
Resilient Cyber Newsletter #78
Inside the Trillion Dollar AI Buildout, Shaky Foundations of Vibe Coding, MCP from the Trenches, Agentic Browser Threat Modeling, 2025 State of LLMs & the Growth of CVEs

Welcome!
Welcome to issue #78 of the Resilient Cyber Newsletter. This is the first official newsletter release of 2026. I hope everyone had a great break for Christmas and New Years with friends and family and is as recharged as I am to hit 2026!
I’ve got a lot of great resources and discussions to share this week, including a comprehensive breakdown of the trillion dollar AI buildout, growing concerns about the sustainability of vibe coding, a deep dive into the state of MCP in the enterprise and a look at threat modeling the rise of Agentic browsers.
All this and more this week, so here’s to an amazing 2026, where AI will inevitably continue to shape not just cybersecurity but the entire software ecosystem.

Interested in sponsoring an issue of Resilient Cyber?
This includes reaching over 40,000 subscribers, ranging from Developers, Engineers, Architects, CISO’s/Security Leaders and Business Executives
Reach out below!
Cyber Leadership & Market Dynamics
AI-Orchestrated Cyber Espionage and the Future of Cyber Defense
Anthropic’s report of AI-orchestrated cyber espionage made headlines recently, and that includes catching the attention of those in the U.S. Government, at agencies such as CISA. In this discussion with Nick Andersen the Executive Assistant Director for the Cyber division within CISA, Nick discusses the role of AI and its impact on both cyber offense and defense and how CISA and the Federal government is thinking about the future of cyber defense.
Jevons Paradox for Knowledge Work

We've heard a lot this year about the role of AI and its impact on knowledge work, the labor market and employment. This is an anteresting piece from Aaron Levie, CEO of Box, where he states when discussing AI and Agents many overemphasize the “R” of ROI and under-examine the “I”.
Meaning, the cost of doing many activities is and will plummet, making access and capabilities available to many organizations which were historically reserved for the few, due to cost constraints. It’s interesting to think about the implications for cybersecurity.
Especially in a world where the majority of organizations live below the cybersecurity poverty line, as coined by Wendy Nather and as discussed in a piece I did with Ross Haleliuk. Most organizations simply can’t afford the workforce for effective SecOps, AppSec, GRC etc. But, in a world where agents are anticipated to perform many traditional laborious activities that required human capital/labor - how does that dynamic change?
All of this is said with the caveat that this same cost of human capital applies to attackers, but with even fewer constraints or organizational inertia to overcome in terms of adoption and implementations of Agentic AI.
Satya Nadella describes how lessons from Microsoft’s history apply to today’s boom
As I mentioned, I’ve been using time during the holiday break to catch up on some great conversations I had saved and queued up. Among them was this wide ranging interview with Microsoft’s CEO Satya Nadella. Satya goes through a lot of great topics, from Microsoft’s history to the current AI boom and everything in between.
What I was fascinated by was Satya’s range, as he navigated from complex technical topics to business and financially focused aspects of the conversation, but I suppose that’s why he leads one of the most dominant tech giants in the world!
AI
Inside the Trillion Dollar AI Buildout
I used Christmas/New Years break to catch up on great discussions I had saved. Among them was Dylan Patel’s interview about all things AI. While the title does focus on the massive capital intensive AI buildout, Dylan touches on way more than just infrastructure buildouts, covering topics ranging from coding, talent wars, competition among the model providers and way more. Dylan is easily one of the most knowledgeable and informative folks to follow on all things AI.
Prompt Injection - Vulnerability or Not?

ne topic that has led to a lot of debate in recent months is whether or not Prompt Injection is a vulnerability in LLMs or not. Groups such as OpenAI have openly said it is likely never to be solved and we continue to see countless examples of security researchers and product vendors trying to dunk on AI products by doing direct and indirect prompt injection attacks.
