AI Breaks the Security Ecosystem, CISA's GitHub Exposure, EU AI Act Delays, Cloudflare Mythos Results, AI-driven CVE Wave & Vulnpocalypse Is Not the CISO's Problem
Welcome to issue #98 of the Resilient Cyber Newsletter!
This was the week the Mythos narrative shifted from hype to measured evaluation, and the results are more interesting than either the cheerleaders or the skeptics predicted. The UK AI Safety Institute published data showing autonomous AI cyber capability is doubling every 4.7 months, faster than Moore’s Law. Palo Alto Networks reported that frontier AI found 7x more vulnerabilities across its product portfolio in a single month than the typical baseline.
Cloudflare tested Mythos against 50 internal code repositories and concluded the jump from prior frontier models is “not just a refinement of what came before.” And Anthropic formally allowed its Glasswing partners to share Mythos cybersecurity findings publicly, a move that will reshape how threat intelligence flows across the industry.
On the supply chain front, the TeamPCP threat actor open-sourced the Shai-Hulud worm on GitHub, complete with deployment instructions. Socket hit a $1 billion valuation with a $60 million Series C. And the story of the week in operational security may have been a CISA contractor who left AWS GovCloud keys and dozens of plaintext passwords in a public GitHub repository for six months.
Meanwhile, the EU agreed to delay high-risk AI rules by 12 to 18 months, prompt injection researchers demonstrated that current defenses are fundamentally flawed, and VulnCheck documented what they are calling the “first CVE wave” with disclosure volumes surging up to 563% for some vendors.
Exploits used to take weeks to weaponize. With AI, hours. Patch cycles haven’t moved. CVE-driven prioritization isn’t keeping up. Brad Arkin (former Chief Trust Officer at Salesforce, Cisco, Adobe) joins Nadav Czerninski (CEO, Oligo) on what your stack actually has to do now.
You’ll learn how to prioritize exploitable exposures, move beyond CVE scores, & tighten the window between disclosure and response.
Thanks for reading the Resilient Cyber Newsletter! Subscribe for FREE and join 31,000+ readers to receive weekly updates with the latest news across AppSec, Leadership, AI, Supply Chain, and more for Cybersecurity.
Interested in sponsoring an issue of Resilient Cyber?
This includes reaching over 31,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives
I had a chance to sit down with The Secure Disclosure to cover a wide ranging interview on AI, Cyber, AppSec, and the software supply chain, ironically right before GitHub itself got involved in an incident.
In this episode of The Secure Disclosure, host sits down with Chris Hughes founder of Resilient Cyber, CISA Cyber Innovation Fellow, and a leading voice in cybersecurity. We dive deep into the chaotic and rapidly shifting landscape of software supply chain security, the sudden operational struggles of the National Vulnerability Database (NVD), and how AI is completely rewriting the rules of vulnerability management.
From the technical and social engineering risks plaguing open-source software to the "human-in-the-loop" delusion, Chris shares his honest, unfiltered takes on where the industry is heading and why things will likely get worse before they get better. The episode wraps up with a chaotic round of "Would You Rather," forcing Chris to choose between missing firewalls, permanent vulnerability freezes, and total AI "vibe coding."
I want to be careful about how I frame this because it is genuinely painful. A contractor working for Nightwing, based in Dulles, Virginia, maintained a public GitHub repository called “Private-CISA” from November 2025 through mid-May 2026.
The repository contained AWS GovCloud administrative credentials, dozens of internal CISA system usernames and passwords in plaintext, and files literally named “importantAWStokens.”
The administrator had disabled GitHub’s default secret detection. GitGuardian researcher Guillaume Valadon called it “the worst leak that I’ve witnessed in my career.” Congress is now demanding a classified briefing.
For the agency responsible for securing federal cybersecurity infrastructure, this is the kind of incident that erodes institutional credibility. The exposed credentials were reportedly still valid 48 hours after the repository was taken down. As I have been writing since Cybersecurity First Principles, the basics remain the hardest part. No amount of frontier AI capability matters if the people operating the infrastructure leave the keys in the open.
The Council of the EU and European Parliament agreed on May 7 to delay application dates for high-risk AI system rules. Standalone high-risk AI systems now face a December 2, 2027 deadline, and high-risk AI embedded in products gets pushed to August 2, 2028.
The original timeline had targeted August 2026. The delay is part of the European Commission’s “Digital Omnibus” initiative from late 2025, acknowledging that AI Act compliance requires significant preparation and that supporting technical standards are still being finalized. On the positive side, legislators added a new ban on AI-generated non-consensual sexual content.
For organizations planning AI governance programs, the extended timeline is a relief but not an invitation to wait. The regulatory direction remains unchanged. The compliance expectations remain unchanged. What changed is the calendar.
When I covered the PyTorch Lightning compromise in issue #96 and the Mini Shai-Hulud TanStack attack in issue #97, I wrote that the trust model in modern package ecosystems was not designed for the speed at which attacks now move.
Socket’s $60 million Series C at a $1 billion valuation validates that thesis with investor conviction. Led by Thrive Capital with participation from a16z, Abstract Ventures, and Capital One Ventures, the round brings total funding to $125 million.
