Fable 5 Makes Its Comeback, Linux Foundation Launches Akrites, Winning AI Cyber Safety via Adoption, not Restriction, Mapping Cyber Eval Benchmarks & GitHub Advisory Database Hits Record Volume
Welcome to issue #104 of the Resilient Cyber Newsletter!
Three weeks ago, the Commerce Department ordered Anthropic to shut down Fable 5 for all users worldwide. This week, Fable 5 is back. Anthropic announced the redeployment starting July 1 with new safety classifiers, CAISI-validated safeguards, and a proposed industry framework for scoring jailbreak severity. The twist that nobody saw coming? Amazon’s own testing confirmed the same behaviors they reported in Fable 5 exist in every frontier model they tested, including GPT-5.4, GPT-5.5, and their own.
The bigger story this week is what happened while Fable 5 was offline. China’s 360 Security Technology unveiled tools they claim reach parity. The WSJ reported Chinese AI matching Anthropic on specific cybersecurity benchmarks, and enterprise customers started migrating to cheaper open-weight alternatives, with Chinese models now accounting for over 60% of tokens on the largest neutral router. Clayton Christensen’s disruptive innovation framework, which Howard Yurecently revisited, is playing out in real time. The low-end disruptors are not waiting for permission.
Meanwhile, two separate Claude Code vulnerabilities were published in the same week, the Linux Foundation launched Akrites as the largest coordinated open-source defense effort in history, and Anthropic’s Mythos reportedly found vulnerabilities in classified U.S. government systems within hours.
So sit back, and let’s dig into what feels sometimes like a soap opera coupled with technology.
The gap between what your compliance documentation says your authorization program does and what actually runs in production widens every time you add a service, a workload or an agent.
It usually surfaces during an audit or an incident, which is the worst time to find it.
The Authorization Maturity Model is a new ebook by Alex Olivier, Cerbos CPO and co-chair of OpenID AuthZEN. It gives security leaders a 4-stage benchmark and a self-assessment to see where their program actually stands, an exposure rating across NIS2, DORA, SEC, the EU AI Act and more, and a 90-day plan to close the gap.
It also covers what good looks like at each stage, and what changes once AI agents are in production.
Thanks for reading the Resilient Cyber Newsletter! Subscribe for FREE and join 20,000+ readers to receive weekly updates with the latest news across AppSec, Leadership, AI, Supply Chain, and more for Cybersecurity.
The Fable 5 saga that I covered in detail in issue #102 has reached its resolution, at least for now. Anthropic announced that Claude Fable 5 returns July 1 across Claude Platform, Claude.ai, Claude Code, and Claude Cowork after the Commerce Department lifted export controls on June 30.
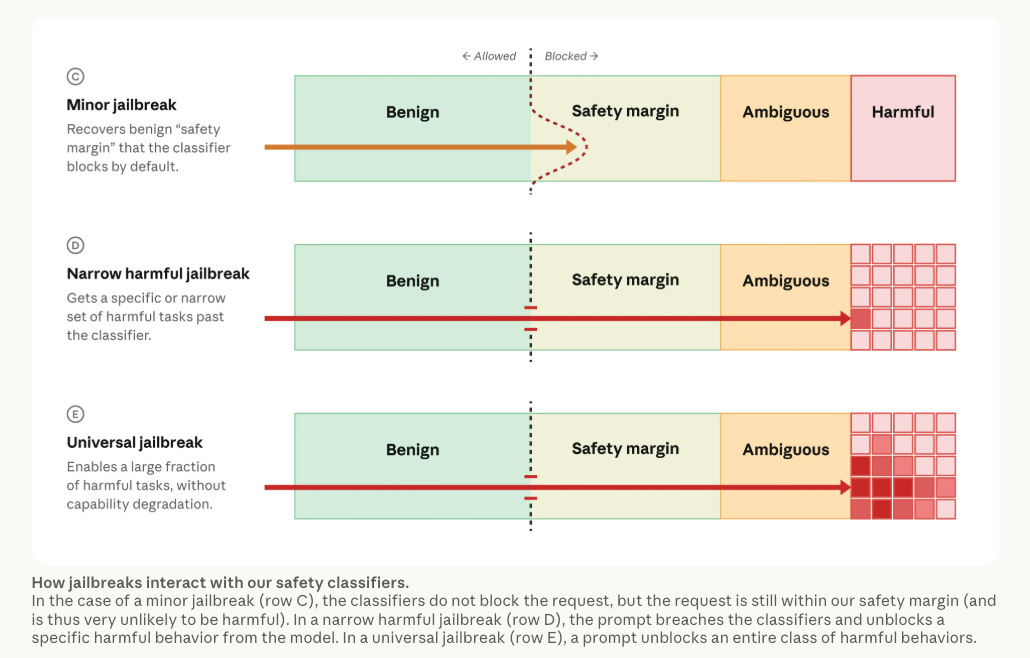
The post provides extensive detail on what happened behind the scenes. Amazon’s security researchers identified a safeguard bypass, and when Anthropic tested the same technique against every frontier model available, including Haiku 4.5, every version of Opus, GPT-5.4, GPT-5.5, and Kimi K2.7, the same behaviors were replicable across the board. A new safety classifier now blocks the reported technique in over 99% of cases, and CAISI (within NIST) independently tested and confirmed the safeguards are “extraordinarily strong.”