But, as Joseph Thacker points out in his excellent blog below, rarely is prompt injection the actual vulnerability, but instead is most often the delivery mechanism, rather than the root cause itself, the impact of the injection.
Joseph lays out a few examples such as data exfiltration via dynamic image rendering, data exfiltration via AI email responses and data exfiltration via web fetches. In each scenario, he points out how the impacts could have been remediated or mitigated by more rigorous controls on what the AI and LLMs can or can't do, and involving human review or approvals.
This of course speaks to the implicit tradeoffs between functionality and security, a tale as old as time, and unfortunately one where security almost always loses in exchange for broad functionality, speed and ease of use.
Vibe Coding Leads to Shaky Foundations
That’s one of the takeaways from Cursor’s CEO’s comments recently to Fortune. In 2025 we saw the rapid rise of “Vibe Coding” as the development community, much to the dismay of cybersecurity, leaned into AI coding tools and just implicitly trusting outputs. That said, the term also became a catch-all, and mistakenly used to refer to any AI-driven development, even when being wielded by highly proficient developers with deep domain expertise.
It will be interesting to watch how AI coding evolves in 2026 and beyond and what the digital attack surface looks like given implicit trust in AI generated code and things being quickly generated and exposed to the Internet, and the attackers that come along with that.
The genie is out of the bottle and we’re never going back to the “old days”.
Planning a Successful AI Rollout in Cybersecurity
There’s been a lot of stories of problematic AI rollouts across enterprise environments. Cybersecurity isn’t immune from botched rollouts either, which is why I found this piece from Alain Mayer and David Seidman to be a good one.
They lay out key concepts and a structured approach to rolling out AI in Cyber, including:
Setting baselines and measuring before you automate, including establishing core metrics and turning those metrics into benchmarks
Identifying the right starting points for automating with AI, including the importance of early win automation candidates
Reserving higher context tasks for later phases and using an AI readiness checklist
This is a practical and well grounded piece that can be used to help establish a sound approach to rolling AI out, not just in Cyber, but beyond as well. The key theme in their piece is you have to know what you’re hoping to accomplish and how well you’re doing it currently before deploying AI or being able to understand its ROI. Unfortunately, many are doing the opposite and rushing into adoption with no clear picture of where they are now, let alone where they hope to go.
The Normalization of Deviance in AI

The incentives for speed and winning outweigh the incentives for foundational security.
A tale as old as time when it comes to cybersecurity, and it is one we're watching unfold both in the sense of frontier model and platform providers, as well as in the macro sense across enterprise environments where the competitive pressures to outpace and out innovate competitors drives the normalization of insecure behaviors and practices. This is a great piece discussing how temporary shortcuts become the new baseline, as deviance from secure practices and methodologies get normalized.
It's exacerbated by the absence of an incident, or even in the face of them, as organizations race to beat peers and innovative startups and incumbents alike rush to capture market and mindshare. The article discusses insecure LLM outputs, implicit trust, and bypassing best practices in the name of speed.
It all works...until it doesn't.
The Biggest Impediment to AI Outcomes is Organizational Readiness
That was the key point made recently by Mike Krieger, CPO of Anthropic. He pointed out how AI is quite capable now, in terms of knowledge, activities, tool use and so on, but organizations have a long way to go in terms of maturity to move towards widespread AI implementation and business outcomes.
To successfully use Claude and others leading AI tools for business outcomes will require clear requirements and goals, along with providing adequate information to the LLMs and Agents.
“You have to organize the data in a way the AI can understand before it can be helpful”
It also requires giving AI sufficient access, an area many are rightfully concerned with as we continue to see incidents impacting organizations, as well as the leading LLMs and Agentic platforms. See below for key items Mike emphasizes:

This means organizations need to have clarity on the tasks they want AI to perform, give AI appropriate permissions (and be comfortable with doing so) and have stable processes that can be programmatically executed repeatedly at-scale. As many who’ve worked in complex organizations, while this may sound simple, it is anything but.
