

With software powering everything from consumer goods to critical infrastructure and national security, it may come as a surprise that something as simple as naming software is fractured and has significant gaps.

Software identification is used for everything from software asset inventory, version control to vulnerability management, incident response and more.
In this article, we will discuss some of the prevailing forms of software identifiers and how they operate as well as some of the challenges preventing “one to rule them all”, as in a single identifier that meets the diverse use cases and requirements we need within our digital ecosystem.
To frame the discussion I’ll be using the “Software Identification Ecosystem Option Analysis” whitepaper from the Cybersecurity and Infrastructure Security Agency (CISA). The paper was released October 26th 2023, and CISA is currently seeking public feedback and comments by December 11th 2023. The paper discusses the merits and challenges of the current software identifier ecosystem.
For a great primer on the topic, I also recommend listening to a talk by Lindsey Cerkovnik (also a CISA employee) at S4 Events, where she breaks down software identification in a talk titled “Software Identity and The Naming of Things”.
Lindsey covers the current software identification methods, as well as gaps. She also draws parallels to physical world examples, such as vehicle identification numbers (VIN)’s.
So, what’s in a name?

Software Identification Formats
No discussion around vulnerability scoring and prioritization would be complete without also covering some of the primary software identification formats, their respective challenges and shortcomings, and the value that each has in the broader discussion around vulnerability management.
Various stakeholders from software and technology suppliers, consumers, vendors, and researchers utilize software identification formats to tie software and products to a specific vendor, for example. In this section we will discuss some of the primary formats and where and how they may be used.
For a good primer on the leading software identity formats, as well as some of the challenges associated with the existing formats and software identity more broadly, we recommend watching a 2023 talk from CISA’s Branch Chief for Vulnerability Response and Coordination, Lindsey Cerkovnik titled “Software Identity and The Naming of Things”. In the talk, Lindsey covers the three primary software identity formats relevant at the time of this writing, which we will cover in more detail below.
Common Platform Enumeration (CPE)
While CVEs are used to identify and describe specific vulnerabilities, CPEs are used as a naming scheme for systems, software and packages. They are compiled into a broad CPE Product Dictionary, which is maintained by NIST. Versions of the CPE dictionary are available for download from the NIST NVD website.
Products are identified, and then a CPE name is submitted and approved to be included in the overarching Official CPE Dictionary. This way it can be used in searches for vulnerabilities, demonstrating the products and software it impacts.
The NIST NVD uses CPEs when discussing the applicability of vulnerabilities and the products or software they impact. CPEs provide a standardized format for machine-readable representations of IT products and platforms. Prior to CPE’s introduction, the industry lacked such a format and thus struggled to correlate vulnerabilities with specific products or platforms in the ecosystem.
As mentioned by NIST, CPEs can be leveraged by IT management tooling to collect information about installed products using the CPE name and help with making decisions regarding the assets based on the vulnerabilities impacting them.
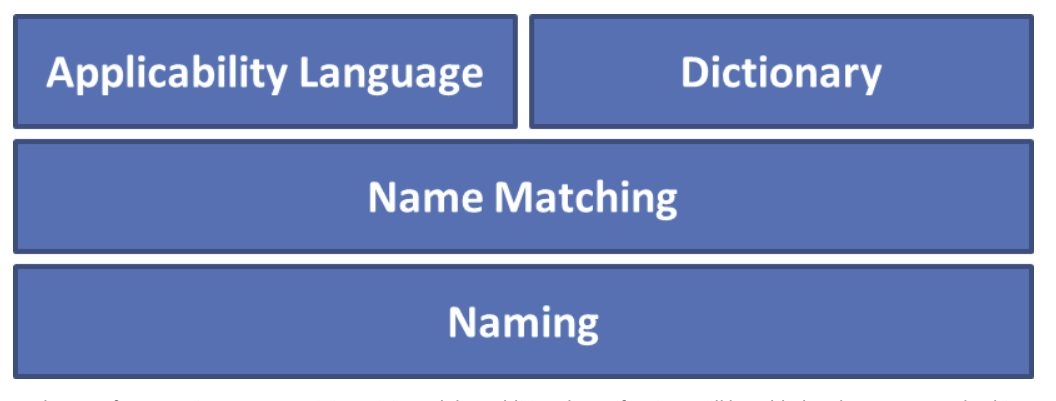
At the time of this writing, the current version of CPE is 2.3. Its structure is captured in the image below, with its most fundamental purpose, naming, at the bottom of the structure with additional layers built on top of it.