The most significant outcome is not the model returning but the industry infrastructure emerging from the crisis. Anthropic is partnering with Amazon, Microsoft, Google, and Glasswing partners to develop a consensus jailbreak severity framework with four scoring criteria (capability gain, breadth, ease of weaponization, and discoverability), essentially building the CVSS equivalent for AI jailbreaks.
A new HackerOne program for cyber jailbreak submissions has been launched, and Anthropic has committed to pre-release government access and rapid information sharing.
Whether you think the original export control was warranted or not, the institutional response, a severity framework, coordinated disclosure, and independent validation, is exactly the kind of governance infrastructure this industry has been missing but there is a lot of warranted skepticism in terms of what this turns into, and how it is handled.
There are also a lot of unintended consequences of how this plays out, which I tried to capture in the video below:
This is one of the most important announcements I have covered this year related to open source security. Akrites, a new Linux Foundation project, brings together 20+ founding members including AWS, Anthropic, Cisco, Google, IBM, JPMorgan Chase, Microsoft, NVIDIA, OpenAI, Red Hat, and Zscaler to find, fix, and responsibly disclose vulnerabilities in critical open source software.
The coalition will serve as “maintainer of last resort” for unmaintained critical packages, committing engineering talent, funding, and a shared Security Incident Response Team to work upstream with maintainers.
The numbers driving the urgency are stark. OpenInfra Foundation reported 20 security advisories in one quarter of 2026 versus only 2 in all of 2025, a 10x increase. Endor Labs found that of thousands of validated open-source vulnerabilities surfaced recently, fewer than 5% have been patched.
AI has made vulnerability discovery trivially fast, but remediation remains a human-speed bottleneck, and Akrites is the most serious attempt to date to close that gap at scale.
I spoke about this at length in countless blogs and in my book Software Transparency, where I made the case that open source is critical infrastructure but suffers from the tragedy of a digital commons.
Senator Mark Warner disclosed that NSA chief Joshua Rudd told him Mythos “broke into almost all of our classified systems, not in weeks, but in hours” during a testing exercise through Project Glasswing, Anthropic’s collaboration with U.S. intelligence agencies.
The distinction between identifying and exploiting vulnerabilities matters here, but the speed at which Mythos mapped attack surfaces across the government’s most sensitive systems speaks to the capability gap I have been tracking all year.
This disclosure came amid ongoing tensions between Anthropic and the Trump administration over military AI use, and it adds a complicated layer to the Fable 5 re-release debate. The same model that defenders desperately want access to is the same one that found its way through classified system defenses in hours.
All of this said, there has been several who have pointed out how this story is very hyperbolic and there is a lot of nuance to the claimed headline, and it is more clickbait then reality.
The spending correction I have been expecting is arriving. The top 1% of companies spend $89,000 per engineer per year on AI while the median spends just $137, a 680x gap that is starting to close from both directions.
Uber burned through its entire 2026 AI token budget in four months and had to implement monthly tiers. Lindy switched entirely to cheaper open-weight alternatives, expecting millions in savings.
On OpenRouter, Chinese models went from roughly 1% of usage in 2024 to over 60% in May 2026. Tomasz Tunguz models three scenarios where by 2029, per-engineer AI spend ranges from $106,000 (bear) to $596,000 (bull), with the bull case matching an entire median-SaaS employee’s revenue contribution. Security budgets flow downstream of engineering budgets, and this spending recalibration will shape procurement decisions for the next two years.