Given how the MIT report on the success of AI efforts and outcomes rocked the industry in 2025, it will be key to see if we can move beyond the headlines to actually drive measurable ROI with AI efforts.
MCP: A View from the Trenches
The Model Context Protocol (MCP) from Anthropic took the industry by storm this year. Suddenly it was something everyone was talking about and every vendor seemed to create an MCP server and integrate MCP into their offerings. But, what does it look like under the hood in terms of adoption and risks?
I found this report from Clutch Security to be full of great insights on that front, looking at organizations with at least 10,000 employees.
MCP saw an insane 2,200% growth in 13 months with 15% of enterprise users running at least one local MCP and 3,000 total server installations.
86% of developers choose to run MCP servers locally, despite alternatives being available and 95% of these uses are running locally on developer endpoints, where traditional EDR tools have little visibility when it comes to MCP.
They found 115 distinct enterprise services exposed via MCP, 3% of which contain hardcoded credentials
Organizations are largely flying blind when it comes to knowing what MCP servers exit in their environments, what credentials they access, what connections they make and in short, what risks they present.
The widespread implicitly trusted usage of MCP across the ecosystem exploded, with little concern for the risks associated with it. 2026 is going to be interesting when we watch this continue to grow and novel and impactful vulnerabilities, risks and threats get identified.

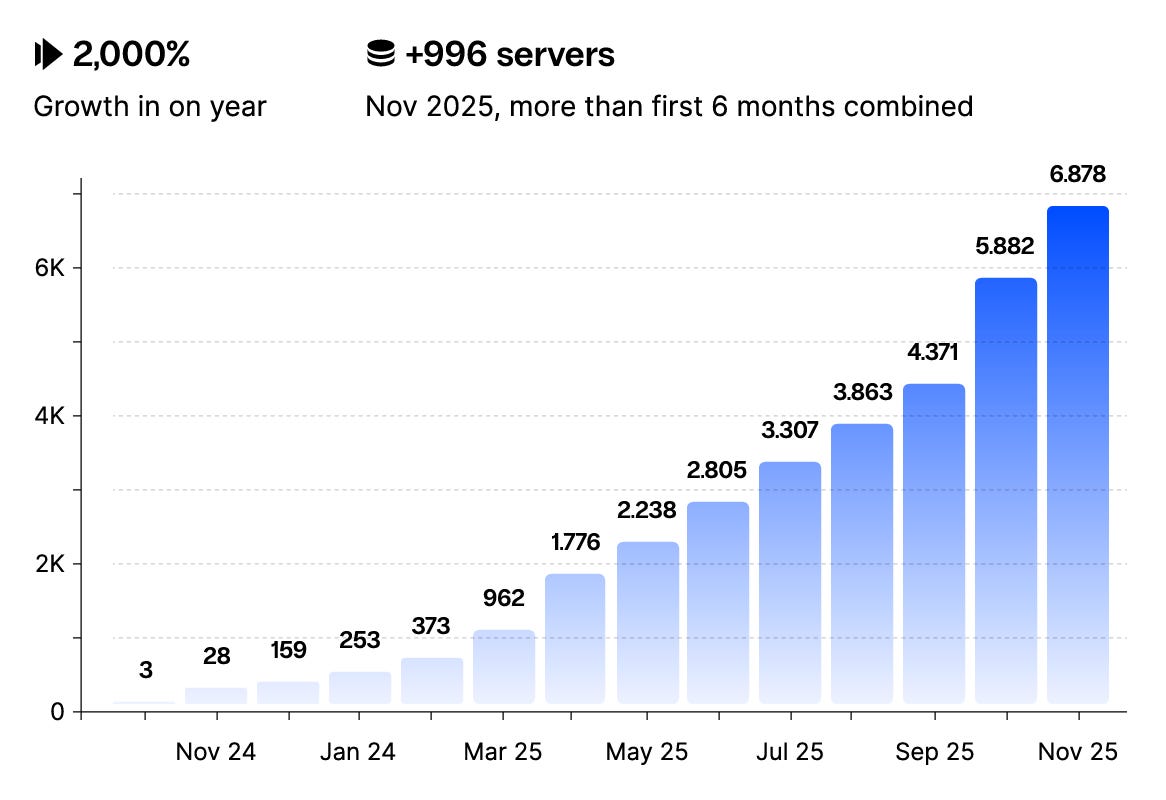
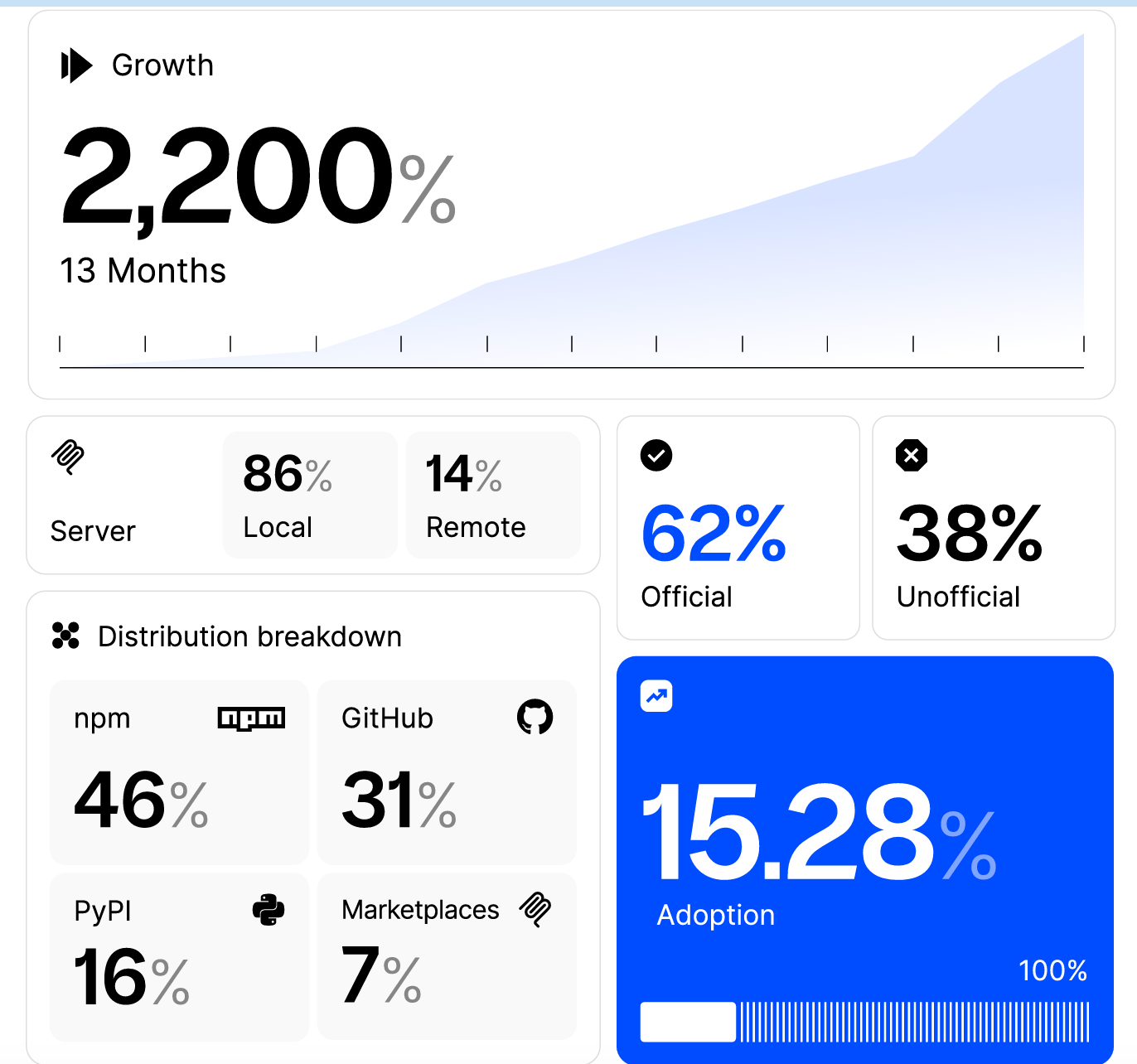
This report is full of great insights and is well worth a read if you’re looking to understand the growth of MCP as well as the associated risks.
