
The Data Layer Is the New Battleground for the Agentic SOC

The Data Layer Is the New Battleground for the Agentic SOC
The per-gigabyte pricing model that defined the SIEM for the past fifteen years was never really a storage decision, it was a coverage decision.
Security teams learned to ration data because ingestion costs forced them to, and the consequence of that rationing was entirely predictable. Logs got sampled, retention windows shrank to days or weeks, and high-volume sources like DNS, VPC flow, and netflow were exiled to S3 buckets where they sat effectively dead, queryable in theory but inaccessible in any timeframe that matters for detection or investigation.
You cannot detect what you never ingested, and you cannot investigate what you could not afford to keep.
That tension has always sat at the center of the SIEM’s economic model, and for years the industry treated it as a budgeting problem rather than a security architecture problem. It also made organizations implicitly accept risks due to cost considerations and constraints.
The conversation has shifted in 2026 because two forces are converging at once. The SIEM monolith is unbundling into best-of-breed layers, and the arrival of agentic AI in the SOC is making complete, queryable security data a hard operational requirement rather than a nice-to-have.
The Unbundling
The traditional SIEM bundled five functions into a single platform, handling ingest, storage, detection, investigation, and response.
That monolithic design made sense when log volumes were manageable and the primary consumer of the data was a human analyst running manual queries. It doesn’t hold up when organizations generate terabytes of security telemetry daily and the fastest-growing consumer of that data is an AI agent that needs sub-second query response across months or years of logs.
What’s happening now is the same decomposition that hit the data analytics world roughly a decade ago with the rise of Snowflake and Databricks, where storage decoupled from compute and the “lakehouse” architecture became the dominant pattern. Security is arriving at this same architectural inflection late, which itself is telling.
Cybersecurity has a consistent pattern of being a laggard culture when it comes to adopting architectural shifts that adjacent disciplines validated years earlier, a point I’ve made at the SANS AI Summit and one that keeps proving itself.
The unbundled security stack has distinct layers emerging. A data lake layer handles storage and indexing. A detection-as-code layer runs rules against that data. An automation and orchestration layer, occupied by platforms like Torq and Tines, handles response workflows, and increasingly, an agentic layer sits on top, with AI agents consuming all three layers below through protocols like MCP.
The through line across all of it is the same principle, which is decoupling storage from compute so that the economics of keeping data doesn’t dictate the economics of using it and organizations don’t have to implicitly accept as much risk due to cost constraints.
Why Now
Three forces are driving this shift from theory to operational reality.
The first of those forces is volume. Cloud-native architectures, container orchestration, API-driven microservices, and distributed workloads generate orders of magnitude more telemetry than the on-prem environments the SIEM was originally designed to monitor.
Organizations running modern cloud infrastructure routinely produce terabytes of security-relevant logs per day, and the per-GB pricing model of legacy SIEMs makes ingesting all of it financially impossible. The rational response, and the one most security teams have adopted, is to drop, sample, or shorten retention on the highest-volume sources. The result is a detection gap that’s driven by economics, not by technology.
The second is the lakehouse pattern itself. The data analytics industry proved years ago that separating storage from compute allows organizations to keep everything and query it on demand without paying for always-on compute against cold data. Object storage in S3 or GCS costs a fraction of what SIEM-managed storage costs, and serverless compute can be invoked at query time and dismissed when the job finishes.
The architectural pattern is proven and the cost savings are real, but security tooling has been slow to adopt it because the query patterns are different. Security investigations require full-text search across semi-structured and unstructured data, not the SQL-based reporting that analytics platforms were optimized for.
The third, and the one that changes the urgency calculus, is the agentic inflection. As I wrote in “Beyond the Hype of AI Agents in the SOC”, the conversation around AI in security operations has moved from copilots assisting analysts to autonomous agents conducting investigations, triaging alerts, and executing response workflows with minimal human oversight.