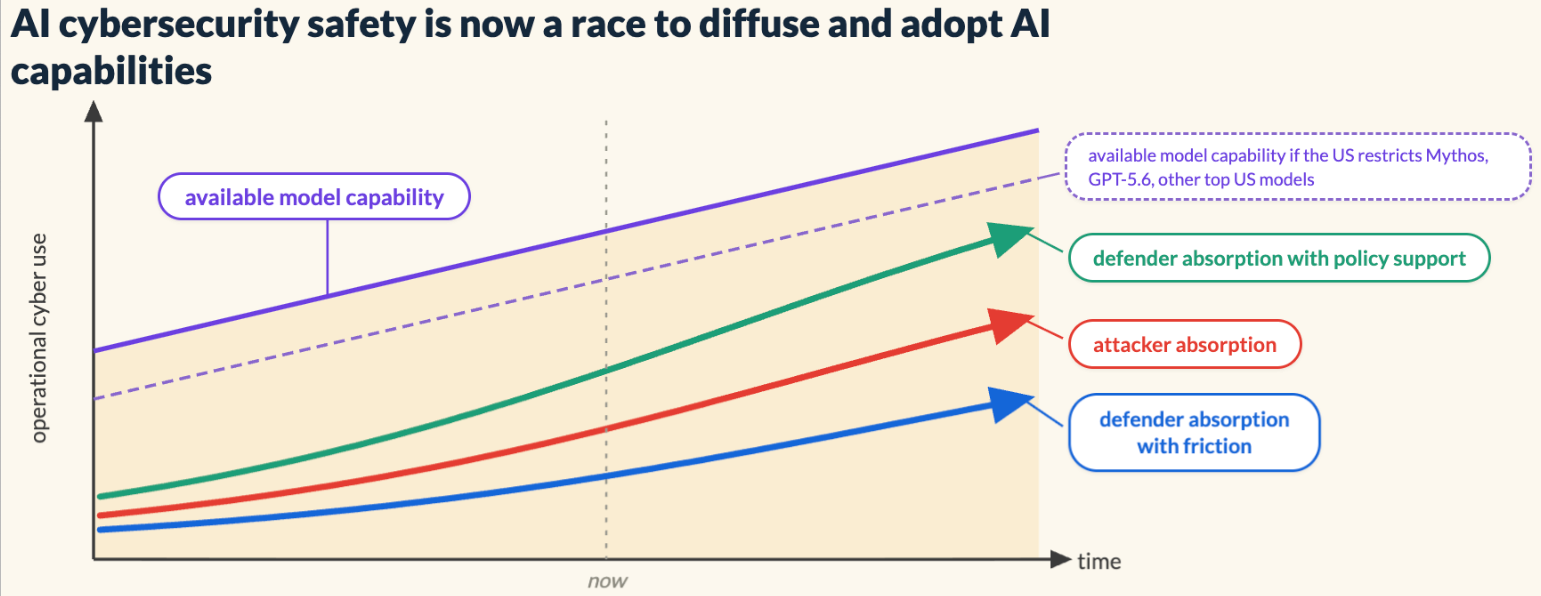
This is the clearest articulation I have seen of the case against restricting frontier AI models from defenders. Joshua Saxe argues that the dominant framework of measuring model capabilities at launch and restricting access at danger thresholds is now invalidated because capability diffusion has been lost to the geopolitical AI race with China.
Attackers already have private access to near-frontier models like GLM-5.2. There are 100x more defenders than attackers, and defenders control 100x more GPUs. The winning strategy is not to restrict American models but to ensure defenders adopt AI faster and better than attackers do.
Whether you fully agree or not, the core logic is hard to argue with. Denying your own side a weapon that the other side already has is not a strategy. I covered this in depth below, citing Josh’s writing on the topic as well, and I hope to have Josh on my Resilient Cyber show soon to dive into all of it.
Venables offers 21 examples of non-security control functions (finance, safety, legal, HR) pushing back against risky business decisions and introduces sociologist Stewart Clegg’s 1989 “Circuits of Power” framework as a lens for understanding why security controls succeed or fail.
The three circuits are episodic (day-to-day interpersonal), dispositional (rules and culture), and facilitative (infrastructure and automated enforcement). His core argument is that security teams burn out because they fight episodic battles using only dispositional arguments, when the real fix is building facilitative circuits that make the secure path the easiest path.
If you are a CISO tired of holding the line through sheer force of will, this framework gives you a vocabulary for the structural changes that actually stick.
JPMorgan’s Innovation Economy group produced a comprehensive market report with several data points worth bookmarking.
Non-human identities outnumber human identities 144-to-1 in enterprises, growing 44% year-over-year. AI agents operating inside enterprise environments grew 466.7% year-over-year.