Agentic Browser Threat Modeling
Another key trend among the broader Agentic AI wave in 2025 was that of Agentic Browsers. ChatGPT's Atlas, Perplexity's Comet, and the latest example being Claude in Chrome. The opportunity sounds promising, especially given how much time users spend in the browser and the ability to streamline, automate and amplify activities across the web and countless web-based applications.
So what's the catch? Well, as it turns out, quite a lot.

This piece from the team at Zenity highlights key concerns from indirect prompt injection, destructive actions, sensitive data disclosure, lateral movement and user impersonation. Most of a users time is often spent in the browser, including managing cloud infrastructure, monitoring, accessing systems with sensitive organizational data and in the age of AI, accessing sites and data which may lead to incidents (e.g. indirect prompt injection) in various forms, all while inheriting the permissions and persona of the users in the browser.
This piece lays out those key risks across Agentic Browsers, as well as unique aspects of Claude in terms of how it views pages, utilizes tooling, the data it exposes to the model and more.
Hardening OpenAl’s Atlas: The Relentless Challenge of Securing an Untrusted Browser Agent

Speaking of hardening and securely using Agentic Browsers, Zenity who published the prior excellent piece on Claude’s Chrome integration followed up it with another piece discussing OpenAI’s Atlas and how much of the hardening and secure usage of their Agentic Browser is being left to the user, including:
Avoid broad scope prompting such as “Review my emails and do whatever is needed”. They might lead to unexpected consequences.
Highlighting the need to write safe prompts (Yes it's the user's responsibility to look after their own safety, the browser shouldn't be trusted)
Instructing the user to carefully review each action before approval.
You don’t need to think to hard to realize that most users simply won’t take these precautions and lack the fundamental security awareness or experience to even think of these things during their daily usage. If and when Agentic Browsing becomes widespread, so will the risks of not doing the exact activities laid out above by OpenAI.
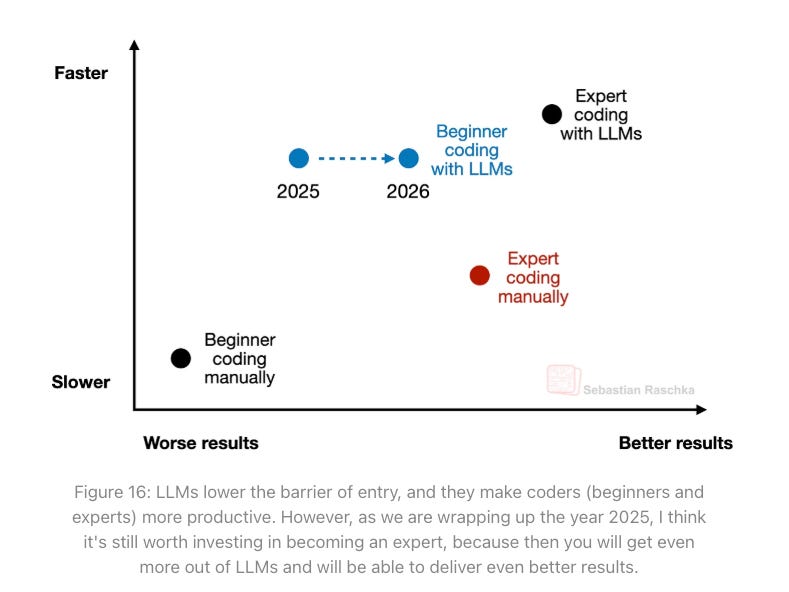
The State of LLMs 2025: Progress, Problems and Predictions
To say AI has and continues to advance quickly would be an understatement. That said it can be hard to keep up with the pace, even for leaders such as Andrej Karpathy, who recently shared his struggles with keeping up with the pace of changes AI is having on software development.
