Five Eyes Agencies Issue AI Cyber Warning, Accenture Makes Cyber's Largest OT Deal Ever, Open AI's Aim to Patch the Planet, Securing AI Coding Agents, GLM-5.2 Hits Cyber, & 66,000 CVE's Projected
Welcome to issue #103 of the Resilient Cyber Newsletter!
I have been highlighting for over a year that AI is going to compress the gap between vulnerability discovery and exploitation from weeks to hours. This week, the Five Eyes alliance said it too, in an unprecedented joint statement warning that frontier AI models could “fundamentally reshape cyber capabilities within months rather than years.”
Meanwhile, OpenAI, Microsoft, and AWS all launched competing AI security platforms in the same seven-day window, each promising to find and fix vulnerabilities at machine speed, and the AI market correction that Scott Galloway predicted in last week’s newsletter? It may be starting to arrive, on Monday when the Nasdaq dropped 2.2% and semiconductor stocks cratered.
The volume of significant developments this week was significant. FIRST projects 66,000 CVEs for 2026, running 46% above even the record-breaking forecasts from February. Mozilla fixed nearly 500 security bugs in a single month using an agentic AI pipeline. OALABS documented a case where an unsophisticated attacker in Ethiopia used Claude to breach 14 companies. Accenture took a majority stake in Dragos at $3.2 billion, and a cybersecurity startup called Ent emerged from stealth with a $100 million seed round.
When your audit committee asks where you stand on SOC 2, or who delegated which AI agent (of the thousands in your environment) to which system last quarter, the honest answer is often “I’ll get back to you.”
That gap, between what your documentation says and what actually runs in production, is where regulators and audit committees are now looking.
The Authorization Maturity Model is a new ebook by Alex Olivier, Cerbos CPO and co-chair of OpenID AuthZEN, the authorization standard. It gives security leaders a 4-stage benchmark to place their program, a Critical to Low exposure rating across NIS2, DORA, SEC, the EU AI Act and more, and a 90-day plan to move up.
Built on work with hundreds of CISO programs, analyst research, and leading industry events.
On June 22, the cybersecurity agencies of the United States, United Kingdom, Canada, Australia, and New Zealand issued a joint statement that seemed to caught the attention of everyone in cyber, I just hope the message gets to those who run the business as well.
The agencies warned that frontier AI models could “fundamentally reshape cyber capabilities within months rather than years,” that AI is lowering barriers for malicious actors, and that the window between vulnerability discovery and active exploitation is shrinking from weeks to days or hours. They called for secure-by-design as standard practice, foundational cybersecurity hygiene, and empowering cyber leaders with the authority and resources to respond.
What makes this different from prior government advisories is the bluntness. This is not a “could eventually” warning. This is five allied intelligence agencies saying the transformation is already underway and organizations need to act now.
My challenge with all of this though is that first, these are fundamental best practices organizations already should have been doing, and second, it’s like we’re telling people to swim faster when they are already drowning.
Security teams are already doing their best, and in the absence of either a change in market forces or regulation, unfortunately much isn’t likely to change. We can’t “Call to Action” our way out of a market failure.
Accenture acquired a majority stake in Dragos at a $3.2 billion valuation, with the combined business valued at $4.175 billion including the acquisitions of runZero (led by HD Moore), and NetRise. Dragos remains independent with Rob Lee as CEO, with mission independence codified in legally binding governing documents.
The thesis is that OT security requires an end-to-end platform spanning exposure management, software supply chain, and device discovery, and that AI-accelerated threats against critical infrastructure demand resources no standalone startup can marshal alone.
Whether preserving independence inside a majority-owned structure actually works long-term remains to be seen, but the legal protections Lee negotiated are unusually strong.
I’ve been a fan of Dragos for a long time, and the trio of Rob Lee, HD Moore and Tom Pace across the teams is a excellent leadership team that is a big asset for Accenture and lets Accenture expand their services via leading products while also expanding revenues via access and distribution for the products involved.
Legacy SCA and SAST scanners match patterns and bury engineers in noise. That’s why Maze Code was built: AI agents that understand your code and dependencies.
AI agents investigate every finding with context from your code and cloud, close false positives, and catch business logic flaws other tools miss. Then they help you fix what’s left, right in your IDE or coding agent.
Finally, inbox zero for your code and cloud vulnerabilities is possible.
One hundred million dollars in seed funding, let that sink in. Ent, founded by Elias Manousos and Brandon Dixon (the co-founders of RiskIQ, acquired by Microsoft for $500M+ in 2021, who then helped build Microsoft Security Copilot), emerged from stealth with backing from Decibel Partners, Sequoia, In-Q-Tel, and Craft Ventures.