U.S. cybersecurity venture funding hit $11.5 billion in 2025 (highest since 2022), with 72% of deals involving AI-enabled companies, up from 36% in 2019. AI-related vulnerabilities surged from 439 in 2024 to 2,185 in 2025, and 36% of all published AI vulnerabilities involve APIs.
The competitive frontier, JPMorgan notes, is shifting from detection to remediation, and products that orchestrate fixes while preserving human oversight are gaining the most traction.
Nebulock’s $25M Series A, led by FirstMark, funds an autonomous threat hunting platform that has already run 300 million+ agentic investigations and produced 4,000+ high-confidence findings.
The company argues that reactive, alert-based security operations are fundamentally broken, citing data that enterprise SIEMs miss roughly 79% of MITRE ATT&CK techniques and 13% of SIEM rules are broken and will never fire. New capabilities include insider risk management that unifies human and AI agent identities.
The “hunt-first” positioning is a direct response to attacker strategies that increasingly rely on valid credentials and blending into normal activity rather than triggering traditional detection signatures. I’m impressed with the Founder of Nebulock and will be keeping an eye on the team.
Foundation Capital’s Ashu Garg argues that the AI market’s presumed winner-take-all dynamic is not materializing, and the implications for security are significant.
Four roughly equal players (OpenAI, Anthropic, Google, xAI) are competing, advances are quickly copied through distillation, and regulatory forces are fragmenting access geopolitically. DeepSeek scores within striking distance of Opus on SWE-bench at roughly 1/30th the price, and open-source alternatives are available at 1/100th. Infrastructure platforms like Databricks and Snowflake are going model-agnostic with single-toggle LLM swapping.
The real moat, Garg argues, is not the model but the product layer built on top. For security leaders, this reinforces what the Fable 5 saga demonstrated in practice. Never build a critical dependency on a single model provider.
Menlo Ventures partner Deedy Das described what he sees as an identity crisis “bordering on depression” among experienced software engineers.
The piece captures a growing cultural divide between “vibe coders” who accept AI output uncritically and veteran engineers who spend their days cleaning up what the article calls “workslop,” shoddy AI outputs passed between colleagues creating an illusion of productivity. Companies like Meta are now factoring AI usage into performance reviews. One unnamed firm reportedly spent $500 million on Claude in a single month.
The Faros AI data I covered in issue #102 (861% code churn increase, tripled production incidents) puts numbers behind the anecdotal misery described here. The security implications remain the same. More code, less review, more bugs.
CVE-2026-55607, scored 7.7 High, exploited git worktree path confusion and symlink manipulation to escape Claude Code’s most hardened macOS seatbelt sandbox.
The full attack chain is elegant in a terrifying way. A malicious repository’s CLAUDE.md used prompt injection to guide Claude through its own legitimate worktree tools, creating a worktree named “.git” that caused directory confusion, then pivoting via symlink from .claude/worktrees to the user’s home directory, and finally writing to ~/.zshenv, which executes before sandbox profiles are applied.
The researcher demonstrated it by opening Calculator on macOS from inside the sandbox. The vulnerability was patched in v2.1.163, and Anthropic awarded a bounty through HackerOne.
The broader lesson is that AI coding agents need threat models closer to browsers and package managers than chatbots. Every “normal” development operation the agent performs is a potential step in an attack chain.
The second Claude Code vulnerability published this week is arguably more concerning than the first because it has no fix on the horizon.
A 21-line malicious .claude/settings.json file committed to any git repository can silently weaponize Claude Code’s OpenTelemetry pipeline to exfiltrate user PII, session prompts, API responses, and environment secrets to attacker-controlled infrastructure.
The otelHeadersHelper feature is an unconditional code execution primitive that runs at session start and every 29 minutes. The attack can persist machine-wide by poisoning the global ~/.claude/settings.json. Bloom Security found that the top 5 skills marketplaces contain over 5,000 skills referencing OTEL, and hundreds of repositories already have OTEL configurations in their .claude/settings.json files.
Anthropic disagrees with the severity characterization, pointing to workspace trust as the security boundary. But the trust dialog does not surface OTEL settings as a risk category, and most users have pre-approved via parent directory inheritance.
Two developments this week underscore how fast the capability gap is narrowing. Independent benchmarks from Semgrep and Graphistry show GLM-5.2 scoring 39% F1 on IDOR detection versus Claude Code’s 32-37%, with the caveat that GLM-5.2 still trails on general-purpose benchmarks.
Meanwhile, 360 Security Technology unveiled “Tulongfeng” at ISC.AI 2026 in Beijing, claiming 3,432 software vulnerabilities found with 105 confirmed by Chinese authorities. Founder Zhou Hongyi acknowledged a 20-30% gap in Chinese base model capability versus U.S. rivals but framed the effort as a national security imperative, arguing China faces “one-way transparency” risk if only American entities can scan systems.