This piece from Sebastian Raschka, PhD is an incredibly comprehensive breakdown on the State of LLMs in 2025, including the progress made, problems that remain and predictions moving forward.
AppSec
Can LLMs Quantify Vulnerabilities?
We continue to see the industry look to apply AI, LLMs and Agents to countless use cases across many cybersecurity categories. One such a problematic area is that of assigning scores to vulnerabilities, specifically CVEs.
This is an excellent paper out of the University of North Carolina Wilmington looking into just that. The authors lay out the problem space, including exponential year-over-year CVE growth, and systemic problems with the National Institute of Standards and Technology (NIST) NVD, such as funding challenges, stagnant team sizes and mounting CVE backlogs that aren't enriched.
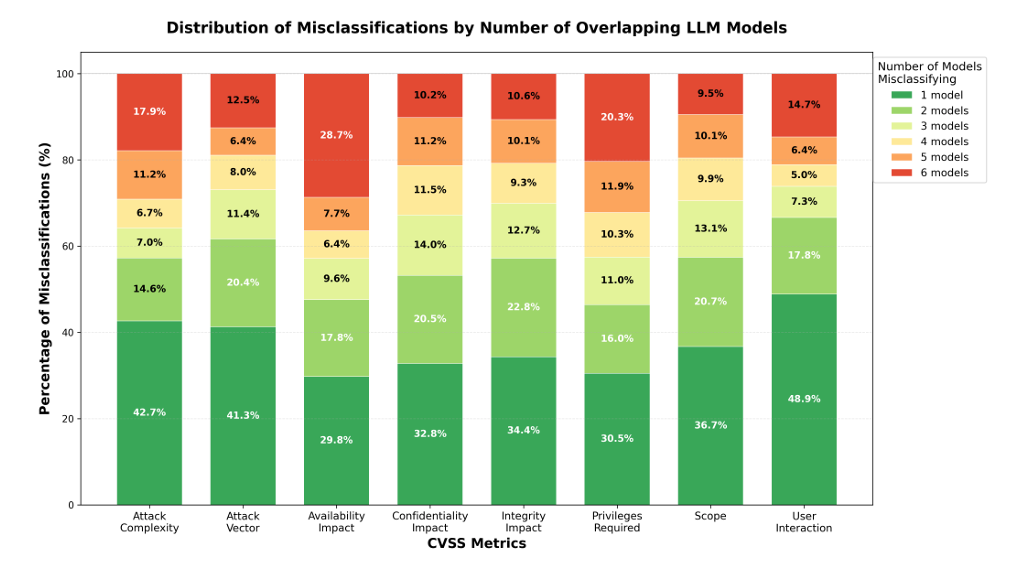
They study using popular LLMs such as ChatGPT, LLama, Grok, DeekSeek and Gemini to see how they do with assigning CVSS scores to CVEs, using a mix of open source and proprietary models. They primarily use the CVE description field, to avoid bias with CVE IDs with existing scoring etc. but also demonstrated using meta-identifiers as well.
The LLMs did great in some areas, such as Availability Impact, but not so much in others and the performance varies across the models. The research also demonstrated the age old garbage in, garbage out challenge with data quality, showing how critical quality CVE description fields are to aid LLMs in the automated scoring of CVEs.
The data quality associated with CVE records has been a longstanding challenge folks such as Josh Bressers, Patrick Garrity 👾🛹💙 and others have discussed exhaustively.