Source: https://csrc.nist.gov/projects/security-content-automation-protocol/specifications/cpe
Let's look at the aspects of the CPE 2.3 structure and its various components.
Naming - The Naming specification defines the logical structure of Well-Formed Names (WFNs), URI bindings, and formatted string bindings, and the procedures for converting WFNs to and from the bindings.
Name Matching - The Name Matching specification defines the procedures for comparing WFNs to each other to determine whether they refer to some or all of the same products.
Dictionary - The Dictionary specification defines the concept of a CPE dictionary, which is a repository of CPE names and metadata, with each name identifying a single class of IT product. The Dictionary specification defines processes for using the dictionary, such as how to search for a particular CPE name or look for dictionary entries that belong to a broader product class. Also, the Dictionary specification outlines all the rules that dictionary maintainers must follow when creating new dictionary entries and updating existing entries.
Applicability Language - The Applicability Language specification defines a standardized structure for forming complex logical expressions out of WFNs. These expressions, also known as applicability statements, are used to tag checklists, policies, guidance, and other documents with information about the product(s) to which the documents apply. For example, a security checklist for Mozilla Firefox 3.6 running on Microsoft Windows Vista could be tagged with a single applicability statement that ensures only systems with both Mozilla Firefox 3.6 and Microsoft Windows Vista will have the security checklist applied.
The CPE dictionary is updated nightly, and it is available for download as well as being available as a search-based website where individuals can run queries for specific products, applications, and software. For those interested, you can also dig into the CPE 2.3 XML schema.
All these additional resources are available at the NIST CPE website. Readers can also view the official CPE dictionary statistics to see the annual growth of CPE’s and the year-over-year growth of identified products, vendors, and entries, as well as how many have been deprecated.
Package URL (PURL)
Another prevalent software identification method is the Package URL, also known as “PURL.”
While CPE is product-specific and has utility for identifying specific products and vendors, PURL is much more focused on third-party dependencies, components, and packages and is heavily used in the package manager ecosystem.
The reason this is key is based on studies from sources such as Synopsys, who found in their 2022 Open Source Security and Risk Analysis Report, 78% of modern codebases are increasingly made up of OSS components. Not only were 78% of the 2,409 code bases audited composed of OSS components, but 97% of the code bases contained some level of OSS.
Further concerning is the fact that almost 90% of the components had no new development in two years, and 85% of the components were more than four years out-of-date.
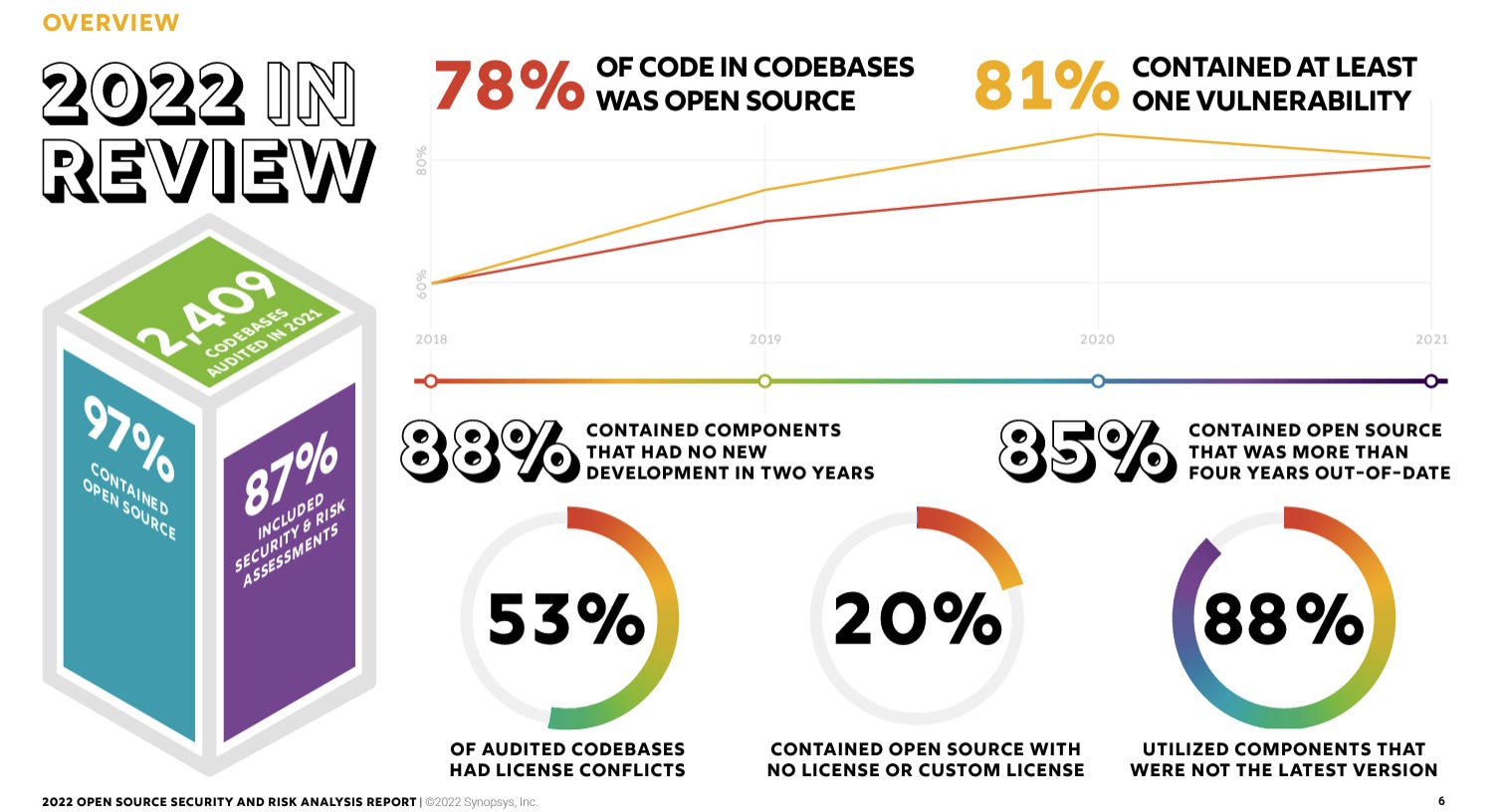
This proliferation of OSS components and their associated risks is paired to the growth of software supply chain attacks, which may of course target specific vendors and products, but also are increasingly targeting the OSS components that software suppliers and organizations use in their applications and architectures.