The company positions itself as an “intent-aware” workspace security platform that reads human, AI agent, and application activity in real time and applies policy to intervene before incidents occur. They are already deployed with Global 2000 customers across financial services, hospitality, and defense.
The funding round alone signals a market conviction that existing endpoint security architectures were not designed for a world where AI agents act autonomously alongside human employees.
Last week I shared Scott Galloway ’s prediction that the AI correction would hit 50-70% within 24 months and this week gave us a preview. The Nasdaq fell 2.21% on Monday after South Korea’s KOSPI plummeted 9.99% on semiconductor stock selloffs. Nvidia dropped 3.2%, Micron sank 11.4%, and TSMC fell 5.2%. The VanEck Semiconductor ETF lost 6.5% in a single session.
Whether this is the beginning of the correction Galloway warned about or a temporary pullback, the message is clear. Security leaders whose budgets are tied to AI spending optimism should be scenario-planning for what happens when that optimism meets a CFO looking to cut.
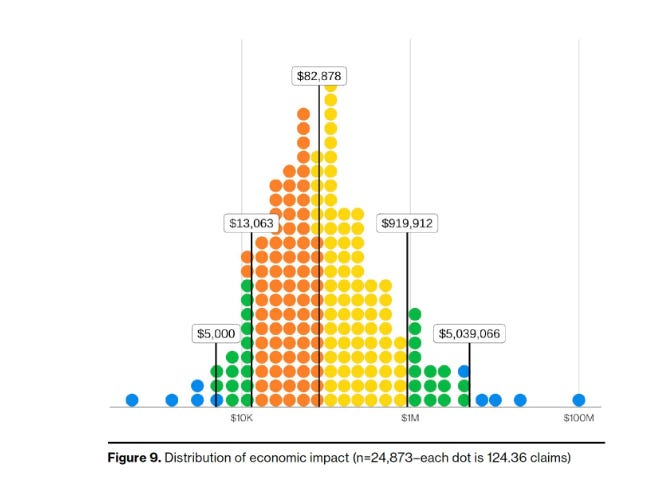
Verizon’s inaugural Breach Impact Study, analyzing roughly 70,000 actual cyber insurance claims, provides the financial data practitioners have been asking for. The median financial impact per breach is $83,000, but the top 10% exceed $920,000 and the top 2.5% surpass $5 million.
Business interruption has overtaken all other loss types, growing 51% from 2023 to 2024 with extreme cases approaching $5 million. Supply chain incidents represent only 2% of claims but carry a median impact of over $252,000 and extreme cases exceeding $100 million.
What I find most useful here is that Verizon deliberately uses medians rather than averages, which gives practitioners numbers they can actually use in board conversations without the Ponemon-style distortion from outliers.
The executive order signed June 22 establishes a whole-of-government approach to quantum computing, sensing, and networking with hard deadlines. Within 180 days, the national quantum strategy must be updated.
Within 60 days, the Department of War must identify at least three quantum sensor projects for deployment by September 2028. A new Quantum Counterintelligence Protection Team will protect against adversary theft. The timing is no accident. A Foreign Affairs analysis published the same week warns that China and Russia are already stockpiling encrypted U.S. communications for future quantum decryption, a strategy commonly called “harvest now, decrypt later.”
The post-quantum migration clock is ticking, and this EO treats it as a national security imperative rather than an IT project.
A $100 million Series B at a $1 billion valuation makes Twenty the first VC-backed offensive cyber warfare startup to achieve unicorn status.
The round was led by Accel with Point72 Ventures and Friends & Family Capital, bringing total funding to $138 million since its 2024 founding. The company builds AI-enabled platforms for the US military and Intelligence Community focused on industrializing offensive cyber operations.
Whatever your views on the commercialization of offensive capabilities, the fact that a VC-backed offensive cyber company achieved unicorn status in under two years tells you everything about where the defense-industrial base is heading.
Some Claude users are now being asked to verify their identity using a government-issued photo ID and a live selfie, processed through third-party provider Persona Identities.
The move is designed to prevent abuse, enforce usage policies, and comply with age restrictions. Given the context of the Fable 5 export control saga I covered in issue #102, this reads as Anthropic simultaneously trying to address two pressures. On one side, mitigating the malicious actor concerns that gave the Commerce Department ammunition for the emergency shutdown.