In short, LLMs show promise to assist us with longstanding challenges of vulnerability scoring, but it requires a sound foundation of quality CVE records, which is problematic at best currently.
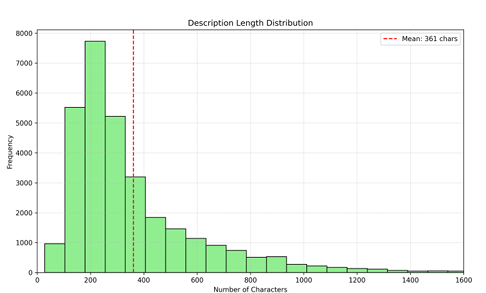
They have helpful diagrams in the study showing the role that description length and other factors play too.
Trust Wallet Compromised, Stealing $7M on Christmas Eve

The team out of Koi continues to rapidly provide insights on software supply chain threats and malicious packages and extensions. The latest example comes via a crypto wallet named Trust Wallet, owned by Binance with over 1 million Chrome users.
There was a malicious update pushed on Christmas Even, similar to the malicious Cyberhaven Chrome extension in 2024 on Christmas Eve. In this case, it resulted in roughly $7 million being drained from user wallets in under 48 hours.
While it hasn’t been confirmed the threat actor is the Grinch, it sure as hell feels like it.
Antiquity is a Superpower: Why legacy vendors are still winning in VulnMgt (for now)
We continue to see the Vulnerability Management space evolve into a new category now being called Continuous Threat and Exposure Management (CTEM). It’s once I’ve written about before, in pieces such as “X”.
In this piece, Mehul argues that antiquity is a super power and despite many looking to disrupt VulnMgt over the years, the legacy giants such as Tenable, Qualys and Rapid7 still reign supreme. To prove his point he uses the announcement of Kenna being End of Life.

Mehul makes the argument that while innovative startups can try and tackle aspects of VulnMgt such as prioritization and remediation, but MVPs don’t cut it in this category and you must dominant in the aspects of vulnerability signatures and sensors/scanners to detect vulnerabilities.
He states that Cisco looked at Kenna and saw a profitable acquisition target without realizing it lacked native capabilities to cover the aspects I mentioned above and were forced to try and build it, pay the incumbents for their signatures and sensors, or just shut things down.
The reason he argues antiquity is a superpower is that these entrenched incumbent firms have decades of vulnerability signatures and sensor data and it is hard to replicate. Unlike the new startups, these entrenched incumbents cover all the corner cases, EoL software, antiquated products and more for their large longstanding enterprise customers. This is a feat not easily replaceable by the new cloud-native types who don’t have decades of product development backing their product for every obscure product and application you can imagine in terms of coverage. Mehul calls this the “long tail of signatures” and argues:
“Your VM tool must possess the “long tail” of signatures required to audit these legacy systems, modern systems and everything in between. Otherwise it risks providing a false sense of security.”
The same goes for scanners, from networks, to agent-based sensors, legacy hardware, API-based scanning, cloud environments and more. Customers want full not partial coverage when it comes to understanding their vulnerability footprint.
This means new startups may have flashy and promising capabilities, but they lack comprehensive coverage and depth that most enterprises simply must have when it comes to VulnMgt.
What’s Behind the Growth of CVE’s?
Every year we tend to look at the raw number of CVE growth and stand in amazement, knowing we’re already struggling to keep up with vulnerability remediation and it is only getting worse. But, what’s actually behind the CVE growth?