The practical implication is clear. Whatever capability advantage the Fable 5 export controls were meant to protect has eroded faster than anyone expected.
I mentioned AISLE briefly last week in the context of GLM-5.2, but the full story deserves its own treatment. This Prague-based startup has discovered 200+ CVEs using widely available and open-source models that can run air-gapped.
On OpenSSL, AISLE found 20 of 23 zero-day vulnerabilities across three consecutive security releases. On FreeBSD (Anthropic’s own showcase codebase), AISLE matched Mythos 3 CVEs to 3, finding additional bugs after Mythos’s showcase vulnerabilities were already patched. UC Berkeley’s Vulnerability Initiative ranks AISLE number one globally in 3 of 8 categories versus Anthropic’s 1. The geopolitical weight here is unmistakable.
After the U.S. directive suspended Mythos access for non-U.S. nationals, AISLE demonstrates that world-class defensive AI vulnerability discovery does not require dependence on a single American provider. Stanislav Fort has an excellent blog on the topic titled “Mythos at Home”. I’ve had him on my show in the past as well, where we dug into all of this:
OpenAI’s GPT-5.6 family arrives in three tiers. Sol (flagship), Terra (mid-tier), and Luna (fast and affordable), with pricing ranging from $5/$30 per million tokens (Sol) down to $1/$6 (Luna).
The notable departure from prior releases is the government-coordinated restricted rollout, initially limited to roughly 20 trusted partner organizations before broader availability. Sol is positioned as OpenAI’s most capable model for cybersecurity applications.
The tiered approach with explicit government coordination reflects the new post-Fable reality where frontier model releases are no longer treated as routine product launches but as events with national security implications.
Dr. Nicola Franco at AI4I subjected Opus 4.8 and Fable 5 to hundreds of thousands of automated jailbreak attempts using the HackAgent framework across 7,826 harmful intents.
The best attack (tree-of-attacks search) broke Opus 4.8 on 11.5% of intents and Fable 5 at 6.1%, producing over 2,300 confirmed harmful completions across every harm category. The most concerning finding is not the success rate but the economics. Successful attacks arrived within the first 1-2 refinement steps, meaning they are cheap and fast to discover automatically.
Static obfuscation techniques were nearly fully neutralized (under 0.2% despite roughly 50,000 attempts), but adaptive attacks remain effective. The worst categories for Opus were child safety (27.6% success), cybersecurity and phishing (16.6%), and criminal and economic harms (14.7%).
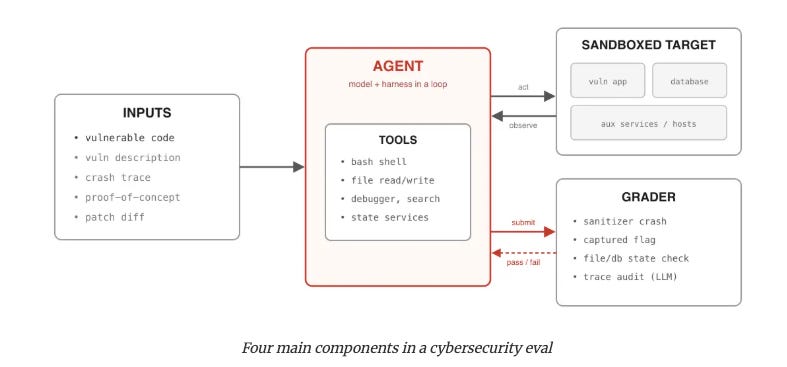
This is the most useful survey of AI cybersecurity evaluation methodologies published to date. Eugene Yan (Anthropic staff) reviews seven benchmarks and identifies a common four-component pattern across all of them, specifically sandboxed targets, difficulty-tuning inputs, tools, and graders.
The standout data points across the benchmarks tell a clear story. Claude Mythos exploited 157 of 898 instances on ExploitGym (GPT-5.5 got 120). With the Incalmo framework, agents succeeded on 37 of 40 networks including a 50-host Equifax replica, and 10 models generated working exploits for 207 of 405 smart contracts, draining a simulated $550 million.
The evaluation cost alone exceeded $40,000 in API credits and 1,000 H100 GPU hours, which tells you something about the resources required to do this work responsibly. I found this resource super insightful as someone who doesn’t have direct experience creating benchmarks but often sees them cited.
