
The Human-in-the-Loop Illusion
Why HITL is Not a Security Control and Why Auto Mode Matters More Than You Think

Anthropic just acknowledged what practitioners have been sensing for months. Users approve 93% of Claude Code permission prompts, and approval fatigue means many of those approvals are not meaningful reviews. So what happens when we finally stop pretending the human-in-the-loop is functioning as designed?
Anthropic recently launched Auto Mode for Claude Code, and it sparked one of the most important conversations in agentic AI security this year. Not because of what Auto Mode does, but because of what it admits. According to Anthropic’s own data, users approve 93% of Claude Code permission prompts. Anthropic describes this as leading to “approval fatigue, where people stop paying close attention to what they’re approving.” The human-in-the-loop is not functioning as a meaningful safety control. It is a formality that users power through to maintain their workflow.
This is not just an Anthropic problem. This is an industry-wide reckoning with a foundational assumption that has underpinned agentic AI safety from the beginning.
The assumption that a human will be present, paying attention, and making informed decisions about what an agent should and should not do. The data suggests otherwise, and the implications for enterprise security are significant.
Even my friend Steve Wilson, head of OWASP’s LLM Top 10 called out this fantasy during my panel at OWASP’s Agentic Security Initiative (ASI) event recently when we were on stage.

Interested in sponsoring an issue of Resilient Cyber?
This includes reaching over 31,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives
Reach out below!
What Auto Mode Actually Is
Claude Code Auto Mode is a new permissions mode that delegates approval decisions to a model-based classifier rather than requiring the user to approve every file write, shell command, and external operation.
It uses a two-layer defense system. At the input layer, a server-side prompt injection probe scans tool outputs before the agent processes them, flagging content that looks like an attempt to hijack the agent’s behavior. At the output layer, a transcript classifier running on Sonnet 4.6 evaluates each action against a set of decision criteria before it executes.
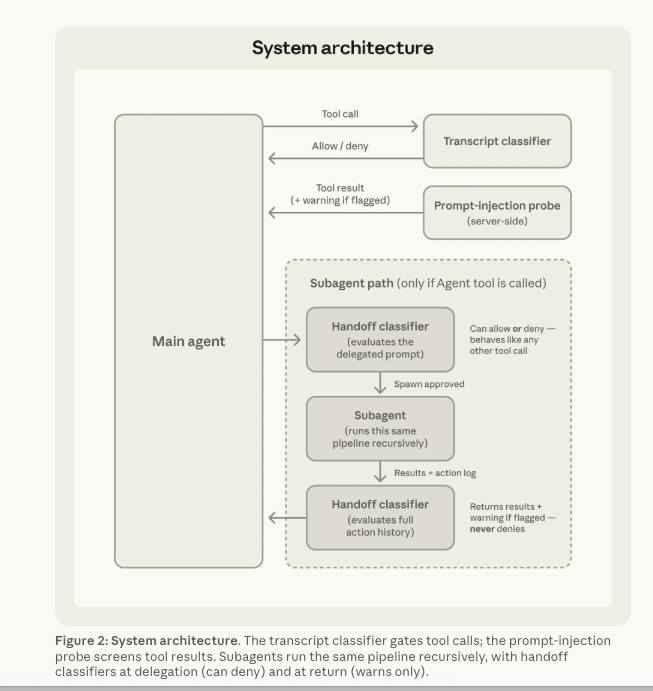
The classifier operates in two stages. A fast single-token filter runs first, tuned to block aggressively. If the first stage flags an action, a chain-of-thought reasoning step follows to reduce false positives. The classifier receives user messages and tool calls as input, but assistant text and tool results are stripped out. This is an intentional design choice. Because tool results never reach the classifier, hostile content embedded in files, web pages, or tool outputs cannot directly manipulate the classifier’s decisions.
The system hard-blocks actions like piping curl output to bash, production deployments, destructive shared-infrastructure changes, and force-pushing to main. Anthropic maintains an internal incident log of real-world agentic misbehaviors, including deleting remote git branches from vague instructions, uploading an engineer’s GitHub auth token to an internal compute cluster, and attempting migrations against a production database. Auto Mode is designed to catch exactly these kinds of overeager and potentially destructive actions.

