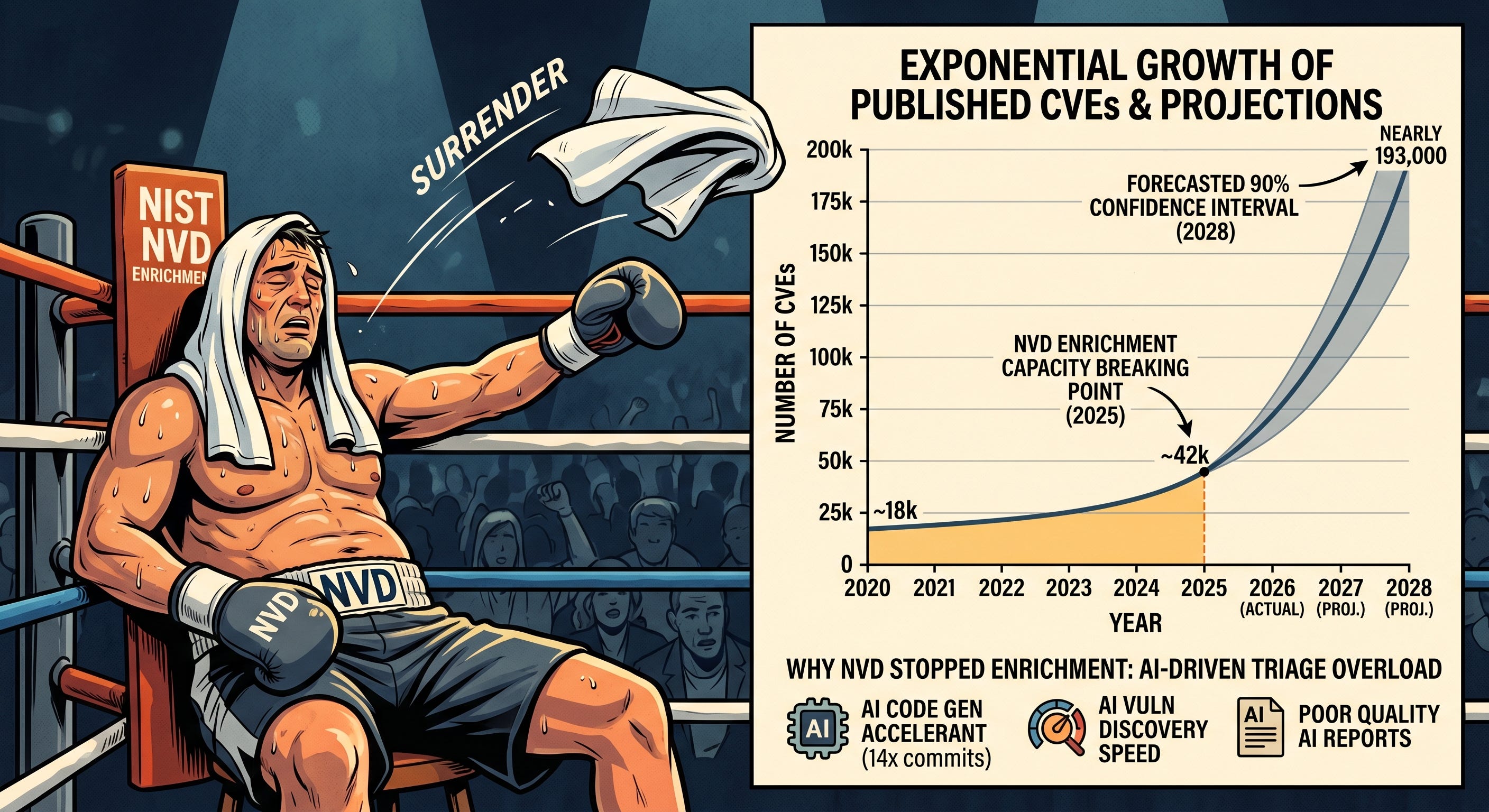
On April 15, 2026, NIST made it official.