AI agents are data-hungry by nature. They don’t sample, and they don’t accept a 15-day retention window. They need complete, fast, queryable access to the full breadth of security telemetry, and they need it in sub-second response times because an agent iterating through a triage workflow might run dozens of queries in a single investigation. The old SIEM only ever exposed the fraction of data that fit the budget, and that fraction is insufficient for the agentic model.
What Scanner Is
To ground this in a concrete example, Resilient Cyber’s partner Scanner.dev is a security data lake built from the ground up to solve the storage-compute coupling problem.
Founded by Cliff Crosland and Steven Wu and backed by a $22 million Series A led by Sequoia Capital with participation from CRV and Mantis VC, Scanner’s architecture indexes logs directly in the customer’s own S3 or GCS buckets using inverted index files that compress to roughly 15% the size of the original dataset.
At query time, Rust-based AWS Lambda functions traverse those index files at speeds up to 1TB per second, scanning only the data regions relevant to the query rather than brute-forcing through the entire dataset.
The practical difference is stark, and it’s easy to see the potential for practitioners. In a demo I saw with Cliff, a query across 1.15 petabytes of log data returned results in seconds, a job he estimated would take Amazon Athena roughly 12 hours.
Ramp, the financial operations platform, moved from Athena queries that took 30 minutes to Scanner queries that run in under two minutes, while simultaneously extending their searchable data retention from 15 days to a full year. Lemonade went from 7-30 days of accessible logs, with expensive rehydration fees for anything older, to months of instantly queryable history.