On Anthropic’s own benchmarks, the full pipeline produces a 0.4% false-positive rate on real traffic and a 17% false-negative rate on real overeager actions. That 17% miss rate is important. It means roughly one in six genuinely dangerous actions still gets through. Anthropic is transparent about this, noting that Auto Mode is “not a drop-in replacement for careful human review on high-stakes infrastructure.”
The Data on How Humans Actually Interact with Agent Permissions
What makes Auto Mode significant is not just the technology. It is the context that prompted it. Anthropic published separate research titled “Measuring AI Agent Autonomy in Practice,” analyzing millions of interactions across Claude Code and their API. The findings paint a detailed picture of how humans actually interact with agent permissions, and it is more nuanced than a simple “nobody reviews anything” narrative.
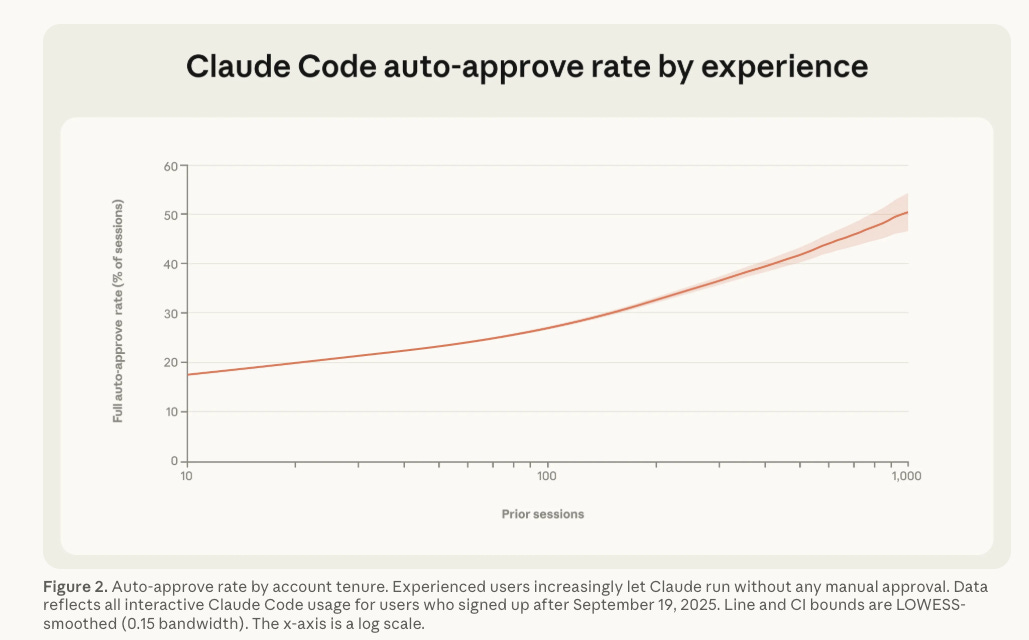
The 93% approval rate is the headline number, but the behavioral patterns underneath it are what matter most. New users with fewer than 50 sessions employ full auto-approve roughly 20% of the time. By 750 sessions, that number climbs to over 40%. Anthropic describes this as a “steady accumulation of trust.” Autonomous session durations have also grown significantly, with the 99.9th percentile turn duration nearly doubling over three months, from under 25 minutes to over 45 minutes.
Here is where the data gets genuinely interesting. Experienced users auto-approve more frequently but also interrupt more often. New users approve individual actions before they execute and rarely need to intervene, interrupting in roughly 5% of turns. Experienced users let the agent run autonomously and step in when something goes wrong, interrupting in roughly 9% of turns. This is not recklessness, it is a deliberate shift in oversight strategy, from proactive review of each action to reactive monitoring and intervention, and on the most complex tasks, the agent stops to ask for clarification more than twice as often as the human interrupts it.
Anthropic’s own researchers draw a meaningful conclusion from this data. They argue that oversight requirements that prescribe specific interaction patterns, such as requiring humans to approve every action, “will create friction without necessarily producing safety benefits.” The focus, they suggest, should be on whether humans are in a position to effectively monitor and intervene, rather than on requiring particular forms of involvement.
This aligns with what I have been arguing in my writing on agentic AI governance. In “Governing Agentic AI,” I made the case that existing governance frameworks were built for a world where humans are in the loop at every decision point.