The NVD is shifting to a risk-based enrichment model, which is a polite way of saying they are no longer going to enrich most CVEs.
Going forward, NIST will only enrich:
CVEs appearing in CISA’s Known Exploited Vulnerabilities (KEV) Catalog
CVEs for software used within the federal government (assuming the Federal government knows what software they are using - hint: they don’t!)
CVEs for critical software as defined by Executive Order 14028
Everything else gets categorized as “Lowest Priority, not scheduled for immediate enrichment.” And approximately 29,000 backlogged CVEs with publish dates before March 1, 2026 were moved into the “Not Scheduled” category, effectively clearing the visible backlog from over 33,000 to roughly 4,000 by reclassifying the problem rather than solving it.
This change has strong implications for the cybersecurity ecosystem. The system the entire cybersecurity industry has depended on for vulnerability scoring, enrichment, and metadata is formally acknowledging that it cannot keep up.
NVD discusses the exponential growth that is leading to the challenges for them. It enriched nearly 42,000 CVEs in 2025, which was 45% more than any prior year, and it still was not enough. CVE submissions increased 263% between 2020 and 2025, and the first three months of 2026 are running nearly one-third higher than the same period last year. The NVD did not fail because of negligence. It failed because the inputs grew faster than any government-funded program could scale to meet them.
This bolsters the case where many have been arguing that this activity is better served by the private sector. I’m not sure I share that view, but when the leading Federal program for vulnerability intelligence and enrichment throws up their hand in fatigue, it is hard to argue otherwise.
The Numbers Behind the Collapse
To understand why this was inevitable, you have to look at the trajectory.
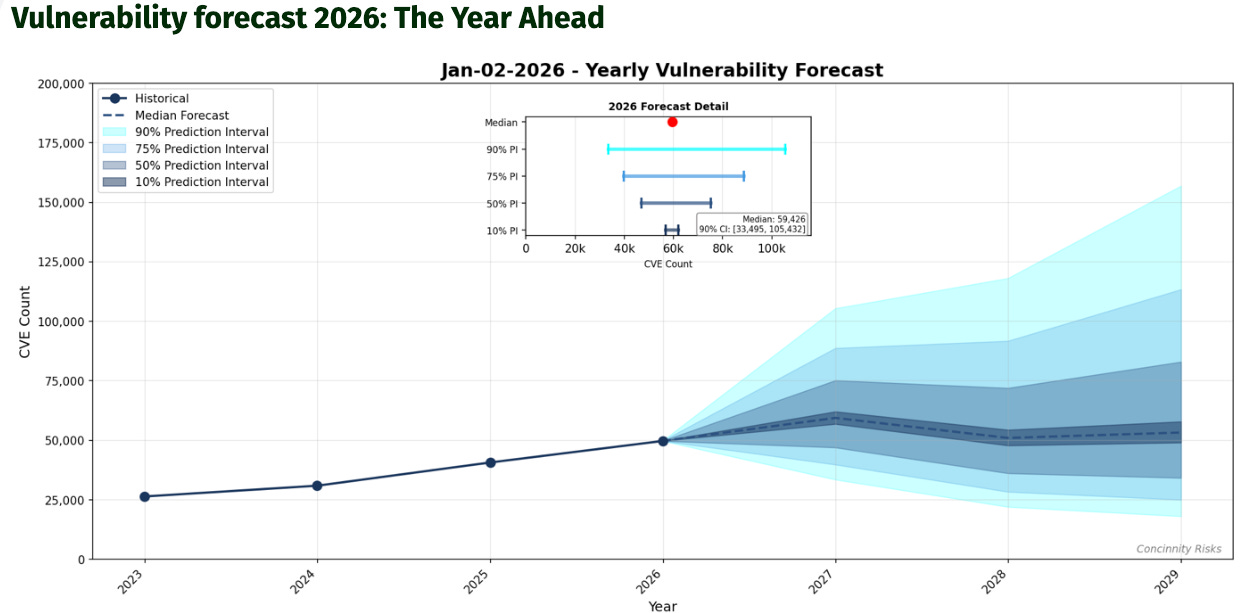
FIRST’s 2026 Vulnerability Forecast projected a median of approximately 59,000 new CVEs this year, marking the first time the industry will cross 50,000 published CVEs in a single calendar year. Their realistic upside scenarios suggest 70,000 to 100,000 are entirely possible, with the upper bound of the 90% confidence interval approaching 118,000, and this is not a one-year spike. FIRST projects the median will hold above 50,000 through 2028, with upper bounds reaching nearly 193,000 by then.