From my discussion with Cliff, the schema-less design is deliberate. Scanner doesn’t require the ETL work that SQL-based analytics tools demand. It indexes messy, semi-structured, and unstructured logs without forcing them into rigid table schemas, which eliminates the data engineering overhead that has historically made security data lake projects stall before they deliver value.
On the detection side, Scanner provides over 400 out-of-the-box detection rules managed through GitHub, following the detection-as-code pattern that treats security logic the same way engineering teams treat application code.
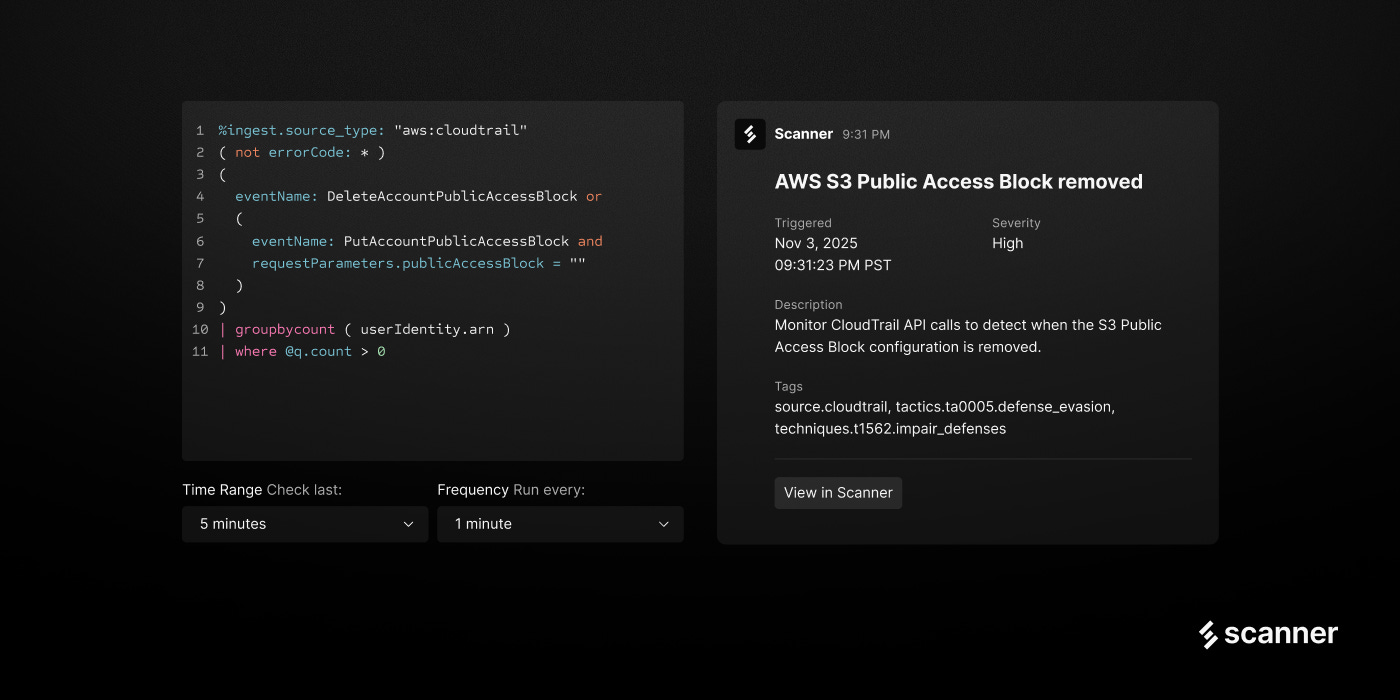
Rules are pre-run and cached at indexing time so that detection logic doesn’t degrade search performance. The platform includes Scanner Collect for data source ingestion, RBAC for access control, and offers both a fully managed deployment and a bring-your-own-cloud model where compute runs entirely within the customer’s AWS account.
The pricing reflects the architectural difference as well. Scanner charges approximately $0.10 per million log events for detection rules, compared to roughly $5 per million at competitors offering similar platforms. For an organization analyzing a terabyte of logs daily, that translates to roughly $40,000 per year versus $1.8 million. The typical deployment runs $50,000-$100,000 for a 250TB dataset, which is 80-90% less than standard SIEM pricing for equivalent data volumes.
The data-stays-in-your-cloud posture is a deliberate trust and data gravity play and one I discussed specifically with Cliff during the demo. With the BYOC model, the customer retains full control over their data at all times, and switching away doesn’t require migrating petabytes of logs out of a vendor’s infrastructure. This was a specific design choice that Cliff pointed out in our discussion, and it gives organizations more control of their own data while minimizing concerns over vendor lock-in.