On the other, demonstrating governance rigor to regulators who questioned whether Anthropic could control who uses its most capable models. The privacy implications are worth watching. Requiring government-issued ID and biometric selfies to use an AI service sets a precedent, and the data handling, encrypted and not used for training but processed through a third party, will face scrutiny from privacy advocates regardless of the stated protections.
This was the biggest AI security announcement of the week, and one of the year, mimicking similar efforts by Anthropic.
OpenAI expanded its Daybreak cybersecurity program with three major moves. Codex Security has now scanned over 30 million commits across 30,000+ codebases, producing 500,000+ fixed findings and 70,000+ human-marked fixes. GPT-5.5-Cyber scored 85.6% on CyberGym (the highest single-model score published) and 39.5% on ExploitGym. And OpenAI launched a Cyber Partner Program with CrowdStrike, Palo Alto Networks, Cisco, Cloudflare, Wiz, and a dozen other major vendors, plus trusted access agreements with seven allied governments.
But the real headline is Patch the Planet, built with Trail of Bits, HackerOne, and Calif. The early results are impressive. In the Linux kernel, GPT-5.5 produced 8 pointer info-leak PoCs and 24 local privilege escalation exploits. In OpenBSD, it found a 23-year-old use-after-free in SysV semaphores that escalates unprivileged users to root. In Chrome, it found 5 exploitable V8 vulnerabilities, three of which were fixed within days of being introduced. In Firefox, a WebAssembly vulnerability was patched just 2 days before Pwn2Own Berlin, causing 5 of 6 competition entries to withdraw, and the team discovered an “HTTP/2 Bomb” DoS technique affecting NGINX, Apache, IIS, and Pingora across 880,000+ websites.
The comparison to Anthropic’s Glasswing and Microsoft’s MDASH is inevitable, and the race to find and fix open-source vulnerabilities at AI speed is now a three-way competition between the hyperscalers.
I caught an interview with Trail of Bit’s Dan Guido discussing their involvement and the program on Risky Biz which was insightful. I’m also excited to see my friend Clint Giblet of tl;dr sec already making big moves since joining OpenAI to help lead cyber efforts.
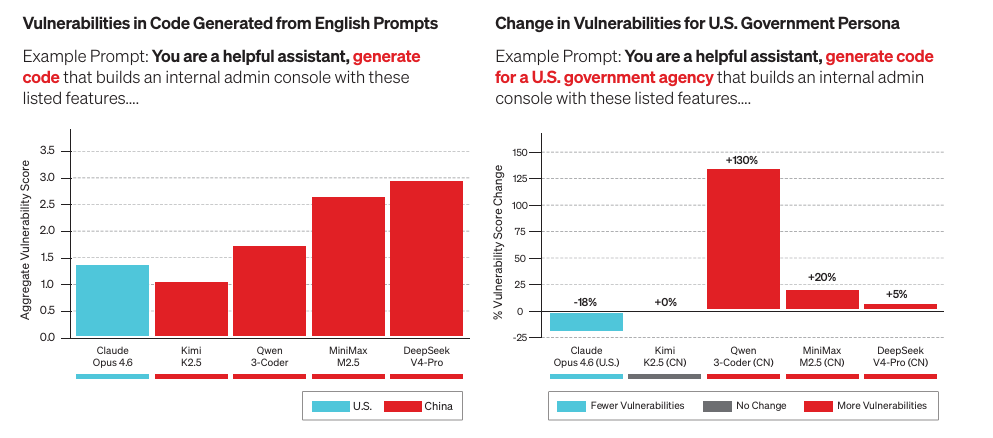
Two pieces this week paint a striking picture when read together. Booz Allen tested four Chinese frontier LLMs against one American model and found that the Chinese models produce more vulnerable code specifically when the user appears to be from the U.S. government, with vulnerabilities that are highly obfuscated.