GitHub’s analysis of open source vulnerability trends confirms the acceleration from the ecosystem perspective. They saw a 35% increase in published CVE records in 2025, outpacing the overall CVE Program’s increase of 21%, with 10 to 16% growth every quarter. If that trend continues, GitHub will publish over 50% more CVEs in 2026 than they did in 2025. Their malware advisory numbers are even more striking. NPM malware advisories surged 69% year over year in 2025, the highest volume since GitHub added malware tracking in 2022, driven by large-scale campaigns exploiting the trust model of public package registries.
This is evident from not only years of open source supply chain incidents, but a series of high profile open source compromises in early 2026 year that have dominated security discussions and news.
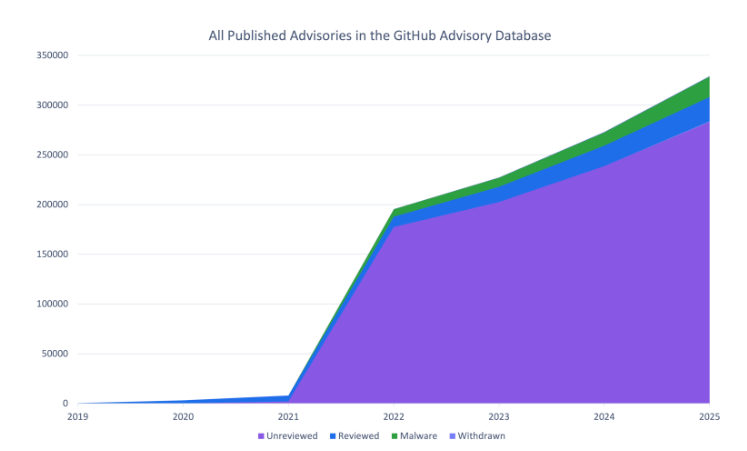
These are not edge cases, this is the baseline, and the baseline is accelerating.
AI Is the Accelerant the System Was Not Built For
What pushed the NVD past its breaking point is not just organic growth in software complexity. It is the convergence of AI-driven code generation, AI-driven vulnerability discovery, and AI-driven vulnerability reporting, all hitting the system simultaneously.
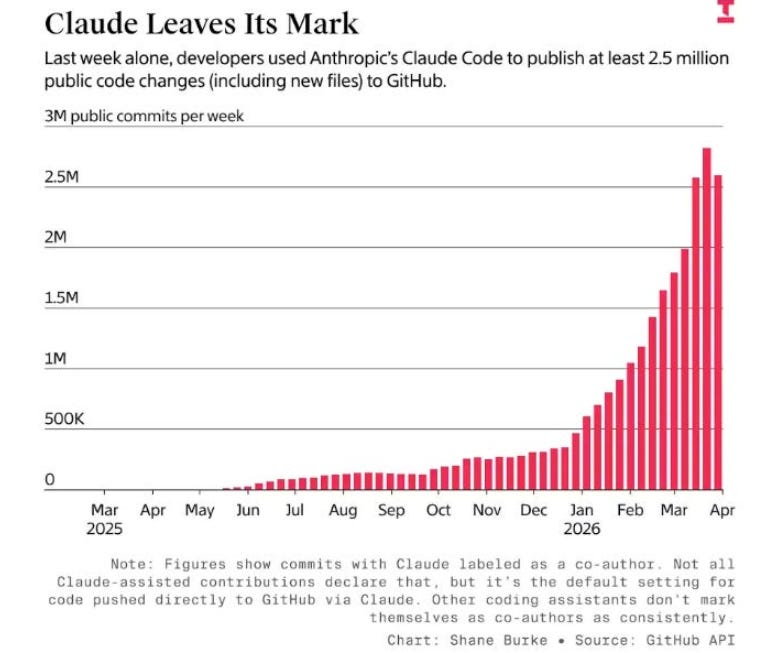
On the code generation side, as I detailed in The Attack Surface Exponential, GitHub hit 1 billion commits in 2025 and is now processing 275 million commits per week, putting the platform on pace for 14 billion commits in 2026. That is a 14x year-over-year increase, driven almost entirely by AI coding agents. Every one of those commits is pulling open source dependencies, introducing new code paths, and expanding the attack surface that the vulnerability ecosystem needs to catalog, score, and enrich.