The Agentic Bet
This is Scanner’s most ambitious and testable claim. Within weeks of releasing their MCP server, nearly one-third of customers were already using it in production, and Cliff told me that agents now account for 80% of weekly queries on the platform. The heaviest users of the security data lake aren’t human threat hunters. They’re AI agents conducting investigations around the clock.
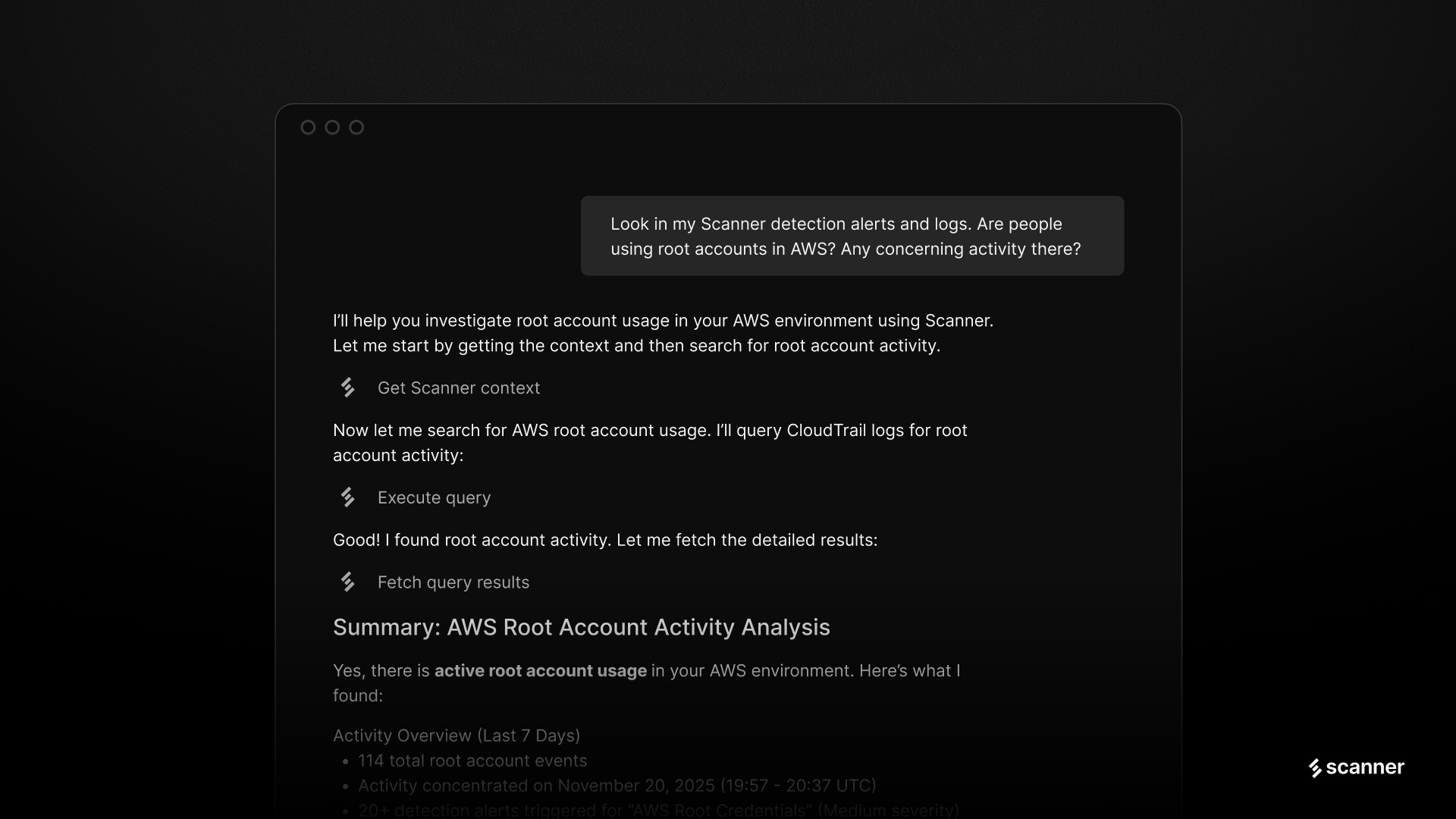
Notion’s security team built Scruff, an AI agent that uses Scanner as its primary data layer alongside integrations with Wiz and CrowdStrike Falcon. Scruff autonomously triages and investigates security alerts, correlates findings across logs, user activity, and system events, and saves the team over six hours per week. It handles the workload of multiple on-call analysts and scales automatically as the company grows, the kind of force multiplication that makes the agentic SOC argument concrete rather than theoretical.
Sequoia’s Bogomil Balkansky framed Scanner as “the only technology on the market today that manages security data at AI scale” when leading the Series A. That claim rests on a specific architectural argument. Traditional SIEMs and even newer data lake tools like Athena and Presto weren’t built for the iterative, exploratory query patterns that AI agents use.
An agent investigating an alert might run 20-30 queries in rapid succession, each one refining a hypothesis based on the previous result. If each query takes 30 minutes, the agent is useless. If each query returns in seconds, the agent can conduct a thorough investigation faster than any human analyst.
This connects to the broader argument I’ve been making about where the real value sits in the agentic SOC. As I explored in “AI SOC Got Commoditized, Now What?”, the agent itself is rapidly becoming a commodity.