For a breakdown of the various potential software supply chain attack types, you can see my article “Software Supply Chain Attack Types”, where I used the CNCF Catalog of Software Supply Chain Compromises as a reference.
To emphasize the growth of the risk associated with software supply chain attacks, software supply chain vendor Sonatype produced a 2023 Software Supply Chain Report that found there was a 742% average annual increase in software supply chain attacks over the previous 3 years and over 3.4 billion vulnerable downloads each month.
Their report also found that nearly one trillion more packages were downloaded from the most popular package repositories than the previous year, reiterating the explosive growth of OSS and software package consumption, and further emphasizing the key role of PURL for software identification.
The increased adoption of OSS coupled with the growth of supply chain attacks means the need for effective software and hardware identification is critical. However, as it stands currently, the NIST NVD only supports CPE, which as we have discussed is product- and vendor-specific.
One group, who goes by the name the “SBOM Forum,” has begun to make the case that the NVD needs to grow beyond using CPE as the sole identifier. In a paper titled “A Proposal to Operationalize Component Identification for Vulnerability Management,” the group proposes that the NVD adopt the use of PURL. The group posits that PURL identifiers are native to the package manager ecosystem and already in widespread use.
As pointed out by the paper, modern software development languages utilize package managers, which describe the third-party and OSS components used by an application.
These components are referred to as dependencies, and in the package manager ecosystem, each dependency is given a Package URL, or PURL. To help make the case for using PURL for vulnerability management, the group also mentions that several sources of vulnerability intelligence and vulnerability management vendors have already adopted PURL into their platforms and offerings.
However, the group does note that PURL is only applicable to software, whereas CPEs can apply to both hardware and software.
Software Identification Tags (SWID)
Another common software identification format, although it is experiencing less use due to CPE and most notably the growth of PURL, is the software identification tags (SWID) format. SWID is an International Organization for Standardization (ISO) standard that defines a structured metadata format for describing software products.
SWID seeks to help organizations effectively manage their software inventories in a structured fashion. SWID uses what are known as tag files to describe specific releases of software products. SWID tags can be used throughout the entire software product lifecycle, from installation to decommissioning.
Organizations other than ISO have also advocated for the use and adoption of SWID tags, such as NIST, who recommends SWID’s use to entities such as software producers and standards bodies and mentions the use of SWID tags in their various guidance and publications.
So what’s the problem?