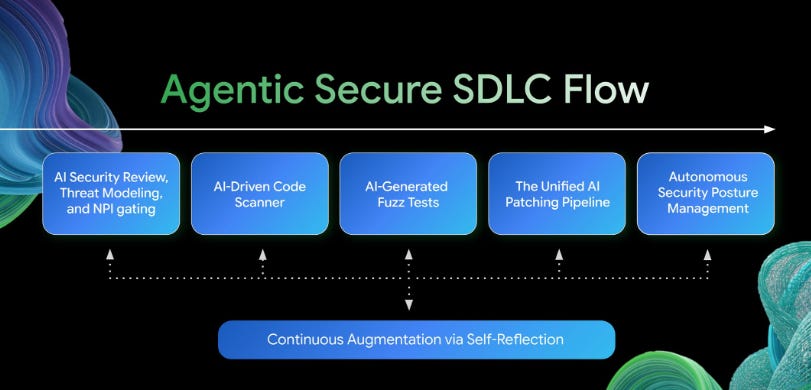
Google Cloud CISO Chris Betz detailed how the company has transitioned to an autonomous, AI-driven SDLC security model anchored by the Mantis framework (core skills now open-source on GitHub).
The problem Mantis solves is real. Naive decentralized AI code scanning yields true-positive rates under 7%. Mantis addresses this through multi-agent orchestration with specialized Strategist, Research, Deduplicator, Reviewer, and Critic agents, plus a reproduction sandbox that validates findings before surfacing them.
A self-reflection loop analyzes execution logs and human feedback post-workflow, creating a compounding improvement effect. The token overhead reduction is dramatic, with hierarchical security summary trees cutting costs by over 85%.
Federico Maggi ’s report from the inaugural Real World AI Security conference at Stanford captures where the practitioner community actually is versus where the vendor marketing suggests it should be.
The key finding is that most current security work focuses on securing AI agents rather than using AI for security, a defensible priority given that agents are moving into production faster than the industry is securing them. Guardrails are compared to client-side validation in web apps, necessary but insufficient, and the biggest infrastructure gap identified is confidential computing for agents.
The conference also surfaced a telling observation. AI-assisted vulnerability discovery is well advanced but AI-assisted patching remains largely unresolved, which is exactly the bottleneck that Akrites, Chainguard’s Athena, and Project Lightwell are all racing to address.
I wish I could attend the event as the agenda and talks looked excellent.
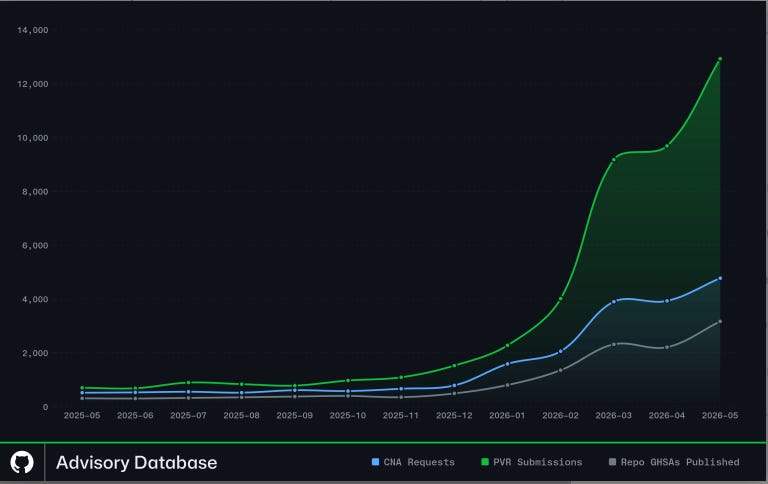
A candid account from the GitHub advisory team shows what happens when vulnerability volume breaks records.
In May 2026, the advisory team published 1,560 reviewed advisories, more than 5x typical monthly output and the all-time high. Private vulnerability reports surged from roughly 550 per week in January to over 3,000 per week in May. Repository advisories scaled from 650 to over 5,000 per week. GitHub CNA CVE requests reached nearly 4,000 in May alone, almost 10x year-over-year. Despite the surge, all reviewed advisories remain human-validated, but processing times have stretched from days to multiple weeks.
This is the same 66,000-CVE trajectory that FIRST projected, and GitHub’s transparency about the strain is more useful than most vendor communications about the problem. I dove into this topic recently in a discussion with Jerry Gamblin, who coauthored the FIRST mid-year update:
The NIST enrichment cutback story I covered last week now has additional data from Volerion research.