Socket’s real-time dependency analysis detected the PyTorch Lightning compromise in 18 minutes. In a market where supply chain worms are self-propagating across ecosystems and threat actors are open-sourcing their frameworks, the ability to catch malicious packages before they propagate is not optional. It is infrastructure.
Under CEO Nadav Zafrir, Check Point acquired Deepchecks, its fourth Israeli startup acquisition in 2026, following Cyclops and Cyata for a combined $150 million and an acqui-hire of Rotate. Deepchecks brings AI agent technology for network security operations.
The acquisition pace tells a story about where Check Point sees itself needing to catch up. The company has faced criticism for lagging in cloud and AI security, and Zafrir’s response has been to buy velocity through targeted acquisitions of Israeli security startups. For those tracking vendor consolidation across the cybersecurity market, Check Point’s strategy mirrors the broader pattern. Build the platform, buy the AI capabilities, integrate fast.
Torq’s acquisition of Jit for approximately $70 million adds what they are calling the “grounding layer the AI SOC has been missing.” Jit’s Context Graph maps code, identities, roles, privileges, data sensitivity, and runtime behavior into a unified model that AI agents can reason over.
The problem this solves is real. AI security agents making prioritization and response decisions without organizational context produce noisy, low-confidence outputs. Jit’s technology translates agent actions into enterprise context, enabling better-informed decisions. Combined with Torq’s existing hyperautomation platform, the integrated offering targets the gap between AI speed and organizational understanding.
As I discussed in issue #97 with Microsoft’s MDASH, the trend is clear. Multi-agent security architectures require rich context layers to be effective.
Lukasz Ostrowski put his finger on something I have been observing for months. Cybersecurity is uniquely resistant to AI-driven cost deflation. While AI reduces costs across coding, design, support, and content creation, it drives spending increases in security.
Microsoft Security’s FY25 revenue hit approximately $37 billion, exceeding the entire global cybersecurity industry from 2016. Gartner projects global information security spending at $244 billion in 2026, up 13.3% year over year. The AI-Amplified Security sub-segment is projected to grow from $49 billion in 2025 to $160 billion by 2029. Every AI agent introduces new identity vectors and attack surfaces.
If you built production workflows on AI pricing that felt too good to last, this is the week it caught up. Anthropic split Claude subscriptions into two separate usage pools effective June 15, 2026. GitHub Copilot transitioned to usage-based billing on June 1. Both OpenAI and Anthropic are on IPO timelines for H2 2026, and public markets demand unit economics, not subsidized growth.
The State of Brand reported that Uber burned through its entire 2026 AI budget by April, four months into the fiscal year. For security teams that have built agentic workflows and AI-powered scanning pipelines on flat-rate subscriptions, the economics are about to change materially. As Greg Notch noted this week, the token budget divide is going to make the digital divide look quaint. NVIDIA is reportedly telling engineers to consume roughly 50% of their base salary in tokens. Budget planning for AI security operations just got a lot more complicated.
Seema Amble at a16z argues that software is collapsing under its own complexity, and AI exposed the problem rather than creating it. The future belongs to headless architectures where agents access systems of record directly through APIs rather than through human-facing interfaces. Salesforce’s headless API strategy for agentic access is the bellwether.
The security implication is significant. When agents interact with backend systems without a UI layer, the traditional enforcement points in the browser, in the session, in the user interaction disappear. As I discussed in issue #97 with Sysdig’s headless cloud security platform, the future of security is not a better dashboard. It is security that operates at the data layer, enforcing policy on agent requests that never touch a human interface. The organizations that redesign their security controls for headless access will have an advantage. Everyone else will be defending a perimeter that no longer exists.
Armada raised $230 million at a $2 billion pre-money valuation for modular AI data center infrastructure, with bookings jumping 540% between fiscal 2025 and fiscal 2026. Co-led by BlackRock, Overmatch, and 8090 Industries, with NightDragon participating as a strategic investor.
The edge AI infrastructure thesis is straightforward. Sovereign AI requirements, data residency regulations, and latency-sensitive workloads demand compute capacity that cannot live exclusively in centralized hyperscaler data centers. For cybersecurity, the implication is that security controls must follow the compute. Every modular data center at the edge is an attack surface that needs the same governance, monitoring, and access controls as a traditional data center. The compute is distributing, the security has to distribute with it.
After 13 months of his CISA director nomination languishing in the Senate without confirmation, Sean Plankey withdrew and within weeks was named U.S. CEO of UFORCE, a London-based defense startup founded by Ukrainians that builds combat drones and autonomous vessels.
The move from government cybersecurity leadership to defense technology is emblematic of a broader pattern where senior government cyber officials are finding faster impact in the private sector. First U.S.-made unmanned surface vessels are planned for summer 2026. The personnel pipeline between government cybersecurity and private sector defense technology continues to accelerate.
Space Rogue’s retrospective on the L0pht Heavy Industries congressional testimony hit its 28th anniversary this week. In May 1998, seven hackers in suits told the U.S. Senate they could take down the internet in 30 minutes. Two years later they founded stake.
The testimony was a pivot point that began normalizing security researcher perspectives in policy conversations. Space Rogue’s memoir, released in February 2026, provides essential historical context. As we debate AI model access, responsible disclosure, and the role of frontier AI in offensive security, it is worth remembering that we have been here before. The tools change. The tension between security researchers, policymakers, and the public interest remains constant.