On the discovery side, as I covered in both Vulnpocalypse and Claude Mythos: Why It Matters, AI systems are now finding vulnerabilities at machine speed. Anthropic’s Claude Mythos Preview found thousands of high-severity vulnerabilities including a 27-year-old bug in OpenBSD. AISLE discovered all 12 CVEs in a coordinated OpenSSL release. MOAK demonstrated automated exploitation of hundreds of known dangerous vulnerabilities in minutes.
The cost of finding a vulnerability is approaching zero, however the cost of enriching it in the NVD is not. This creates an economic mismatch between the two activities.
And then there is the reporting side, which may be the most immediate driver of the NVD’s capitulation. FIRST CEO Chris Gibson noted in a recent interview that AI is clearly another tool in the armory for finding vulnerabilities and probably a game changer in many ways. But he also raised a critical question about whether the vulnerability disclosure infrastructure is ready for what is coming, and it is safe to say it is not.

As GitHub’s Madison Oliver noted on LinkedIn, the quality of CVE submissions has become a significant concern alongside the volume. AI-generated vulnerability reports are flooding the system, and many of them are low quality, duplicative, or lack the context necessary for meaningful enrichment.
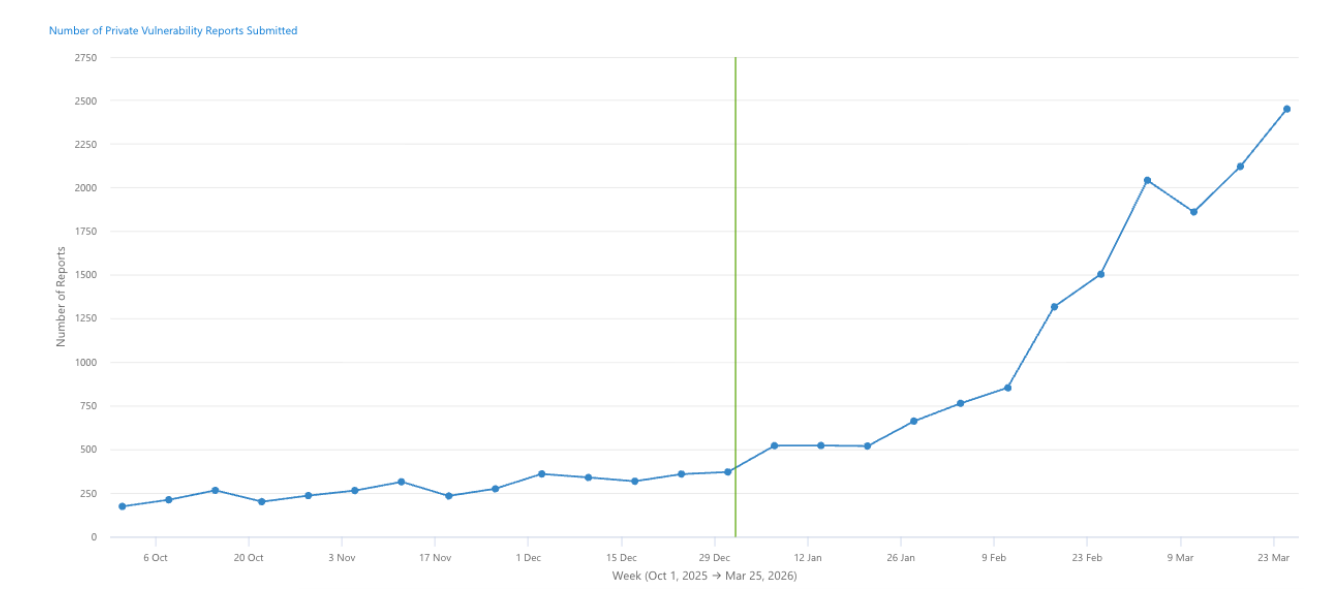
GitHub reported that the number of vulnerability reports received over the past 90 days was 224% higher than the previous 90 days, with report quality described as a “huge concern.” The CVE system was designed for a world where human security researchers carefully documented vulnerabilities with detailed technical write-ups. It is now receiving machine-generated reports at a volume and pace that overwhelms the human reviewers responsible for enrichment.