Of 13,441 non-rejected CVEs published between April 15 and June 15, only 6,759 actually received enrichment (roughly half), and only 2,645 of those also received a NIST CVSS vector.
The accuracy problems are as concerning as the coverage gaps. The most common scoring disagreement involves attack complexity, with NIST rating AC:L (low) where Volerion determined AC:H (high) in about a third of cases. One example saw NIST scoring CVE-2026-8856 at 9.1 Critical versus IBM’s own assessment of 7.7 Medium and Volerion’s assessment of 4.4 Medium.
The recommendation is to build your own decision trees rather than relying solely on CVSS scores from any single source, but that’s a massive lift for most organizations without the expertise and resources to do so.
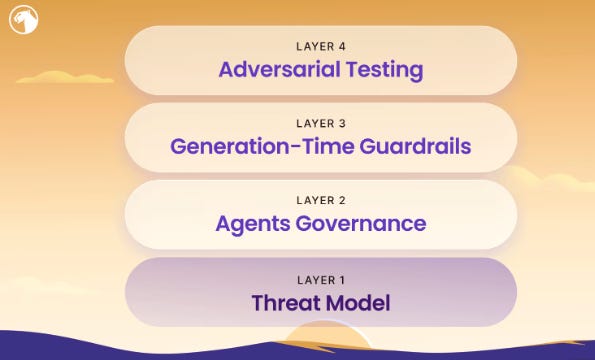
Traditional AppSec tooling is fundamentally inadequate for the agentic development era, and DevArmor’s proposed four-layer stack offers a useful corrective. Threat Architecture as a living context engine consumed by agents in real time, not a static compliance document.
Agent Governance with deterministic guardrails. Generation-Time Guardrails via rules files and MCP-connected services. And Adversarial Validation through continuous pen testing. The supporting data is worth noting. IDC found developers attribute 41% of code to AI generation, with roughly 40% accepted without revision. CISA found the long-standing “shift-left” claim that fixing vulnerabilities early is cheaper was never empirically validated, and Ramp’s autonomous patching pipeline patched 100 vulnerabilities in 6 days with zero human involvement.
The central insight is that threat models must evolve from static documents into structured knowledge graphs because AI agents lack the institutional context human developers carry.
A live supply chain attack campaign published at least 45 malicious copycat extensions on the Open VSX marketplace between June 26-29.
The campaign specifically targets AI and LLM tooling (DeepSeek, Gemini, Cursor AI, Claude, Ollama extensions) alongside general developer tools. The injected code creates a persistent local identifier and beacons to attacker-controlled infrastructure, with activation changed to “onStartupFinished” for automatic execution.
The current payload is reconnaissance and tracking rather than a full infostealer, but the attack path enables future escalation. Combined with the Air.security malicious skills research I covered last week and this week’s Claude Code vulnerabilities, the pattern is clear.
Developer tooling supply chains are the new attack surface, and the AI tooling market has inherited every supply chain vulnerability that npm and PyPI already struggle with.
Andy Gill makes the case that raw LLM prompting for security vulnerability research is “like supervising a room full of drunk toddlers” and that structured harnesses are the missing ingredient.
Using the RAPTOR framework as a primary example, the article shows how splitting work between a Python execution layer (runs tools) and a Claude Code decision layer (determines what to run and how to interpret results) can coordinate static analysis, fuzzing, and exploit generation into a coherent workflow.
The piece aligns with the broader pattern I keep seeing across Mozilla’s pipeline, Google’s Mantis, and every successful AI vulnerability discovery program. The model is necessary but not sufficient. The harness is where the real engineering happens, and this is a point AISLE, Niels Provos and many others have made now.
Disclose.io’s Policymaker tool walks organizations through a step-by-step process to generate a complete vulnerability disclosure program, including a full VDP policy, safe harbor clause, RFC-compliant security.txt file, and DNS Security TXT records.
Organizations can achieve maturity certification up to Level 5 (Full Safe Harbor with Coordinated Disclosure) and published domains are scanned into the Disclose.io Contact Database.
With 66,000 CVEs projected this year and AI-powered vulnerability discovery accelerating, every organization needs a functioning VDP. This tool removes the “we didn’t know where to start” excuse.