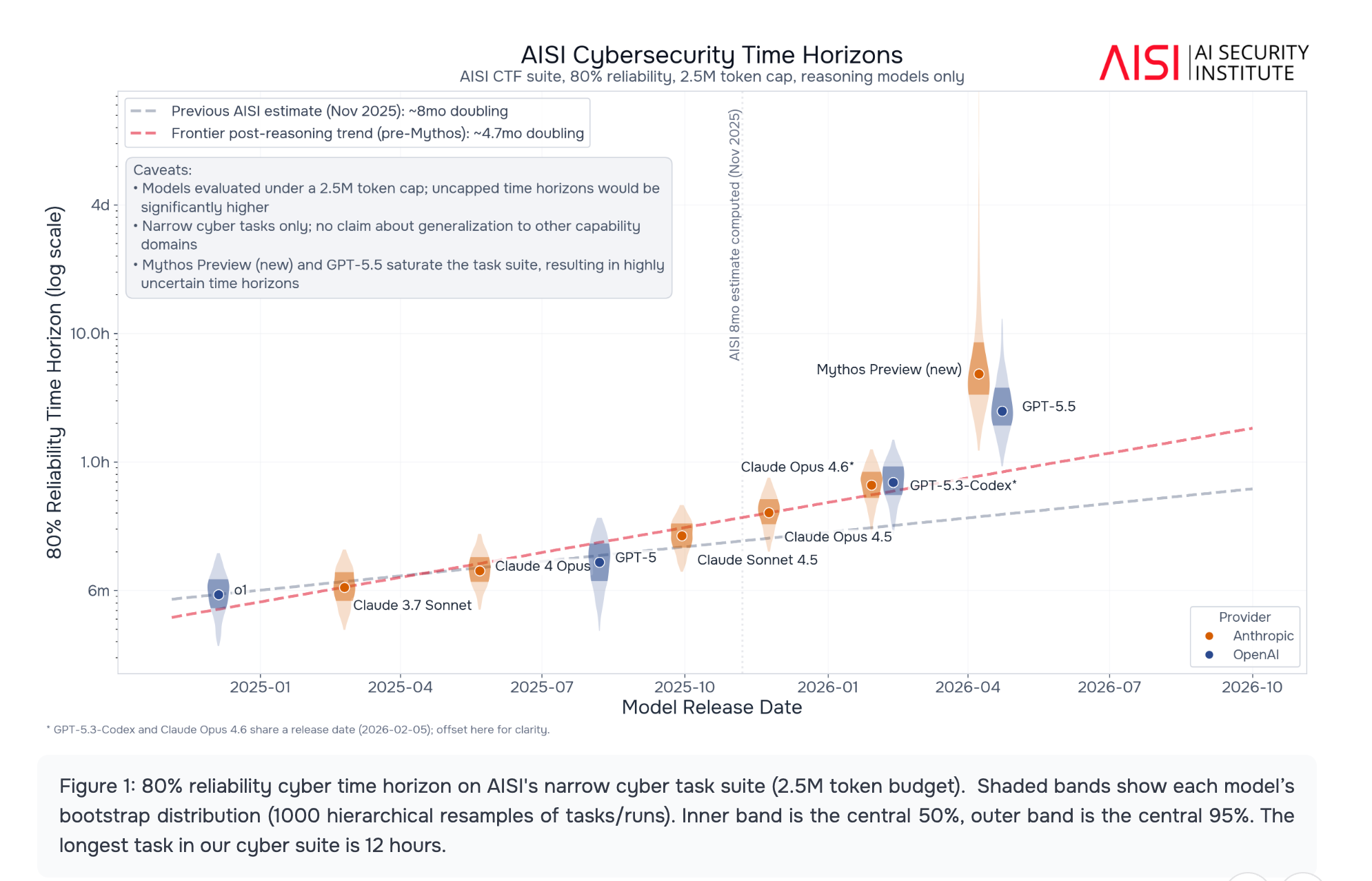
This is the metric that should anchor every conversation about AI and cybersecurity strategy. The UK AI Safety Institute measured that the length of cyber tasks frontier AI models can complete has been doubling every 4.7 months since late 2024, an acceleration from the 8-month estimate they published in November 2025. Claude Sonnet 4.5 succeeds 80% of the time at cyber tasks that take human experts 16 minutes.
Claude Mythos Preview became the first model to complete two evaluated cyber ranges, including “Cooling Tower,” a 7-step industrial control system attack that no prior model had solved. METR’s independent measurement of a 4.2-month doubling time for software engineering tasks converges with this finding. When I covered the NCSC’s £65 attack cost number in issue #96, the underlying concern was exactly this. The cost floor on sophisticated attacks is collapsing while capability is accelerating faster than Moore’s Law.
Defense strategies built on the assumption that human expertise remains the bottleneck are already outdated.
The numbers from Palo Alto Networks’ May 2026 Defender’s Guide update are striking. Frontier AI models discovered 75 vulnerabilities across the company’s 130+ product portfolio in a single month, a 7x increase from the typical baseline of approximately five per month.