My friend Patrick Garrity of VulnCheck provides a great breakdown in a recent post of his. While it is true that the raw number of CVE’s is going up YoY, the truth is much of the growth is being driven by a small handful of CNA’s as he shows below:
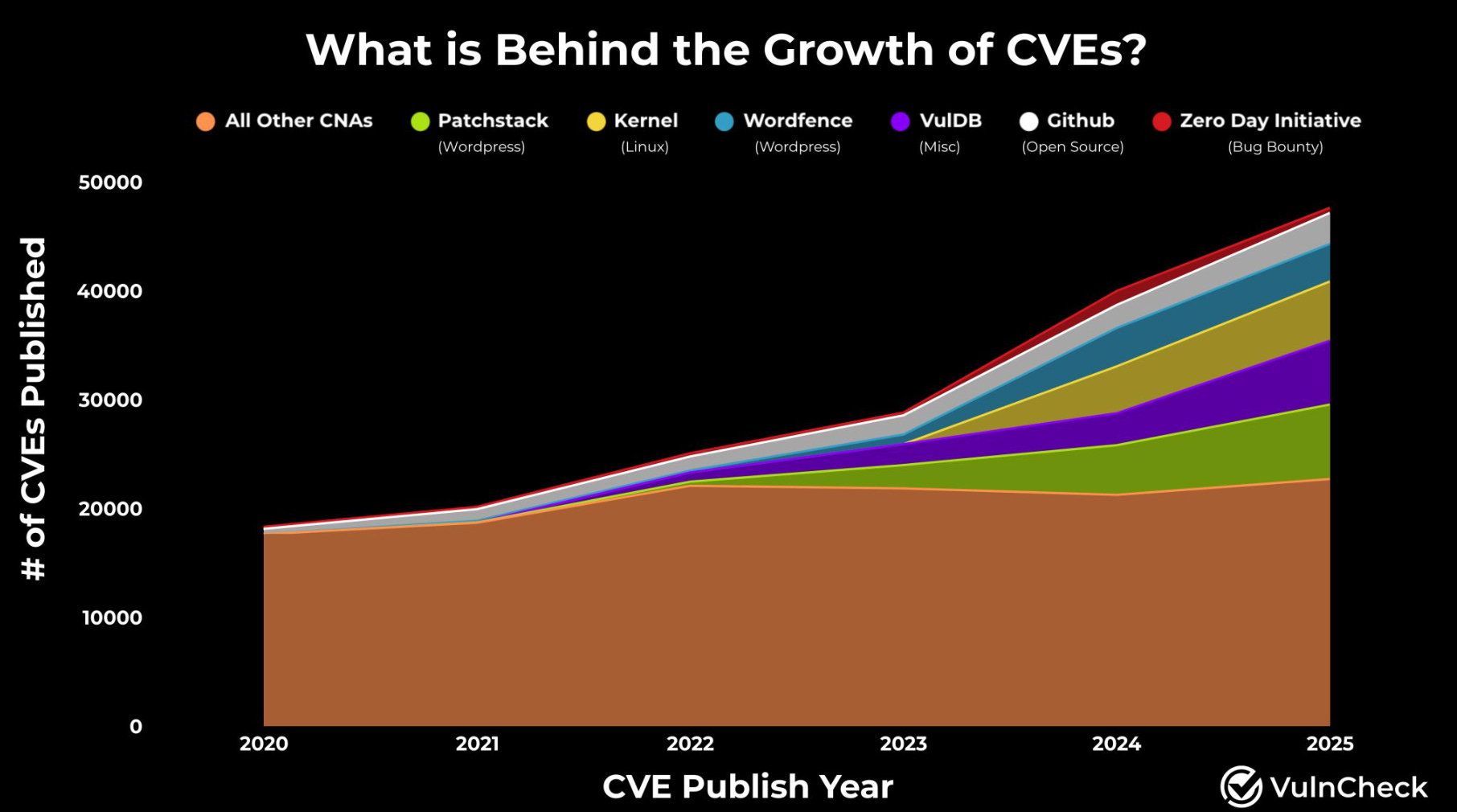
This isn’t to say that CVE growth isn’t a challenge, and in fact, I anticipate the rise of AI-driven development and vibe coding may lead to even more exponential growth, albeit it will be difficult to measure at the NVD level, given they don’t often know how the code was developed. All that said, it is helpful to see that a handful of CNAs often have an outsized impact on CVE growth annually.