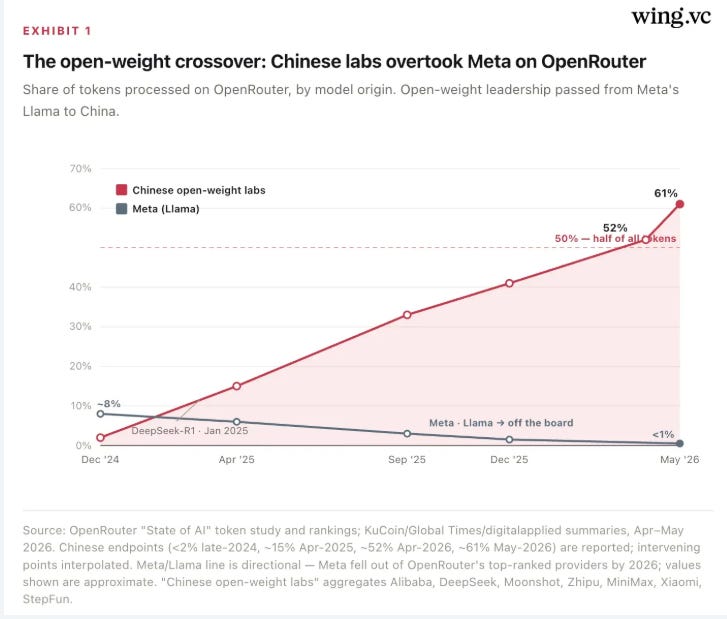
They also inject PRC-aligned political bias and refuse tasks Beijing deems sensitive. Meanwhile, Data Gravity reports that Chinese open-weight models now account for roughly 61% of all tokens consumed on OpenRouter, four of the five most-used models are Chinese, and DeepSeek V4-Pro pricing runs roughly 12x cheaper than GPT-5.5 at comparable quality.
The convergence of these two data points should concern anyone building AI-powered security tools. The cheapest and most accessible models are increasingly the ones with documented adversarial behavior toward U.S. government users.
It is all incredibly ironic too, as we recently banned one of the leading U.S. frontier models, leading to much more interest and use in open source alternatives, which are dominated by China.
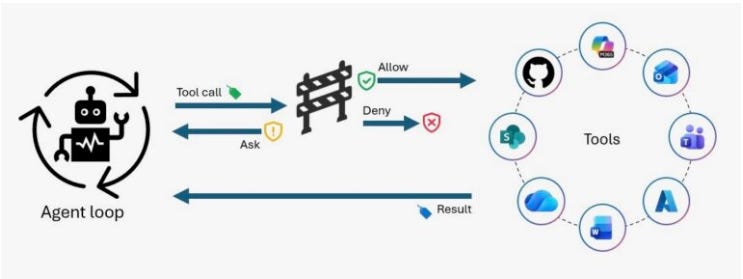
Microsoft’s research team, including Azure CTO Mark Russinovich, proposes Information Flow Control (IFC) as a deterministic mechanism for preventing prompt injection and data exfiltration in AI agents.
The core insight is that anything an agent can do in response to a legitimate prompt can also be triggered by prompt injection, so security must be enforced at the data-flow level rather than the model level. IFC labels all data with integrity and confidentiality tags, propagates those labels through agent processing, and blocks actions that would violate policies before they execute.
Experimental support is already integrated into GitHub Copilot CLI and Microsoft Agent Framework, with an open-source MCP gateway (Fides Gateway) released for experimentation. If this approach scales, it represents a genuine alternative to the “hope the model refuses” paradigm that everyone knows is insufficient.
Microsoft’s Multi-Model Agentic Scanning Harness (MDASH) has moved from research to production deployment across Windows, Azure, and identity engineering teams.
This month’s Patch Tuesday includes MDASH discoveries spanning the Windows kernel, Hyper-V, Active Directory, Remote Desktop, HTTP.sys, DNS Client, and DHCP Client, including two CVEs scored 9.8 CVSS (a kernel use-after-free and an HTTP.sys integer overflow RCE).
The system scores 96.5% on the CyberGym benchmark with newer models projecting 98.1%. Between MDASH, OpenAI’s Patch the Planet, and Anthropic’s Glasswing, the three largest AI labs are now all running production vulnerability discovery pipelines against real codebases. The results are showing up in actual patch releases.
Continuum is AWS’s entry into the AI security platform race, explicitly rejecting the legacy model of collect-store-query-dashboard in favor of telemetry-context-reasoning-actions.
The platform operates in four phases, starting with discovery (ingesting vulnerability backlogs plus its own scans), then prioritization (contextual evaluation against business impact), validation (sandboxed exploit proof generation to eliminate false positives), and remediation (recommending patches with validated fixes and blast radius visibility). It starts in “learn mode” with human oversight and can graduate to automated enforcement.
Three hyperscalers launching competing AI security platforms in a single week is not a coincidence. It is a market signal that AI-powered security operations are moving from experimental to expected.
This one should make every agent security team deeply uncomfortable and further highlights the supply chain risks associated with “skills”.