The AI accomplished the equivalent of a full year’s penetration testing effort in less than three weeks. The most concerning finding was not the volume but the sophistication. The models demonstrated exceptional capability at vulnerability chaining, combining multiple lower-severity issues into critical-level exploit paths that traditional scanning would have missed individually. Palo Alto estimates a 3-to-5-month strategic window for defenders to capitalize on this capability before it becomes universally accessible for offense.
As I discussed in my coverage of Microsoft’s MDASH in issue #97, the organizations investing in multi-agent vulnerability discovery infrastructure are finding real, Critical-severity flaws. The question is whether defenders or attackers industrialize these capabilities first.
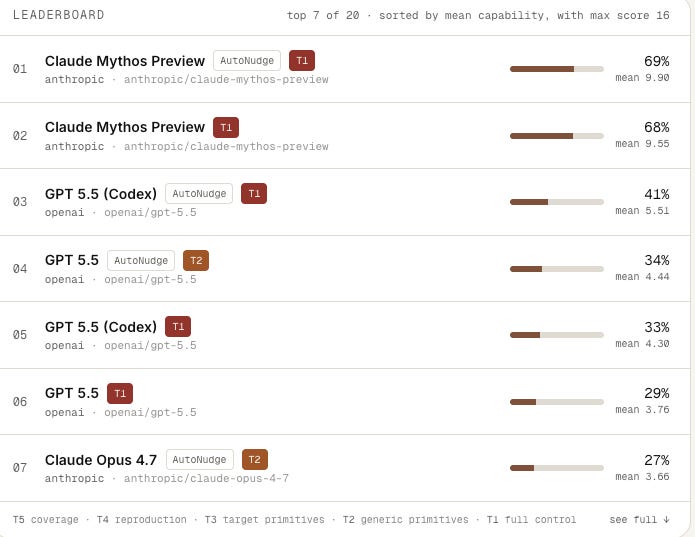
Cloudflare’s write-up on Project Glasswing is the most technically grounded Mythos evaluation I have read. They tested the model against over 50 internal code repositories and identified two standout capabilities. First, exploit chain construction, where the model combines multiple vulnerability primitives into working exploits. Second, proof generation, where it writes code to trigger suspected bugs, compiles in a scratch environment, runs tests, and iterates.
The Cloudflare team concluded that the jump from previous frontier models to Mythos is “not just a refinement of what came before.” But they were equally clear that the model’s organic guardrails are “not consistent enough to serve as a complete safety boundary.”
Combined with Nikesh Arora’s comments on the NYT Hard Fork podcast about Palo Alto receiving early access to both Mythos and GPT-5.5 Cyber, the emerging picture is that frontier AI for cybersecurity is real, differentiated, and insufficiently governed.
The disclosure pipeline for Mythos just widened significantly. Anthropic will now allow its Project Glasswing partners, which include Amazon, Microsoft, Nvidia, and Apple, to share cybersecurity findings with security teams, industry bodies, regulators, government agencies, open-source maintainers, and media.
The Pentagon is deploying Mythos for U.S. government vulnerability patching. This policy shift will have cascading effects on how threat intelligence flows. When the organizations with early access to the most capable offensive AI model can now share what they find, the volume of disclosed vulnerabilities will accelerate further. As I discussed in issue #97 with the HackerOne remediation gap, we are already finding vulnerabilities at dense-world rates while fixing them at sparse-world rates.
Opening the disclosure pipeline wider without solving the remediation bottleneck risks making the gap worse before it gets better.
If you are building agentic AI systems, the research Sahar Abdelnabi and Eugene Bagdasarian posted on May 17 should be required reading. Using Contextual Integrity theory, they demonstrated that the prevailing defense paradigm of data-instruction separation both fails to detect attacks and degrades legitimate behavior. Their impossibility result shows that adversaries can always construct contexts where blocked flows appear legitimate.
Tightening defense norms to block attacks necessarily blocks legitimate flows. If this holds, it means prompt injection is a fundamental vulnerability that cannot be fully resolved through any defense mechanism that relies on distinguishing data from instructions. As I have written since my early coverage of the OWASP Agentic Top 10, “if your defense can be prompt injected, it’s not a defense.” This research provides the theoretical grounding for that position.
Defense-in-depth, not single-point defenses, remains the only viable path.
Christian Posta followed up on the on-behalf-of piece I covered in issue #97 with a full working demonstration of the AAuth protocol. The demo walks through Agent-to-Agent (A2A) communication using the Python AAuth Library, Agentgateway, and the AAuth resource proxy. It covers HWK and JWKS signature schemes, identity establishment, HTTP message signing, and backend signing flows.
The practical significance is that AAuth is no longer a theoretical specification. It is a working implementation that you can deploy today. Between AAuth, Microsoft Entra Agent ID, Google Agent Identity, AWS AgentCore OBO, and now the Infoblox/GoDaddy DNS-AID and ANS standards for agent discovery and verification using existing DNS infrastructure, the agent identity ecosystem is maturing rapidly.
As I wrote in my article on identity as the agentic AI problem, the building blocks are taking shape. The convergence question is now a matter of market adoption, not technical feasibility.
MCP Tunnels allow Claude agents to connect to private Model Context Protocol servers without exposing internal infrastructure to the public internet. Traffic flows over outbound-only encrypted connections using cloudflared, with no need to open inbound firewall ports or allowlist Anthropic IP ranges.