This is the triple squeeze we see unfolding. More code generating more vulnerabilities, AI discovering those vulnerabilities faster than humans can process them, and AI-generated reports flooding the intake pipeline with volume that outstrips the system’s capacity to validate and enrich.
If we’re being honest, the NVD never stood a chance under these circumstances.
The Enrichment Gap and What It Means
The practical impact of NIST’s announcement is that the majority of CVEs will now exist in the NVD as shells. They will have an identifier and whatever information the CNA (CVE Numbering Authority) provided at submission, but they will not have the CVSS scores, CPE (Common Platform Enumeration) data, CWE classifications, or reference metadata that security teams and vulnerability management tools depend on to prioritize and remediate.
This matters because the entire vulnerability management workflow in most organizations starts with the NVD. Scanners pull CVE data from the NVD, risk scoring engines use CVSS from the NVD, compliance frameworks reference NVD enrichment data, and patch management prioritization relies on the metadata the NVD provides.
When that enrichment goes away for the majority of CVEs, the downstream tooling does not automatically compensate. Organizations that have built their vulnerability management programs around NVD data (which is most of the ecosystem) as the authoritative source are now operating on a foundation that has formally declared it will no longer serve most of the vulnerabilities being disclosed.
The request-by-email process NIST outlined for getting lowest-priority CVEs enriched is not a scalable alternative. If your organization identifies a CVE in your environment that NIST has categorized as lowest priority, you can email nvd@nist.gov and ask them to schedule it for enrichment.
That is an analog process in an exponential era - it simply can’t scale.
For an industry dealing with tens of thousands of new CVEs per year across complex software supply chains, the idea that emailing NIST is a viable path to getting the vulnerability metadata you need is not a real solution. It is an acknowledgment that no real solution exists within the current model.
The Market Was Already Moving
The reality is that organizations that were solely dependent on the NVD were already behind. The smartest security teams had already started supplementing NVD data with alternative enrichment sources, commercial vulnerability intelligence feeds, exploit prediction scoring like EPSS, and vendor-specific advisory databases.
CISA’s KEV catalog had already become the de facto prioritization signal for many teams, which is effectively what NIST’s new model codifies. If it is not in KEV, it is not getting enriched. Even then, many, such as my friend Patrick Garrity and his team at VulnCheck have demonstrated how much active exploitation activity the CISA KEV misses as well, and provide their own VulnCheck KEV. It includes 80% more CVE’s that are exploited in the wild that CISA’s KEV misses.
But this shift also exposes a deeper structural problem. The CVE system itself is under strain. Gibson noted at VulnCon 2026 that he would be surprised if Anthropic and OpenAI were not CVE Numbering Authorities by the end of 2026.