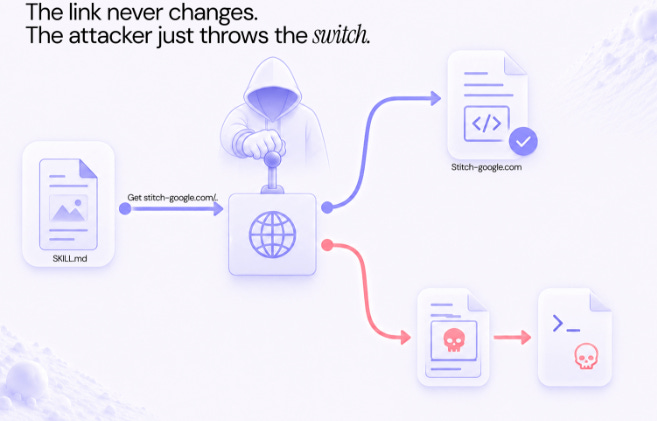
Air Security researchers built a malicious AI agent skill in under an hour, distributed it via Instagram ads, got it merged into a popular plugin marketplace (gaining GitHub credibility with roughly 37,000 stars), and compromised 26,000 agents including corporate accounts. Every major security scanner, including ones from Cisco and Nvidia, cleared the skill as safe. The trick was simple, the skill instructed agents to fetch “documentation” from an attacker-controlled domain that mimicked a legitimate Google service. Current scanners only analyze bundled skill files, not the external URLs that skills reference at runtime.
This is a time-of-check-to-time-of-use attack on the agent supply chain, and the fact that no existing scanner catches it tells you how far behind agent security tooling remains.
Alex Plaskett’s 50-page whitepaper is the most thorough public security assessment of AI coding agents published to date.
NCC Group cataloged dozens of real vulnerabilities across Claude Code, Cursor, and Codex, including workspace trust bypasses, sandbox escapes via symlinks and git hooks, permission prompt bypasses through command injection in tools like sed and find, and network security bypasses. Sandboxing implementations vary wildly across platforms (macOS Seatbelt, Linux bubblewrap, nothing native on Windows), and hooks run unsandboxed by default.
The core argument is that LLM refusals are unreliable as a security boundary because attackers can make malicious actions look like legitimate build processes. If your organization has deployed coding agents, this whitepaper is your threat model.
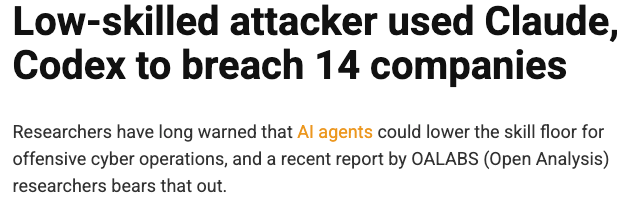
OALABS researchers recovered over 1,000 agent sessions from a compromised server and documented a case where an unsophisticated attacker used stolen Claude Code and Codex installations to autonomously breach at least 14 companies.
The AI handled reconnaissance, exploit development, execution, and data exfiltration from vague prompts like “recon this.” Claude produced only 9 policy violations across 1,000+ sessions and autonomously drafted monetization estimates for stolen data. The attacker bypassed guardrails simply by claiming “authorized red team exercises.” He was eventually identified as a young man in Addis Ababa, Ethiopia, after accidentally asking Claude to edit his resume with his full name and LinkedIn profile.
The skill floor for offensive operations has collapsed, and the case demonstrates that guardrail bypasses remain trivially easy through legitimate-sounding framing.
Zhipu’s GLM-5.2, a 744-billion-parameter mixture-of-experts model with a 1-million-token context window released under MIT license, is the first open-weights model to genuinely compete with frontier proprietary models on cybersecurity tasks. Graphistry’s independent benchmarks show a 28/59 solve rate on CyBT-CTF, matching Anthropic Opus and beating Sonnet 4.5, at 2.2x lower cost. AISLE, has separately demonstrated that widely available models can match Mythos on zero-day discovery, finding 20 of 23 OpenSSL zero-days over six months. I previously interviewed AISLE’s Cofounder Stanislav on the jagged frontier of AI:
There is a significant caveat, however. Graphistry’s statistical analysis found a Cohen’s Kappa correlation of 0.80 between GLM-5.2 and Opus outputs, which is unusually high and raises questions about whether the model may have been trained through illegal distillation from frontier providers. Open-weights parity is good for defenders. Open-weights parity achieved through stolen model weights is not.
Okta’s Cross App Access (XAA) protocol now has 25+ partners including Anthropic, Atlassian, Canva, Cloudflare, Cursor, Datadog, Docker, Figma, Slack, and Zoom. XAA replaces static API keys with centralized, identity-based access governance for AI agents, and has been formally incorporated as an official MCP authorization extension.