So, we have several software identification formats, what’s the issue? Well, let’s take a look at some of the challenges as laid out by CISA in the white paper I mentioned in the introduction.
First off, CISA states in their paper that the two key requirements for an effective software identification ecosystem are:
Timely availability of software identifiers across all software items
Software identifiers that support both precision and grouping
The paper also discusses the need to enable correlation across datasets, within an organization and beyond. To do this, it lays out two key requirements, which are:
Making identifiers available when and where they are needed - which means identifiers have to exist when the data artifacts are created and the artifact creators have to know what they are. Examples used include inventory tools discovering an app on an endpoint and being able to discover the apps software identifier to attribute to it for inventory purposes, or a vulnerability researcher being able to known the identifier of a piece of software when they make a record to document the vulnerability.
Support granularity of data artifacts - meaning different artifacts deal with different levels of granularity for software. Examples provided include inventory scanners listing a specific version of software where a vulnerability report such as CVE’s may list a range of software rather than just a single version. CISA points out that software identification formats need the ability to be precise (such as a single version) but also broad (ranges of software versions).
Recall how we discussed one key requirement for “making identifiers available when and where needed”. Some of the leading identification formats, such as CPE have challenges on this front, because as CISA points out, the CPE isn’t created until after vulnerabilities are discovered in a piece of software.
This means initial vulnerability reports can’t list a CPE identifier until one is created, and the same goes for inventory tools capturing net new software which may not have a historical track record of CVE’s in the NIST National Vulnerability Database (NVD) and therefore may not have a CPE to apply to it.
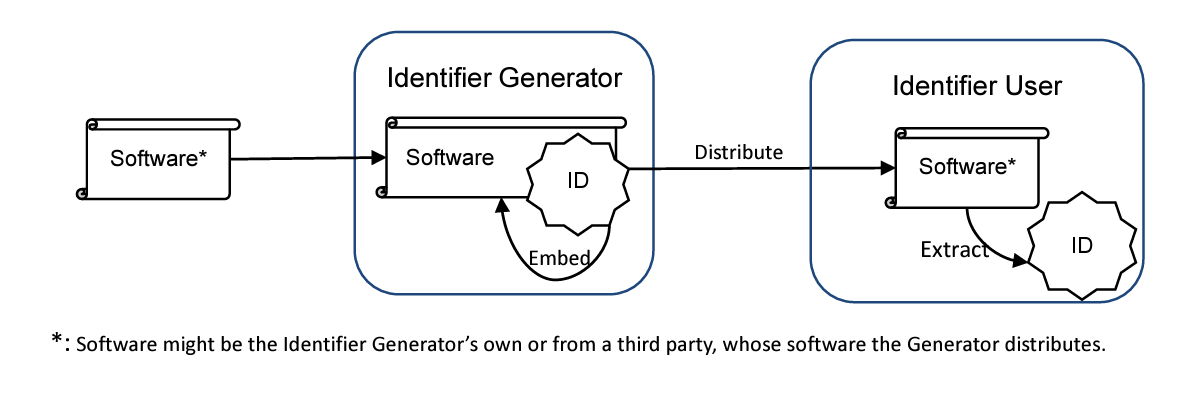
CISA also points out that even when/if identifiers exist, users may not have access to the identifier. They discuss two potential paths, differing with where the software identifier is generated, let’s take a look at each:
Inherent Identifiers - can be generated by any party at any time, and are generated based on the inherent properties of a piece of software, and can be done by anyone with a copy of the software/component
Defined Identifiers - these are only created by certain parties and at a specific point in time. The centralized party then publishes the association between the identifier and the software so others can use it.
The current software identification ecosystem has examples of each and as the paper mentions, each has its unique advantages and disadvantages.
On one hand, it is great to have a situation where anyone with a piece of software can generate the identifier. This is a distributed model that avoids some of the bottlenecks that can occur with a centralized identification authority. However, this also infers everyone follows the same processes, uses the same tools/approaches and ensures the generated identifiers make it to some centralized database(s).
On the other, a centralized model ensures a standardized approach and a central authority/repository where the entire ecosystem can go to identify a particular piece of software. However, this comes with significant administrative overhead, a demand for resources and puts the burden on one entity, versus the broader ecosystem.
Each approach has merit.
CISA doesn’t necessarily advocate for one approach over the other, and even states a path may be having multiple identification formats in a long term scenario. I will attempt to quickly summarize some of the potential paths they mention in the paper.As they mention, each path has potential value and tradeoffs. They point out that the current ecosystem has various identification formats that meet a subset of the various software use-cases, but not all of them.