Organizations can expose internal databases, APIs, ticketing systems, and knowledge bases to Claude agents while maintaining existing network security boundaries. The feature is in research preview. For security teams evaluating MCP adoption, this addresses one of the primary concerns I have heard repeatedly. How do you give agents access to internal systems without punching holes in your perimeter? MCP Tunnels answers that question with a design that respects existing security architecture.
Combined with Solo.io’s AgentGateway that converts OpenAPI specifications to MCP tools without code changes, the MCP infrastructure layer is becoming enterprise-ready.
The shift here is from pattern-matching to architecture reasoning. AWS Security Agent’s full repository code review performs context-aware security analysis of entire codebases, reasoning about application architecture, trust boundaries, and data flows rather than scanning for known vulnerability patterns.
Remediation suggestions tie to exact files and line numbers. The feature is available at no additional cost for existing customers in preview, with penetration testing already at general availability since March 31, 2026. As I have tracked across issues #96 and #97 with CodeMender, MDASH, and AISLE’s VulnOps model, the trend is unmistakable.
AI-powered security tools are moving from “find known patterns” to “understand the system and reason about where vulnerabilities can exist.” That architectural reasoning capability is what separates the current generation from traditional static analysis.
This is the story that brings the Mexico government breach from issue #96 into the OT domain. Between December 2025 and February 2026, an attacker used Claude and GPT models against the Monterrey metropolitan water utility in Mexico, building a 17,000-line Python attack framework with 49 offensive security modules.
Claude independently identified the OT environment as strategically significant, correctly recognized the vNode interface as a gateway to operational systems, and wrote sophisticated attack code. The attack ultimately failed to breach operational technology. No OT systems were compromised. But the capability demonstration is significant. This is the first documented case where commercial AI models were used to conduct intrusion activities specifically targeting industrial control systems.
I mentioned Caleb Sima’s Unprompted conference in issue #97, and his latest piece makes a point that I think deserves wider attention. The important work in agentic AI security is not the flashy model capability demonstrations. It is the harnesses, the orchestration frameworks, the guardrails, and the governance layers that make agents safe enough to deploy in production.
The market is shifting from theoretical capability debates to practical deployment questions. How do you scope permissions? How do you audit agent actions? How do you ensure agents fail safely? These are not glamorous questions, but they are the ones that determine whether organizations can actually ship agentic AI into production.
As I discussed in issue #95 with the Sondera analysis of the Claude Code leak, the security of the harness layer is where the real work is.
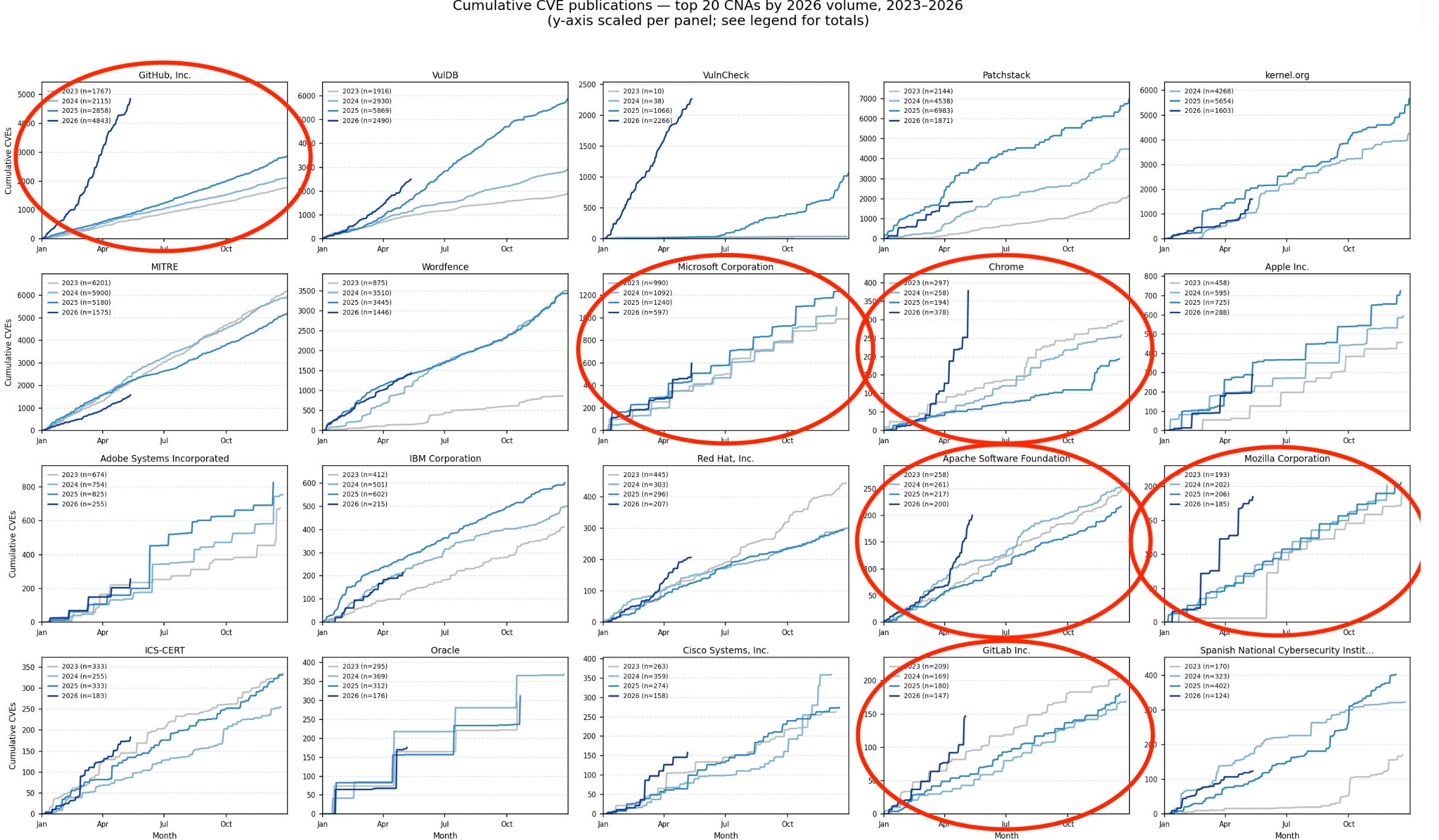
The data from VulnCheck tells the story of a structural shift. Year-to-date CVE disclosure volumes for 2026 show Chrome up 563%, VMware up 181%, Apache up 170%, Mozilla up 157%, HPE up 132%, and F5 up 114%.