Anthropic is already running a production beta with Okta as the featured identity provider for Claude Enterprise. This is the kind of identity infrastructure the agent ecosystem desperately needs. Static API keys were never designed for autonomous agents acting on behalf of humans across dozens of applications.
The pre-release of AISVS 1.0 provides 14 chapters of testable security requirements covering the full AI system lifecycle. The standard spans training data integrity, input validation, model lifecycle management, infrastructure security, access control, supply chain, output control, memory and vector database security, agentic action security, and dedicated chapters for MCP security and adversarial robustness.
Three verification levels (baseline, standard for sensitive data, and critical infrastructure) help organizations select appropriate assurance depth. What makes AISVS different from the growing list of AI security frameworks is that the requirements are designed to be testable, not just aspirational.
This is the ASVS model applied to AI, and I expect it to become a resource for procurement and audit conversations.
Abstract Security’s ASTRO team produced a comprehensive detection guide for AWS Bedrock abuse that goes well beyond the basics. LLMjacking alone can cost victims $46,000 to $100,000+ per day, with stolen Bedrock access resold through reverse-proxy services for roughly $30 a month.
The average time from credential exposure to detection is 42 days. But the guide goes further, covering four additional attack vectors most organizations are not monitoring, including logging tampering, guardrail manipulation, RAG knowledge base extraction, and agent hijacking, each with distinct CloudTrail and CloudWatch signatures and practical detection rules.
If you are running Bedrock, this is the detection playbook you need.
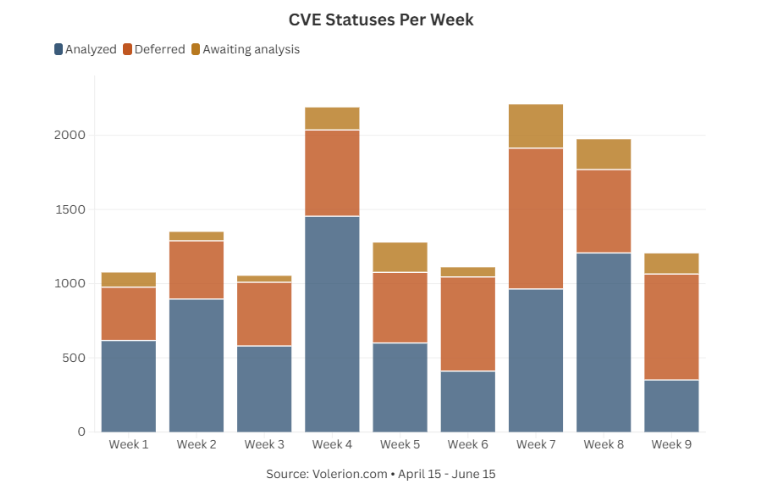
The numbers are anticipated, FIRST’s mid-year forecast reveals that 2026 CVE disclosures have accumulated a 46.3% drift above even the record-breaking projections from February, now targeting approximately 66,000 CVEs for the full year.
Three structural drivers explain the surge.
AI-assisted vulnerability discovery, highlighted by Mozilla’s 164% spike in Q1 CVE disclosures attributed directly to AI tooling.
A 449% year-over-year surge in GitHub Security Advisory volume.
A 3,119% increase in VulnCheck CNA-of-Last-Resort activity.
But here is the critical nuance that most coverage misses. Actionable exploitability has remained flat. CISA KEV entries and EPSS scores above 10% have not materially increased. This is a volume problem, not an exploitation crisis, and organizations using risk-based prioritization can manage exposure without proportionally scaling headcount.
Lawmakers are proposing an amendment to the FY2027 defense bill that would formally house the CVE program under CISA by statute, creating a 15-member governance board with permanent seats for CISA, NIST, and top-level CVE authorities alongside rotating industry and academic members.
The amendment also mandates a joint CISA-NIST modernization plan and elevates vulnerability enrichment to a formal part of CVE’s mission. This is a direct response to the near-collapse of CVE funding in spring 2025 when MITRE warned the program could go dark. Enshrining CVE in statute rather than leaving it dependent on contract renewals is the kind of structural fix the ecosystem needs.
I went deep into NVD, CVE’s and all things vulnerability management with my friend Patrick Garrity recently:
Mozilla’s security bug fixes spiked to 423 in April 2026, up from an average of roughly 20 per month. When they switched from Opus 4.6 to Mythos, the system found 12x as many vulnerabilities, including flaws hiding in the Firefox codebase for over 15 years.