The fact that frontier AI labs are expected to become CNAs tells you where the volume is heading. CISA has indicated that AI companies need to play a bigger role in the CVE program, which is an implicit acknowledgment that the current participant base cannot handle the AI-driven vulnerability volume alone. It also makes sense, given the labs movement into AppSec with native capabilities, vulnerability discovery and broader engagement of the community.
ENISA announcing it is working with CISA and MITRE on the CVE program and becoming a Top-Level Root CNA is another signal. The program is internationalizing and distributing authority because no single entity can manage the scale. This is not necessarily a sign of strength. It is a sign of an infrastructure being stress-tested to its limits and responding by spreading the load rather than increasing capacity at the center. This could lead to more resilience and robust capabilities, but it could also lead to dysfunctional and decentralization.
From CVE Counting to Risk-Based Prioritization
So we’ve walked through where we are, and why we’re here. I wanted to share some thoughts I think security leaders need to internalize from this moment moving forward.
The era of CVE-centric vulnerability management is over. Not because CVEs do not matter, but because the system that was supposed to make them actionable has formally announced it cannot do so for the majority of vulnerabilities being disclosed and the trajectory of the ecosystem, being driven by factors such as AI is straining a system that was built prior to our AI-driven exponential.
This does not mean you stop tracking CVEs. It means you stop treating the NVD as your primary enrichment source and start building a vulnerability management program that can function without it.
That means investing in commercial vulnerability intelligence that provides enrichment independent of NIST. It means adopting risk-based prioritization models that incorporate exploitability (EPSS, KEV), reachability analysis, business context, and asset criticality rather than relying on CVSS scores that may never materialize for most CVEs. It means treating the NVD as one signal among many rather than the authoritative foundation of your program.
It also means confronting the compliance implications. Many regulatory frameworks and security standards reference the NVD explicitly or implicitly as the standard for vulnerability identification and scoring.
If NIST is no longer enriching most CVEs, what does that mean for organizations that are contractually or regulatory required to demonstrate they are managing known vulnerabilities? The compliance frameworks have not caught up to this reality, and until they do, security teams will be caught in a gap between what the frameworks require and what the NVD can deliver.
That said, prioritization is far from a silver bullet, and as we have discussed, you will be missing a large portion of the data traditionally used to inform it anyways. To take a more comprehensive approach, I defintiely recommend checking out an excellent recent piece from my friend James Berthoty titled “Building AN AI Ready Vulnerability Management Program After NVD Changes and Claude Mythos". In the article, James walks through some sound recommendations ranging from fundamental inventory and visibility through cloud application detection and response (CADR), runtime enforcement and more.
The Bigger Picture
I want to zoom out for a moment and connect this to the broader trajectory I have been writing about across several pieces.
In Vulnpocalypse, I argued that AI-accelerated vulnerability discovery would overwhelm the industry’s capacity to respond. In The Attack Surface Exponential, I laid out the math behind code volume growing at 14x year over year and what that means for the absolute number of vulnerabilities entering production. In Claude Mythos: Why It Matters, I discussed how frontier models are finding bugs that evaded human researchers for decades.
The NVD announcement is the first institutional domino to fall as a direct result of those converging trends. The system that was supposed to catalog and enrich the world’s vulnerabilities just told us it cannot do so anymore. Not temporarily, not as a budget issue that gets resolved in the next fiscal year, but as a structural reality of the volume and velocity of modern vulnerability disclosure being driven by AI.
FIRST is projecting 59,000 CVEs this year with realistic upside scenarios approaching 100,000. GitHub is tracking 35% year-over-year growth in CVE publishing with malware advisories up 69%. AI agents are producing 275 million commits a week on GitHub alone, and the cost of discovering vulnerabilities in all of that code is collapsing toward zero while the infrastructure to process them remains bounded by human capacity and government funding cycles.
The NVD was the canary in the coal mine, and it just stopped singing.

What remains to be seen is whether the rest of the industry’s vulnerability management infrastructure adapts to this reality or continues operating as if the old model still works.
Because NIST just told us, in plain language, that it does not.