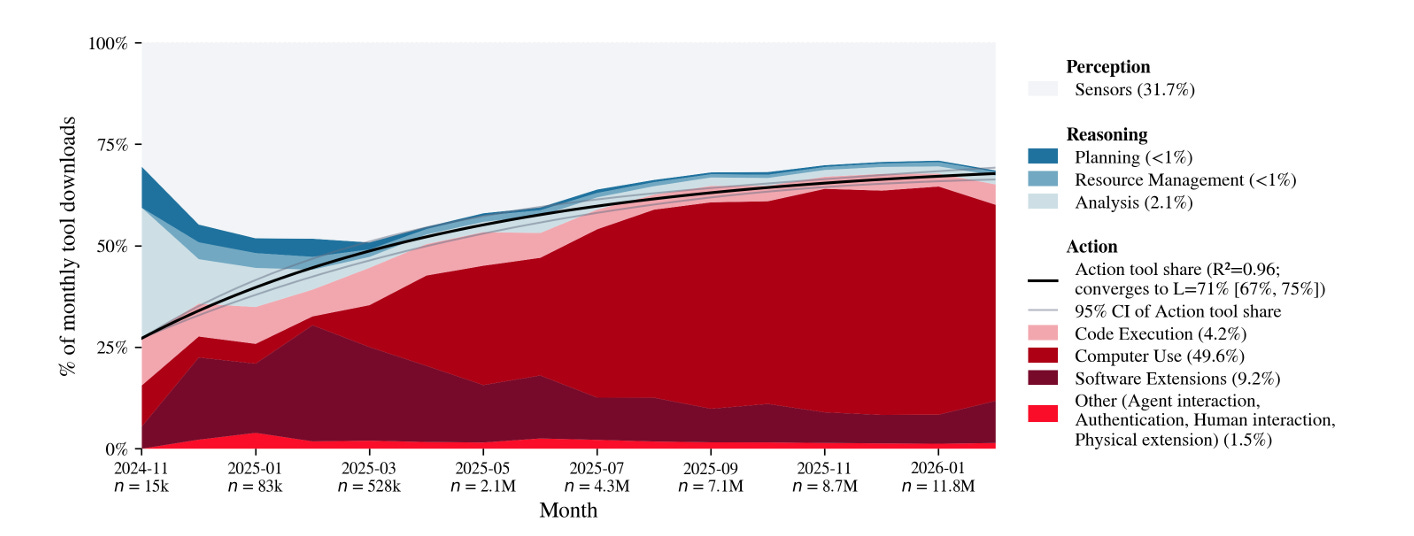
The Anthropic data suggests that even when the product is designed to require per-action approval, users naturally migrate toward a monitoring-and-intervention model. The UK AISI paper “How are AI agents used?” reinforces this broader trend with data showing that action tools grew from 27% to 65% of total agent tool usage in just 16 months. Agents are doing more, and human interaction patterns are evolving in response.
Simon Willison’s Critique and the Determinism Question
Simon Willison, one of the most thoughtful voices in the developer community on AI security, published a detailed analysis of Auto Mode that raised important concerns. His core argument is that he remains unconvinced by prompt injection protections that rely on AI, since they are non-deterministic by nature. This is not a dismissal, it is a fundamental architectural concern.
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature.
Willison’s point is that a classifier-based safety system, no matter how well-designed, introduces probabilistic behavior into a security boundary. Traditional security controls are deterministic. A firewall rule either blocks traffic or it does not. A file permission either grants access or it does not. An AI classifier that makes judgment calls about whether an action is safe introduces a category of uncertainty that does not exist in traditional security architecture. The 17% miss rate on overeager actions is a concrete example of this non-determinism in practice.
Willison also flagged a specific practical concern. The default allow list includes pip install -r requirements.txt, which means Auto Mode would not block supply chain attacks through compromised dependencies. He referenced the LiteLLM incident, where compromised packages were downloaded nearly 47,000 times during the 46 minutes they were live on PyPI, with 88% of dependent packages not pinning versions in a way that would have prevented the exploit. When your safety classifier auto-approves dependency installation and the supply chain is compromised, the classifier is irrelevant.
Willison’s preferred alternative is OS-level sandboxing that restricts file access and network connections deterministically. He trusts that approach far more than prompt-based protections. This is a legitimate position, and it reflects a broader tension in the industry between AI-based safety mechanisms and traditional infrastructure-level controls.