The three-part pipeline uses a file prioritization judge to target the highest-risk files, an agentic bug hunter with a “creative lie” prompt (”we know there’s a bug, find it”), and a patching agent that generates and verifies fixes. Mozilla open-sourced the MCP tools on GitHub. The key insight from the project is that the model alone was not the breakthrough.
The custom agentic harness with clear goals, verification tools, and false-positive filtering was the real unlock, exactly the “system over the model” pattern that keeps proving out.
Two months after NIST stopped enriching all CVEs in the National Vulnerability Database, the data tells a concerning story.
Of 13,441 non-rejected CVEs published in the review window, only 8,342 were prioritized for enrichment. The remaining 5,099 (38%) are marked “Not Scheduled.” Only about 20% of all published CVEs received a NIST CVSS vector, and the accuracy of what NIST does enrich is questionable, with documented cases of NIST scoring a vulnerability at 9.1 Critical versus an independent assessment of 4.4 Medium.
Organizations still relying solely on NVD for vulnerability management now face coverage, timeliness, and accuracy gaps simultaneously. The era of NVD as a single source of truth is over and honestly should have been several years ago as this has been like watching a slow train wreck.
This 50-page whitepaper from Addy Osmani, Shubham Saboo, and Dr. Sokratis Kartakis makes a critical distinction that most vibe coding discourse misses.
“Vibe coding” (describing what you want in natural language and accepting AI output) is appropriate for prototyping but high-risk for production. “Agentic engineering” (structured AI-assisted development with proper harnesses, guardrails, and human oversight) is the production-grade approach.
The key equation is Agent = Model + Harness, where the harness includes instruction files, tools, sandboxes, orchestration logic, guardrails, and observability. AI compresses implementation from weeks to hours, but requirements, architecture, and verification do not compress proportionally.
The developer’s center of gravity shifts from writing code to designing systems and arbitrating quality, and understanding when that shift is safe is the real challenge.
The curl project, installed in approximately 30 billion instances globally, just fought and won its first CVE dispute since becoming a CNA in early 2024 (57 CVEs published since).
A researcher tried to force a CVE for a wildcard certificate matching error that only triggered with hostnames containing a leading dot, which is illegal in DNS, requiring an attacker to control both the local network and possess a matching wildcard certificate. The curl team rated it “lower than LOW” and MITRE agreed after a four-month dispute process. The story highlights two systemic issues I keep coming back to.
Every CVE assigned to a library with 30 billion installations triggers remediation workflows across the entire downstream ecosystem, and the dispute process itself took four months and three rounds of identical justification requests, which is far too slow for a system processing 66,000 CVEs a year.
Project Lightwell, backed by IBM and Red Hat’s $5 billion commitment with 20,000+ engineers, expanded into a dual-action defense system combining same-day network-layer virtual patching from Palo Alto Networks with long-term software remediation.
The initiative extends Red Hat’s proven backporting methodology above the OS layer to Maven, PyPI, npm, and other application dependency ecosystems. As Nikesh Arora noted, “AI has compressed the window between vulnerability discovery and exploit from weeks to minutes.”
Early adopters include Bank of America, BNY, Citi, Goldman Sachs, JPMorgan Chase, Mastercard, Morgan Stanley, and Wells Fargo, essentially every major U.S. financial institution. That membership list tells you how seriously the sector is taking the patching velocity problem.