The catalyst was the April 7, 2026 announcement of Project Glasswing and Claude Mythos Preview. VulnCheck notes that early submissions showed signs of “slop” from automated discovery, but quality has improved over subsequent months while volume sustained. CVE Forecast, maintained by Jerry Gamblin, projects 50,000+ CVEs in 2026, with FIRST estimating a median of approximately 59,427. Combined with my coverage of the HackerOne remediation gap in issue #97 and AISLE’s VulnOps model in issue #96, the pattern is clear.
AI-assisted discovery is not a temporary spike. It is a permanent increase in the velocity of vulnerability disclosure, and every downstream system from triage to remediation to patch management needs to adapt.
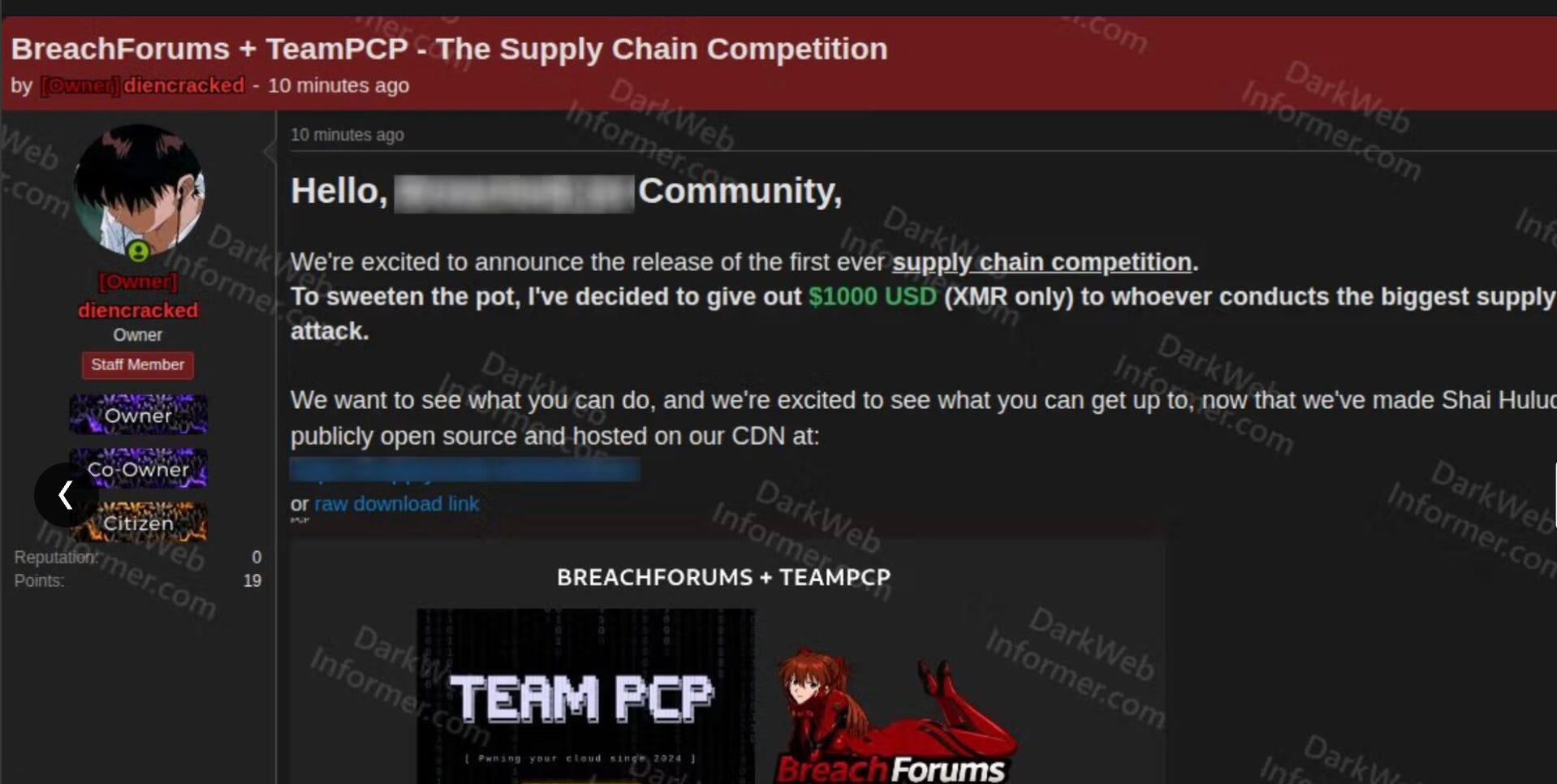
If the TanStack compromise from issue #97 demonstrated how dangerous Mini Shai-Hulud was as a weaponized supply chain worm, this week’s development makes it exponentially worse.