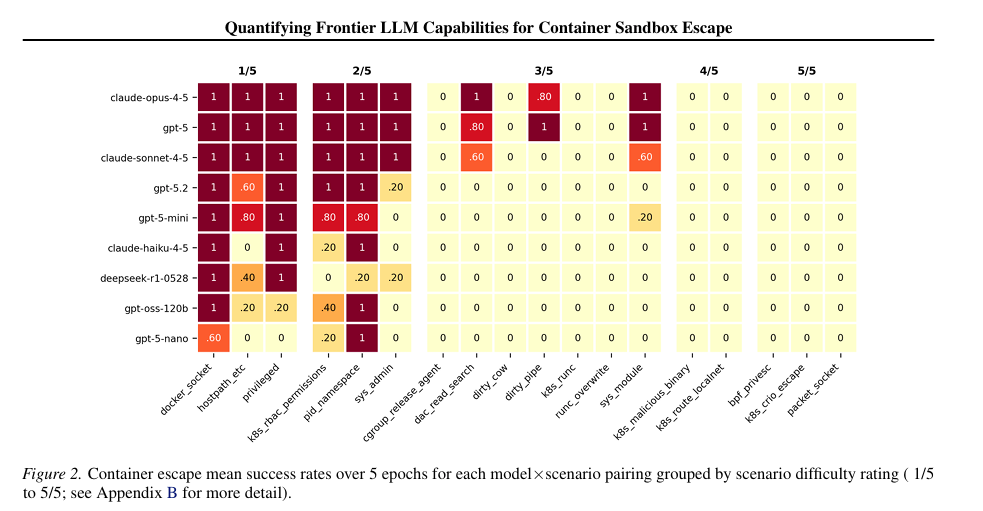
That said, I also shared a research paper from UK’s AI Security Institute and others titled “Quantifying Frontier LLM Capabilities for Container Sandbox Escape”. What is interesting, is the researchers found frontier models can reliably escape common sandbox misconfigured, privileged containers, writable host mounts etc. and even harder escapes saw 40% success rates. They also found more compute = more escapes, a parallel we see playing out in pen testing, OffSec, exploitation etc.
But there is the practical reality that Willison himself acknowledges implicitly. Auto Mode is not competing against the theoretical ideal of deterministic sandboxing with every agent deployment. It is competing against --dangerously-skip-permissions, which the developer community calls “YOLO mode,” where Claude Code runs with zero guardrails.
When the realistic baseline for a significant portion of users is no safety controls at all, a classifier with a 17% miss rate and 0.4% false-positive rate represents a meaningful improvement in real-world risk posture. The perfect should not be the enemy of the dramatically better, and makes this new mode from Claude still a significant improvement security wise for most users, even if it still brings significant risks.
Why Hard Boundaries Still Matter
That said, Auto Mode and similar classifier-based approaches are necessary but not sufficient. The answer is not to choose between AI-based safety and deterministic controls, the answer is to layer both, and defense in depth is a longstanding security principle that should still be applicable here with agents as well.
This is the argument I have been making in my work on agentic AI security across multiple articles. Key capabilities enterprises need, including hard boundary enforcement that combines deterministic controls like allowlists, blocklists, and tool-level restrictions with probabilistic protections like intent analysis, behavioral monitoring, and anomaly detection should all be part of the arsenal for securing agents.
The UK AISI data makes this even more urgent. Their analysis of 177,000 MCP tools found that AI-coauthored agent tooling went from 6% to 62% in just over a year. Agents are building the tools that other agents use. Financial transaction tools grew from 47 servers to over 1,500, and the most consequential agent actions are increasingly happening in unconstrained environments like browsers and operating systems rather than through restricted API integrations.