There could be a long term path that is a single identification scheme that meets all of the diverse requirements, or perhaps a path where multiple identification schemes are needed indefinitely due to the various diverse use cases our ecosystem demands.
Path 1: Inherent Identifiers
Remember, this is a scenario where anyone with a piece of software can deterministically determine the identifier, such as by using hashes of files (e.g. SHA1 or SHA256).
This paths means no special knowledge is needed to generate the identifier!
Challenges CISA lay out include large multi-file applications where some components of the application may change but not all of them, or where large applications potentially have hundreds of files, some specific to each install and unless all aspects of the application are input into the generating activity, disparate identifiers would be produced.
To get the same output, every party would have to use exactly he same process and same collection of files, every time.
Another challenge is software is often discussed in context that is not inherent (e.g. name, vendor etc) which are applied in a social context, as opposed to inherent to the software itself from a mechanical perspective. CISA also mentions that today’s inherent identifiers don’t capture properties that define common software groups.
They recommend either innovating on an existing inherent identifier or devising a new one that can tackle these challenges/gaps. The benefit of this path would be no single entity is responsible for creating identifiers for the entire ecosystem and anyone with the software can generate the identifier.
Path 2: Defined Identifier
Moving beyond Inherent Identifiers is the path of Defined Identifiers. Recall these are when a party declares an associate between a piece of software and an identifier. The designated party binds the two. This means the party must publish the designated identifier so other parties can use it.
Examples of Defined Identifiers include CPE, PURL and SWID as mentioned earlier in this article.
CPE’s have various fields reflecting properties of the software, SWID uses Globally Unique ID’s (GUID)’s and PURL using Uniform Resource Identifiers (URI)’s.
The two challenges CISA calls out for this identifier type are:
The need for the centralized authority who bears the burden of creating the identifiers and binding them to software and publishing for the ecosystem to reference.
Parties/consumers/users need a way to learn about the identifier (e.g. delivered with the software, available in a database etc).
This identifier type is less structure specific and more process and workflow oriented, since it is something centralized authorities due, as opposed to everyone independently.
The CISA paper raises concerns about the centralized approach, and this is valid, given we see similarities with Vulnerability Databases, where NVD for example bears the burden, has been cited as having resource constraints, faced scrutiny over its processes and faces various competing databases (e.g. OSS Index, OSV etc).
Various sub-paths are proposed to potentially make this model effective and realistic. I will briefly touch on them below, but recommend visiting the paper itself to more thoroughly understand them.
Path 2: Unmanaged, Distributed Model - In this path many parties generate identifiers without oversight and coordination. It distributes the workload so no single party bears the burden solely on their own. Requires actions such as:
Generator specific markings in identifiers
Clear division of the software space among generators
Pushing identifiers with software
Minimize required information in identifiers
Incentivize identifier creation
This path could maximize coverage of the software ecosystem through a collaborative of parties contributing.
Path 3: Managed, Distributed Model
This model has a central authority supporting and contributing to the activities of various software identifier creators. They would assign responsibility to create identifiers, provide the centralized repository and identify issues with the identifier ecosystem. Think of this entity as governing the distributed ecosystem of identifier generators. Given this model, it makes sense to potentially be a Government entity or non-profit of some sort.
Actions to make this plausible would include:
Generator-specific markings in identifiers
Clear division of the software space among generators
Pushing identifiers with software
Minimizing the required information in identifiers Incentivizing identifier creation
Ensuring the long-term operation of the centralized authority or governing body
The theory is the centralized governing body would be able to improve the overall quality of the identifier space while still taking advantage of a coalition of distributed identifier generators.