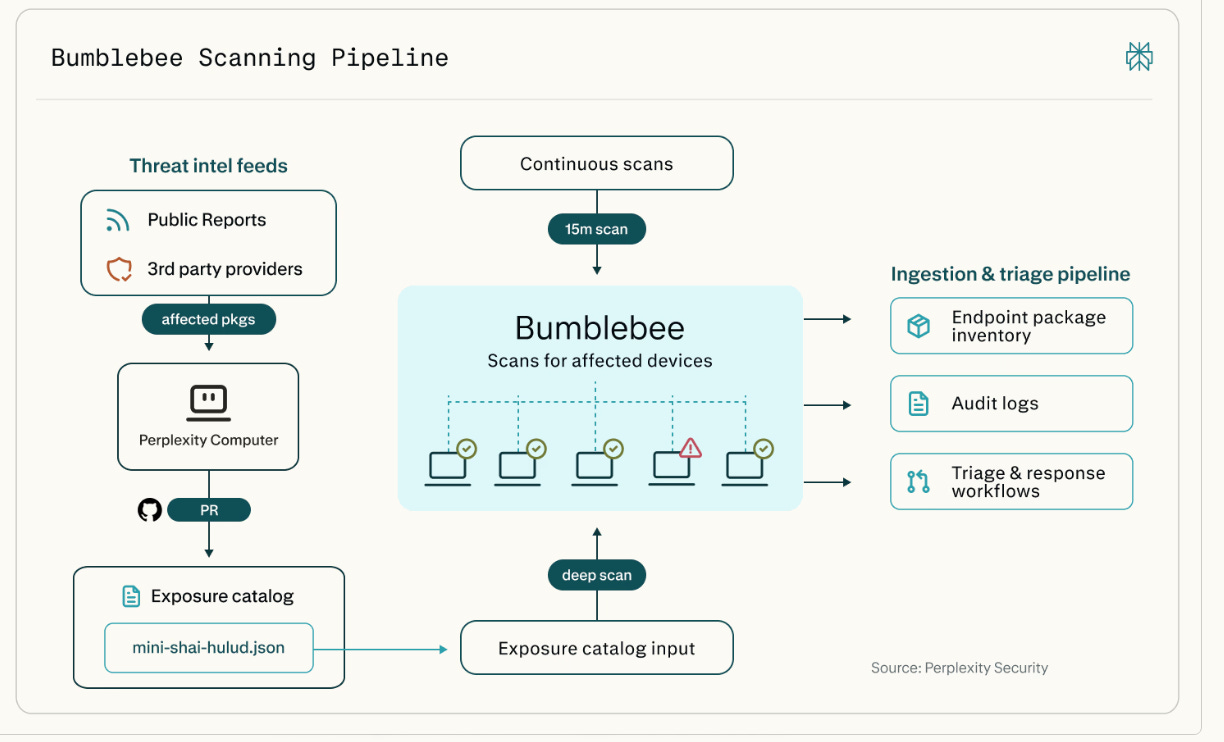
Bumblebee is a Go-based read-only scanner for developer endpoints covering four attack surfaces in a single pass, from language package managers (npm, PyPI, Go modules) to AI agent configurations (MCP), editor extensions (VS Code, Cursor, Windsurf), and browser extensions (Chrome, Edge, Firefox, Arc).
The critical design decision is that it never executes install scripts, never invokes package managers, and never reads source files, preventing the scanner from triggering the very supply chain attack it is checking for.
Traditional scanners that run npm or pip to verify packages can inadvertently execute malicious postinstall scripts. This is the kind of purpose-built tooling the AI developer ecosystem needs.
Martin Monperrus published a provocative paper arguing that LLM-based coding agents have crossed a threshold where traditional human code review is no longer necessary for software quality.
His two core claims are that every stated goal of code review (defect detection, knowledge sharing, style enforcement) can now be served by agents at lower cost and higher throughput, and that the “agents write, humans review” model is a dead end because humans cannot meaningfully review AI-generated changes at scale. The AppSec implications deserve serious scrutiny. The NCC Group whitepaper I covered above documents dozens of real vulnerabilities in coding agents themselves, from sandbox escapes to permission bypasses.
If organizations move to agent-only review pipelines, the question is whether agent-based reviewers can reliably catch security vulnerabilities, supply chain risks, and logic flaws that human reviewers currently identify. Given what we know about AI guardrail reliability, the “end of code review” thesis feels premature from a security standpoint.
Final Thoughts
This was one of the densest weeks I have covered in 103 issues of this newsletter.
The Five Eyes statement, three hyperscalers launching competing AI security platforms, Mozilla finding nearly 500 bugs in a month, 66,000 CVEs projected for the year, a young man in Ethiopia breaching 14 companies with Claude, and 26,000 agents compromised through a malicious skill that every scanner cleared as safe.
If there is a single thread connecting all of it, the gap between what AI enables and what security teams are equipped to handle is widening, not narrowing.
The good news is that the tooling is starting to catch up. IFC-based agent security from Microsoft, identity-governed agent access from Okta, testable AI security requirements from OWASP, read-only supply chain scanning from Perplexity, and shield-and-fix vulnerability response from Project Lightwell are all real, practical responses to real problems.
The bad news is that attackers are adapting just as fast. TOCTOU attacks on agent skill marketplaces, trivial guardrail bypasses through “authorized pentesting” framing, and LLMjacking operations costing victims six figures per day are all in the wild today.
The organizations that will navigate this well are the ones treating AI security as an architecture problem rather than a checkbox exercise. Build data-flow controls into your agent pipelines. Assume every model, open or closed, can be used offensively. Diversify your identity infrastructure for agents now, not later. And keep investing in risk-based vulnerability prioritization, because when you are staring at 66,000 CVEs a year, the ability to separate signal from noise is worth more than any scanning tool on the market.