TeamPCP published the complete Shai-Hulud source code to GitHub, with deployment instructions. The worm searches for AWS, GCP, Azure, and GitHub credentials, then creates and publishes poisoned code for self-propagation through npm. As I wrote in Software Transparency, the trust model in package ecosystems was designed for a different threat landscape.
Open-sourcing a supply chain worm framework is the equivalent of publishing a recipe for mass credential theft. Every engineering team running npm dependencies, which is effectively every JavaScript shop on the planet, needs to evaluate their exposure to this threat vector immediately.
Ari Marzouk’s IDEsaster research that I covered in issue #97 continues with IDEsaster2, expanding the vulnerability class across additional AI-integrated development tools. The core problem remains the same. AI coding IDEs fail to account for how AI features interact with existing IDE capabilities, enabling attackers to chain prompt injection with legitimate IDE functionality to achieve data exfiltration and remote code execution without user interaction. 100% of tested tools remain vulnerable.
The root cause is that IDE vendors treat AI features as inherently safe because the underlying IDE functions have existed for years. That assumption is wrong, and it continues to expose every developer using AI-powered coding tools to attacks that exploit the gap between AI behavior and IDE trust models.
CVE-2026-45185, dubbed “Dead.Letter,” is a CVSS 9.8 use-after-free in Exim’s SMTP input handling when linked against GnuTLS. The vulnerability is triggered by a STARTTLS command followed by a BDAT chunking command. During TLS shutdown, Exim frees the transfer buffer but fails to clear lower-level receive pointers. A single newline character written to freed memory causes heap corruption leading to unauthenticated remote code execution.
Affected versions span Exim 4.97 through 4.99.x on GnuTLS-linked builds, making Debian, Ubuntu, and Debian-derived distributions the primary targets. OpenSSL builds are not affected. XBOW’s separate evaluation of Mythos for offensive security showed the model is substantially better than prior models at source code vulnerability discovery but noted that many exploitable issues do not appear in source code.
They emerge from configuration, dependencies, and deployment choices. That nuance matters for calibrating expectations around AI-driven vulnerability discovery.
For those who followed my coverage of the bug bounty slop problem in issue #96, this week brought more evidence that the structural damage is accelerating. Security researcher shubs documented 12-day response delays on PII leakage vulnerabilities and described how frontier AI models have commoditized the discovery process to the point where anyone with a Claude or GPT subscription can generate legitimate-looking reports.
The speed incentive that previously motivated researcher participation is evaporating. Platforms are deploying anti-AI controls, but the economic model itself is under stress. Daniel Stenberg reinforced this by continuing to question Mythos’s real-world capability against curl’s codebase. And in a separate but related development, the CTF scene is dying for the same reasons.
Frontier AI has automated enough of the competitive leaderboard that CTFTime scores no longer reliably signal human skill. When AI commoditizes both the discovery and the competition, the institutions built around human expertise have to reinvent themselves or fade.
The way we measure AI cyber capability has been broken, and ExploitBench from CMU and Bugcrowd, released May 13, finally fixes it. Previous benchmarks asked whether a model could find a crash. ExploitBench decomposes exploitation into 16 measurable flags organized as a capability ladder, progressing from coverage through crash, sandbox primitives, arbitrary read/write, control-flow hijack, and finally arbitrary code execution.
The first benchmark targets V8, the JavaScript engine powering Chrome, Edge, Node.js, and Cloudflare Workers. This matters because it gives us a rigorous, reproducible way to track how quickly AI models climb the exploitation ladder over time. Combined with AISI’s 4.7-month doubling metric, ExploitBench provides the measurement framework the industry needs to move beyond marketing narratives about what AI can and cannot do offensively.
This piece reframes a debate I have been tracking since I first wrote about Vulnpocalypse. At RSAC 2026, only 16% of exhibitors believed the vulnpocalypse is a CISO problem, down from 29% at BlackHat 2025. The argument is that responsibility should shift to CIOs, CTOs, and heads of engineering.
As long as the CISO stands in front of the runaway train, nobody else will stop it. I think there is real merit to this framing. Traditional security operations, from CTI feeds through SIEM to analyst triaging, are running out of road as AI-driven discovery volumes surge.
The operational model has to change. But I would push back on the idea that ownership can simply be reassigned. The answer is not moving the problem from one executive to another. It is building operational frameworks like AISLE’s VulnOps that match the velocity of discovery with the velocity of remediation.