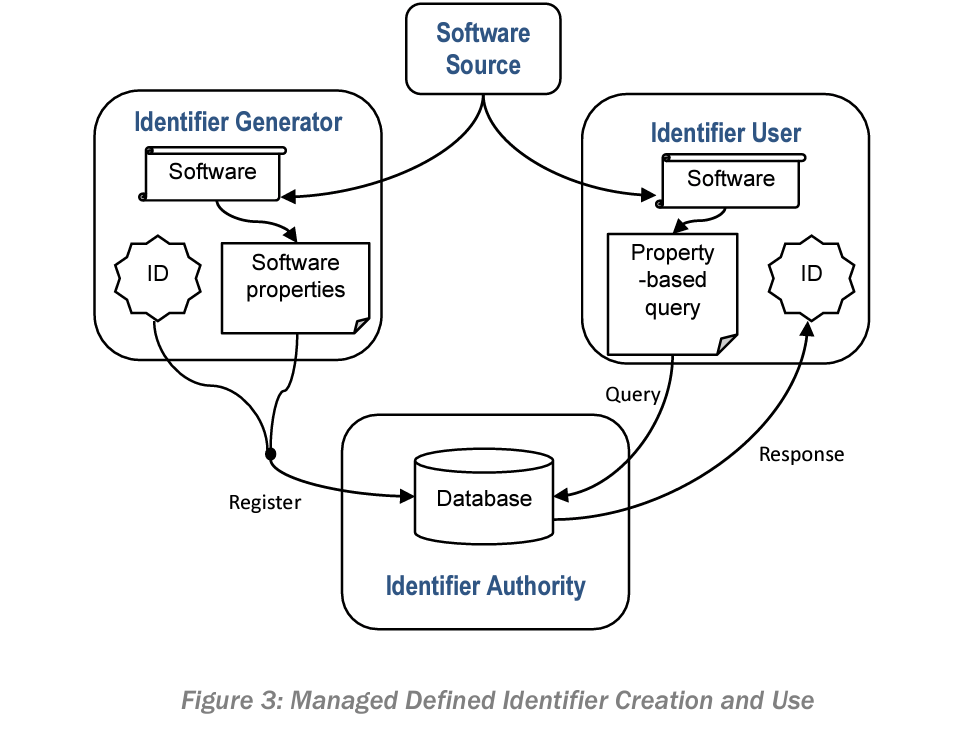
Path 4: Intermediate Models for Defined Identifiers
Think of Path 4 as a mesh of previously discussed paths, where you have a centralized authority and distributed authority of “federated nodes” to ensure effective external coordination.
Path 5: Unidentified Software Descriptor to Augment Paths 2,3 and 4.
This path addresses the need to identify previously unknown and unidentified software. It does this by “standardizing a structure to characterize unknown software”. This way rather than everyone encountering unknown software slapping an identifier on it in an ad hoc fashion, leveraging a standardized structure to characterize unknown software.
Think characteristics such as size, hash, software name, version etc. These data fields won’t become the identifier but allow for an approximate description and record linkage.
It is less precise of course but provides some level of descriptive elements in a defined standard structure. It essentially provides a fallback method to discuss software when it lacks a defined identifier.
Path 6: More Than One Software Identifier Format

Well, that was quite the adventure, and we’ve arrived at the final path discussed in the paper which is, as you guessed it, using more than one software identifier format.
The paper states that while one identifier could theoretically work and would be ideal, there are paths where a successful identifier ecosystem exists using multiple identifier formats (which some could argue we have now, despite gaps and depending on how we define “success”).
Concerns raised here include over-identification, or disparate naming scenarios where a single piece of software could, and does have multiple inherent identifiers. It doesn’t take much thought to see how this could be problematic.
Compare it with similar scenarios, where we’re looking at vehicle crashes or theft or recalls and using multiple different vehicle ID’s, and VIN’s to describe the same vehicle, or in the criminal and social domain where a single individual goes by multiple disparate social security numbers (SSN)’s.
This complicates activities such as software asset inventory, vulnerability management, incident response, software supply chain security and more.
Challenges with multiple formats include multiple central authorities that must now collaborate and avoid overlap in coverages or users/organizations querying multiple disparate databases to find associated identifiers for a single piece of software (go back to our example of multiple vulnerability databases like we have now).
That said, the paper does mention that multiple defined identifier formats and stakeholders allows for broader software identification coverage across the ecosystem, even if it leads to complication and issues as mentioned above.
The paper concludes this section stating that no single identifier format meets all of the various availability and granularity requirements, leaving us with the current disjointed and disparate identifier ecosystem we have now and its associated gaps and challenges.
Conclusion
What will the future look like? Will we rally around Inherent Identifiers, Defined Identifiers, a single identification format, or multiple identifier formats with different identification entities and stakeholders?
I’m not sure, but safe to say like anything else in software and cybersecurity, as it turns out, its complicated.
Despite the presence of software in everything from your personal phone, home electronics, water treatment facilities, electrical grid, and increasingly powering weapons systems in the national security space - we lack a unified singular approach to discuss these abstract pieces of code that operate opaquely, powering nearly every aspect of modern society.
So what’s in a name?
As it turns out, a lot, and it’s complicated.