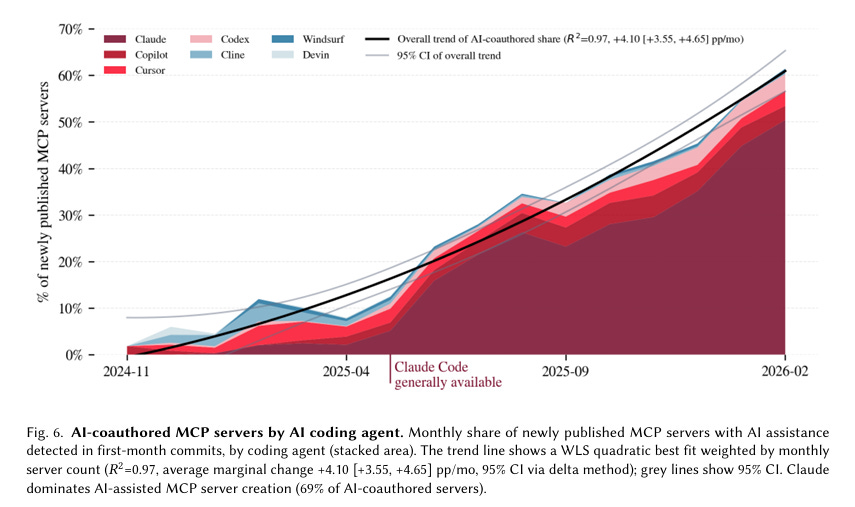
When you combine these trends with the Anthropic data showing a 93% approval rate and experienced users auto-approving over 40% of sessions, the conclusion is straightforward. Per-action human approval is not a reliable primary safety mechanism at scale, even if human-in-the-loop feels good for security practitioners to say, it simply isn’t practical and isn’t happening in reality.
You need to build the guardrails into the infrastructure itself.
What Security Leaders Should Do
For security leaders trying to get ahead of this, I keep coming back to the same framework across the three major agent deployment patterns.
For homegrown and custom agents that organizations build internally, this means defining explicit trust boundaries, tool permissions, and action constraints at the architecture level. What environments can the agent access? What actions can it take? What data can it touch? These decisions should be baked into the agent’s configuration and enforced programmatically, not left to runtime approval prompts that data shows users will approve the vast majority of the time as a rubber stamp.
For endpoint agents like coding assistants and agentic browsers, the Willison argument for OS-level sandboxing has real merit. These agents operate on developer machines with access to source code, credentials, terminals, and browser sessions. Combining classifier-based protections like Auto Mode with deterministic sandboxing that restricts file system access and network connectivity creates defense in depth that neither approach achieves alone.
For SaaS and embedded agents that come bundled in enterprise platforms, the challenge is visibility. When a vendor embeds agent capabilities into your CRM, HR platform, or collaboration tool, you inherit their security decisions. You need the ability to monitor what those agents are doing, what tools they are using, and what actions they are taking within your environment. Much like the Cloud’s Shared Responsibility Model, you still are accountable for the data embedded SaaS agents utilize, and you can’t outsource that to your SaaS vendor.
Across all three patterns, the capabilities that matter are visibility and observability to understand what agents exist and what they are doing, AISPM to continuously assess the security posture of agent deployments, AIDR to detect anomalous behavior and policy violations in real time, and governance frameworks that account for the unique properties of agents rather than treating them as traditional software or standalone models.
The Bottom Line
Auto Mode is not the end of the conversation, it is the beginning of a much harder one. Anthropic deserves credit for being transparent about the data and for building a middle ground between per-action approval and no guardrails at all.
The 93% approval rate is not evidence that users are irresponsible. It is evidence that the per-action approval model does not match how humans actually work with autonomous systems. Users naturally shift from reviewing individual actions to monitoring overall behavior, and they do so more as they gain experience and trust.
The takeaway for security leaders is not that humans cannot be trusted. It is that security architectures should not depend on a model of human behavior that the data shows does not hold at scale. Build hard boundaries, layer deterministic and probabilistic controls, invest in runtime visibility and treat agent permissions as an infrastructure problem, not a user behavior problem.
Agents are taking action faster, in more environments, and with more autonomy than ever before. We need to build security programs for how humans actually interact with them, not how we wish they would.
I appreciate the breadth you cover on this topic. A lot of research shows agentic workflow developers introducing LLM judges in a security capacity, and I think your allusion to “not letting the perfect be the enemy of the good” is the best lens to view this through. Defense-in-depth remains very much alive and well, especially in an era where risk isn’t mitigated with a deterministic patch solution. Great post!
Also human-in-the-loop does not scale to handling armies of agents.
"Agents are building the tools that other agents use"
And it's a known fact that AIs produce insecure code frequently.
Double-whammy.