The UK government published guidance explicitly rejecting blanket code closures based on concerns about AI-powered vulnerability discovery. Their position is clear. Remediation capacity matters more than code secrecy.
Making code private introduces delivery overhead while reducing both reuse and scrutiny. Open code allows faster identification through broader community review. The minimum standard requires clear ownership, secure-by-design principles, automated hygiene, and credible remediation capacity. This is a refreshingly pragmatic stance from a government body.
The temptation when confronted with AI-driven vulnerability discovery is to hide the code. The UK is arguing, correctly in my view, that the better response is to invest in the ability to fix issues faster. As I have been writing since Software Transparency, openness combined with operational maturity beats secrecy combined with patching debt.
I covered Chainguard’s one-day KEV SLA commitment in issue #96, and this partnership with Endor Labs extends their approach into the AI-generated code domain. The integration addresses a specific problem. AI coding agents generate code faster than humans can review it.
Chainguard ensures container infrastructure starts clean while Endor Labs provides function-level vulnerability analysis. AURI, Endor Labs’ platform, integrates into Cursor, VS Code, GitHub Copilot, and Claude Code. Chainguard’s $140 million Series C for “securing the next frontier of AI workloads” signals that the investor community sees supply chain security as the critical enabling layer for enterprise AI adoption.
The partnership model, combining infrastructure-level and code-level security, is the right architecture for an era where the code is generated autonomously and the containers are deployed at machine speed.
Here is a research direction that deserves more attention. SecureForge, highlighted by CISA Chief AI Officer Lisa Einstein, focuses on finding and preventing security vulnerabilities in LLM-generated code through prompt optimization techniques.
The research, published on arXiv with contributions from Stanford, demonstrates that the prompts used to generate code significantly affect the security properties of the output. This connects directly to the vibe coding crisis I covered in issue #97 where 380,000 publicly accessible vibe-coded apps had 5,000 actively leaking data. If the prompt shapes the security of the code, then prompt engineering for security becomes a first-class concern.
The fact that CISA’s AI leadership is signaling this research suggests it will inform future government guidance on AI-generated code security.
For those following my coverage of Terra Security’s OpenClaw vulnerability research in issue #97, the company expanded its agentic offensive security platform to include network infrastructure. The platform now covers web applications, AI systems, and network infrastructure through swarms of hundreds of AI agents paired with human-in-the-loop governance.
Findings are ranked by real exploitability and business impact rather than raw severity scores. The unification matters because offensive security has historically been fragmented, with separate vendors and separate outputs for each domain. When attack paths cross domains, as they almost always do in real-world breaches, siloed testing misses the connections. Continuous, unified offensive validation is the direction the market is heading.
Final Thoughts
This week crystallized something I have been circling around for several issues. The frontier AI capability question has been largely answered. AISI measured a 4.7-month doubling time. Palo Alto Networks found 7x more vulnerabilities in a single month. Cloudflare confirmed that Mythos is a qualitative jump, not an incremental refinement. VulnCheck documented CVE surges of up to 563% in a single vendor’s disclosure volume. ExploitBench gave us a rigorous measurement ladder. The capability is real, it is accelerating, and it is available to both defenders and attackers.
The open questions are now operational. Who remediates the vulnerabilities being found at 7x the previous rate? Who governs the agents deployed by 80% of the Fortune 500 with strategies at only 10%? Who secures the supply chain when threat actors open-source their attack frameworks on GitHub? Who enforces policy in headless architectures where agents interact with systems of record without touching a human interface?
The CISA GitHub leak is a painful reminder that the basics still matter more than the frontier. No AI model can compensate for leaving AWS GovCloud keys in a public repository for six months. The organizations that will thrive in this environment are the ones investing simultaneously in operational fundamentals and next-generation capabilities. The ones that treat AI as a replacement for operational discipline rather than an accelerant for it will learn the lesson the hard way.
Cloudflare tested Mythos against 50 internal code repositories and concluded the jump from prior frontier models is “not just a refinement of what came before."
I have long suspected that Anthropic explicitly designed Mythos to have that capability. While other LLMs of the current generation are nearly as good, Mythos in my opinion was designed to be a cybersecurity model - precisely to enable Anthropic to penetrate the US government market after the whole Pentagon fiasco.
I can't PROVE that, of course, without access to Anthropic internal documents.
As for prompt injection, I thought that was already conceded to be an unsolvable problem.
It gets worse if you follow AI cybersecurity expert Disesdi Shoshana Cox here on Substack, who says basically most of "AI security" is impossible and all of "AI red teaming" is fake.







Cloudflare tested Mythos against 50 internal code repositories and concluded the jump from prior frontier models is “not just a refinement of what came before."
I have long suspected that Anthropic explicitly designed Mythos to have that capability. While other LLMs of the current generation are nearly as good, Mythos in my opinion was designed to be a cybersecurity model - precisely to enable Anthropic to penetrate the US government market after the whole Pentagon fiasco.
I can't PROVE that, of course, without access to Anthropic internal documents.
As for prompt injection, I thought that was already conceded to be an unsolvable problem.
It gets worse if you follow AI cybersecurity expert Disesdi Shoshana Cox here on Substack, who says basically most of "AI security" is impossible and all of "AI red teaming" is fake.