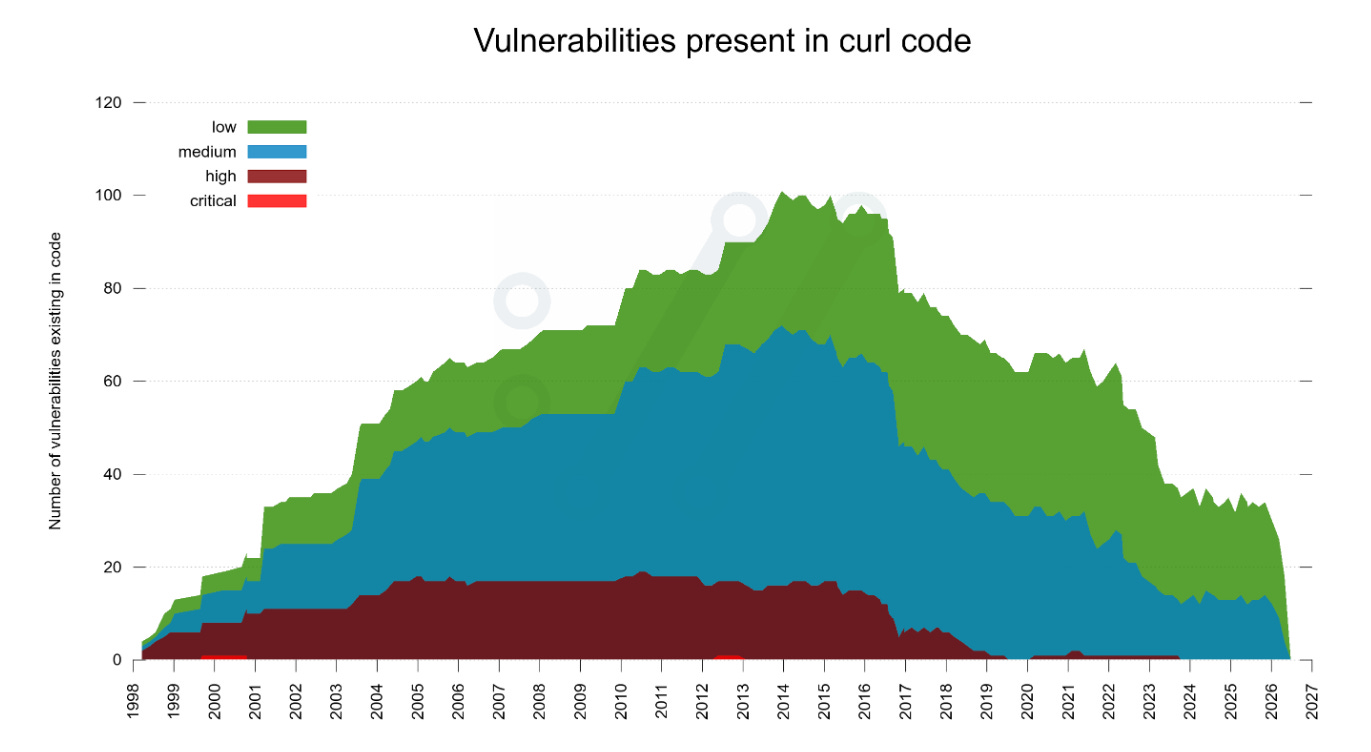
Following last week’s CVE dispute story, Stenberg created an animated visualization spanning 340 monthly snapshots from March 1998 to June 2026, showing how curl’s overlapping CVE version ranges have grown over time.
The mountain peaked at version 7.34.0 with 101 concurrent known vulnerabilities across 206 total CVEs. A notable drop around 2016 coincides with the Cure53 code audit and curl joining OSS-Fuzz in July 2017.
The visualization is a useful reminder that vulnerability management is not just about counting CVEs but understanding how they overlap, compound, and respond to investment in proactive security measures.
Final Thoughts
The Fable 5 re-release closes one chapter and opens another. The export control experiment proved three things.
First, emergency restrictions on commercial AI products create collateral damage that far outweighs the security benefit when the restricted capabilities are replicable in other models. Second, the capability diffusion problem is real and accelerating, with AISLE, GLM-5.2, and 360’s tools all demonstrating that restricting American frontier models does not restrict the underlying capability. Third, the governance infrastructure that emerges from a crisis (jailbreak severity frameworks, coordinated disclosure, independent validation) is more valuable than the restriction itself.
The thread that connects this week’s biggest stories, from Akrites to the Claude Code vulnerabilities to GitHub’s advisory database straining under record volume, is that the security infrastructure is being rebuilt in real time for a world none of the existing infrastructure was designed to handle.
The organizations that will thrive are the ones building their security architectures around the assumption of model abundance and model interchangeability, not model scarcity.
Invest in harnesses, not model dependencies. Build remediation capacity, not just discovery capability, and treat your AI agents with the same suspicion you would treat a new contractor with admin access, because that is functionally what they are.