Every major security vendor is shipping some version of an AI-powered SOC agent, and the differentiation between them is narrowing. If the agent layer commoditizes, the durable value shifts to the infrastructure the agent depends on, and that infrastructure is the data layer. The agent is only as good as the data it can access, the speed at which it can query, and the completeness of the telemetry underneath it.
Where the Agentic SOC Goes from Here
The broader question isn’t about any single vendor’s roadmap. It’s about whether the industry recognizes that the data layer has become the constraining factor in how far the agentic SOC can go.
The early signals are starting to suggest it has. Security data lakes are increasingly serving as the infrastructure layer not just for in-house security teams but for AI-focused MDR providers building their own agent-driven products on top. I’ve previously worked with teams building security data lakes in large Federal enterprise environments and it is a complex endeavor, often requiring expertise beyond cyber into data science and other domains as well.
The pattern of deploying a data lake as a companion alongside an existing SIEM, offloading the highest-volume sources that the budget can’t justify ingesting at SIEM pricing, is already well-established. The more interesting question is what happens when organizations start running the majority of their detections and investigations on the data lake layer rather than the SIEM, and the SIEM’s role atrophies from platform to legacy integration point. That trajectory, from cost optimization companion to primary detection and investigation surface, will define the category over the next few years.
Detection-as-code managed through Git repositories represents a parallel bet on the continued convergence of security operations and software engineering practices and mimics what we’re seeing in other categories of cyber as well, such as the rise of GRC Engineering.
If SOC teams adopt GitOps workflows for managing their detection logic, the operational model for building and maintaining detections starts to look more like software development than it does like traditional rule management. As I discussed with Vineeth Sai Narajala in “MCP, Potential and Pitfalls”, MCP is growing at an extraordinary rate as the standard interface between AI agents and the tools they operate, and that growth accelerates the shift toward agent-consumable infrastructure across the SOC.
The organizations that expose their security telemetry through agent-friendly interfaces will be the ones whose agents can actually perform, and the organizations that keep their data locked behind slow, expensive, human-oriented query tools will be the ones wondering why their AI investments aren’t delivering results.
Data residency and control are also becoming a structural differentiator rather than a niche concern. As regulatory pressure around data sovereignty and third-party risk continues to build, keeping security telemetry in the customer’s own cloud environment rather than shipping it to a vendor’s SaaS platform becomes a genuine architectural advantage for organizations in regulated industries.
The bring-your-own-cloud (BYOC) model addresses the trust problem that has made enterprise security teams hesitant to move their most sensitive telemetry to external platforms, and it eliminates the vendor lock-in that makes switching costs a strategic liability, something I called out with Cliff as a common concern I hear among CISO’s.

The Architecture Decision in Front of Every CISO
The question facing security leaders in 2026 isn’t which SIEM to buy. It’s whether to keep treating security data as something to ration or as infrastructure to query freely. The SIEM’s per-GB pricing model created a world where security teams made coverage decisions based on budget constraints rather than risk analysis, and the result was exactly the blind spots that attackers learned to live in.
The security data lake doesn’t solve every problem in the SOC. Detection engineering still requires skilled practitioners. Incident response still demands human judgment for high-stakes decisions, and the agentic SOC, for all its promise, is still early enough that the failure modes aren’t fully understood, something I explored in “Orchestrating Agentic AI Securely”.
But the data layer underneath all of those functions is no longer optional, and the economics of the old model are no longer defensible. When the most prolific users of your security data are AI agents that need sub-second access to complete telemetry, the cost of rationing isn’t just a budget line item. It’s a detection gap, an investigation bottleneck, and increasingly, the ceiling on what your agentic SOC can actually accomplish.
The organizations that figure out the data layer first will have a structural advantage in the agentic era, and the ones that keep rationing will keep wondering why their agents can’t find what they’re looking for, and potentially are missing critical risks to their organizations.
Making the right choices here will help define the true transformation that agents can deliver for SecOps.