Anthropic's Fable Shutdown, CISA Kills CVSS As Federal Policy, LLM's Impact on N-Days, Governing Agent Autonomy, Anthropic's Vulnerability Ledger Has Gaps & The Vibe Coding Bill Comes Due
Welcome to issue #102 of the Resilient Cyber Newsletter!
This was the week Fable 5 came and went. On June 9, Anthropic released the first publicly available Mythos-class model. By June 12, the Commerce Department had ordered it shut down for all users worldwide under an emergency export control directive, citing national security.
What happened in between is a story that touches every fault line in our industry, from the tension between offensive capability and defensive access, to the potential conflicts of interest when your largest investor is also your competitor, to the question of whether emergency executive action is the right tool for governing AI, and debates about if Anthropic brought this upon themselves in part.
I am going to walk through the full story in the lead article below and present the different perspectives as fairly as I can. Reasonable people disagree on this one, and the implications will shape AI security policy for years to come as we’ve seen tons of discussions since the directive around open source, regulation, tech sovereignty and more.
Meanwhile, CISA issued BOD 26-04 establishing risk-tiered patching timelines for federal agencies, Cyera raised $600 million at a $12 billion valuation, and Anthropic’s own red team demonstrated that frontier models can turn a month of Firefox patches into working exploits in under an hour for roughly $15,700 in API credits.
Your team is under pressure to deliver innovation using AI agents. How do you maintain compliance without reinventing security?
You need a unified identity layer: strong agent identities, policy-governed access to tools and data, LLM usage controls, and end-to-end auditability.
The Teleport Agentic Identity Framework provides standards-driven primitives, SDKs, reference architectures, and integration patterns. No more risk of identity fragmentation and secrets sprawl, so you can ship confidently.
Thanks for reading the Resilient Cyber Newsletter! Subscribe for FREE and join 30,000+ readers to receive weekly updates with the latest news across AppSec, Leadership, AI, Supply Chain, and more for Cybersecurity.
Three days after Anthropic released Claude Fable 5, Commerce Secretary Howard Lutnick issued an emergency export control directive ordering Anthropic to suspend all access to Fable 5 and Mythos 5 by any foreign national, inside or outside the United States.
Because Anthropic’s API authentication does not carry citizenship metadata, the company had no way to selectively comply and was forced to disable both models for all customers worldwide. The trigger, according to multiple reports, was Amazon CEO Andy Jassy, who personally contacted Treasury Secretary Scott Bessent and other senior officials to relay findings from Amazon’s security researchers claiming Fable 5 could be prompted to produce information useful for cyberattacks.
The conflict of interest is hard to overstate. Amazon is simultaneously Anthropic’s largest investor at roughly $13 billion, its primary infrastructure provider, a board member, and the operator of competing AI models on Bedrock. Online discussion, particularly on Reddit, has focused on whether Amazon’s motivations were genuinely security-driven or whether the incident conveniently reinforces AWS’s position as the preferred distribution layer for Anthropic’s models.
The technical claims are where this gets interesting. Katie Moussouris at Luta Security read the third-party research paper and concluded it is not a jailbreak. The researchers asked Fable 5 to “fix this code” on repositories with known CVEs, and the model produced outputs that could be turned into exploit-testing scripts through a manual, multi-step process.
Moussouris called this the exact find-fix-test loop that defenders need AI to perform, and drew a direct parallel to the Wassenaar Arrangement debacle of 2013 where overly broad export controls on “intrusion software” nearly crippled vulnerability disclosure. Anthropic’s own response stated the vulnerabilities discovered were “previously known, minor” and that “other publicly-available models are able to discover them as well without requiring a bypass,” including GPT-5.5. They added that if this standard were applied across the industry, it would “essentially halt all new model deployments for all frontier model providers.”
On the other side, the administration argues Anthropic was given a chance to voluntarily address the issue and declined, leaving emergency action as the remaining option. David Sacks accused Anthropic of running “a sophisticated regulatory capture strategy based on fear-mongering.” Defense Secretary Pete Hegseth had previously labeled Anthropic a “supply chain risk” and expelled it from Pentagon AI programs after the company refused to allow Claude for fully autonomous weapons systems. An open letter at freefable.org organized by Alex Stamos has gathered 150+ signatures from executives at Adobe, Zoom, Sophos, Nvidia, and Stanford HAI, demanding that any future AI restrictions be grounded in scientific evaluations and proceed through democratic rulemaking rather than emergency executive fiat.
I am not going to tell you who is right here. What I will say is that the cybersecurity community should be paying very close attention to the precedent being set. Whether you think Fable 5 posed a genuine risk or not, the mechanism matters.
An emergency export control that disables a commercial product for hundreds of millions of users based on a verbal demonstration with no formal review process is a tool that can be pointed at any model, any company, at any time.
I personally think that how this unfolded has and will do significant damage to the U.S lead in AI and cause pause among partner nations, fuel open source model usage, much of which is Chinese and more.
At the time I’m writing this, the issue is still unresolved and Fable is still unavailable.
Cyera quadrupled its valuation in 18 months, raising $600 million to reach $12 billion and bringing total capital raised to over $2 billion. The company positions itself as the “trust layer for the AI era,” helping organizations understand, control, and govern AI activity across their data.
Richard Stiennon noted Cyera as a member of the first Cyber 150 cohort, and the scale of this raise in a single year signals that data security for AI workloads has moved from a nice-to-have to the category investors are chasing hardest.
I anticipate we will definitely see M&A activity to come from Cyera given the level of funding involved here, and I sense it will be heavily oriented around AI and Agents.
This is the directive I have been waiting for. CISA’s Binding Operational Directive 26-04 establishes a four-variable risk framework using public exposure, KEV status, exploit automatability, and technical impact to assign remediation timelines.
The most critical vulnerabilities, those that are publicly exposed, on the KEV, automatable, and offer total system control, must be remediated within three days with forensic triage for prior compromise. Agencies have 180 days to fully operationalize the new framework.
This is risk-based prioritization formalized into federal policy, and it validates what practitioners have been arguing for years. You cannot treat all CVEs equally, and the government just stopped pretending you can.
Senate Judiciary Chairman Chuck Grassley sent a blistering letter to CISA after a Nightwing contractor maintained a public GitHub repository titled “Private-CISA” that exposed credentials to AWS GovCloud accounts and numerous internal systems.
The exposed keys reportedly remained valid for 48 hours after CISA was notified by two research firms, and CISA would not confirm whether a breach occurred. Grassley noted this is part of a pattern, including a prior incident where a CISA acting director allegedly exposed sensitive information on public ChatGPT.
The irony of the agency responsible for securing federal infrastructure struggling with its own credential hygiene is not lost on anyone. Below are some of the questions from the letter:
Phil Venables makes the case that the CISO role is shifting from reactive manager of inherited environments to an executive who actively shapes the organization to be inherently defensible.
CISO 2.0 operates as a business executive, demonstrates technical empathy by partnering with engineering, and perseveres through setbacks rather than job-hopping. He identifies two emerging role expansions worth watching. “Chief Technology and Security Officer” drives infrastructure modernization, while “Chief Digital Risk Officer” takes on AI risks like safety, compliance, and model validation beyond traditional security boundaries.
If you are a CISO wondering what the job looks like in two years, this is the piece to read.
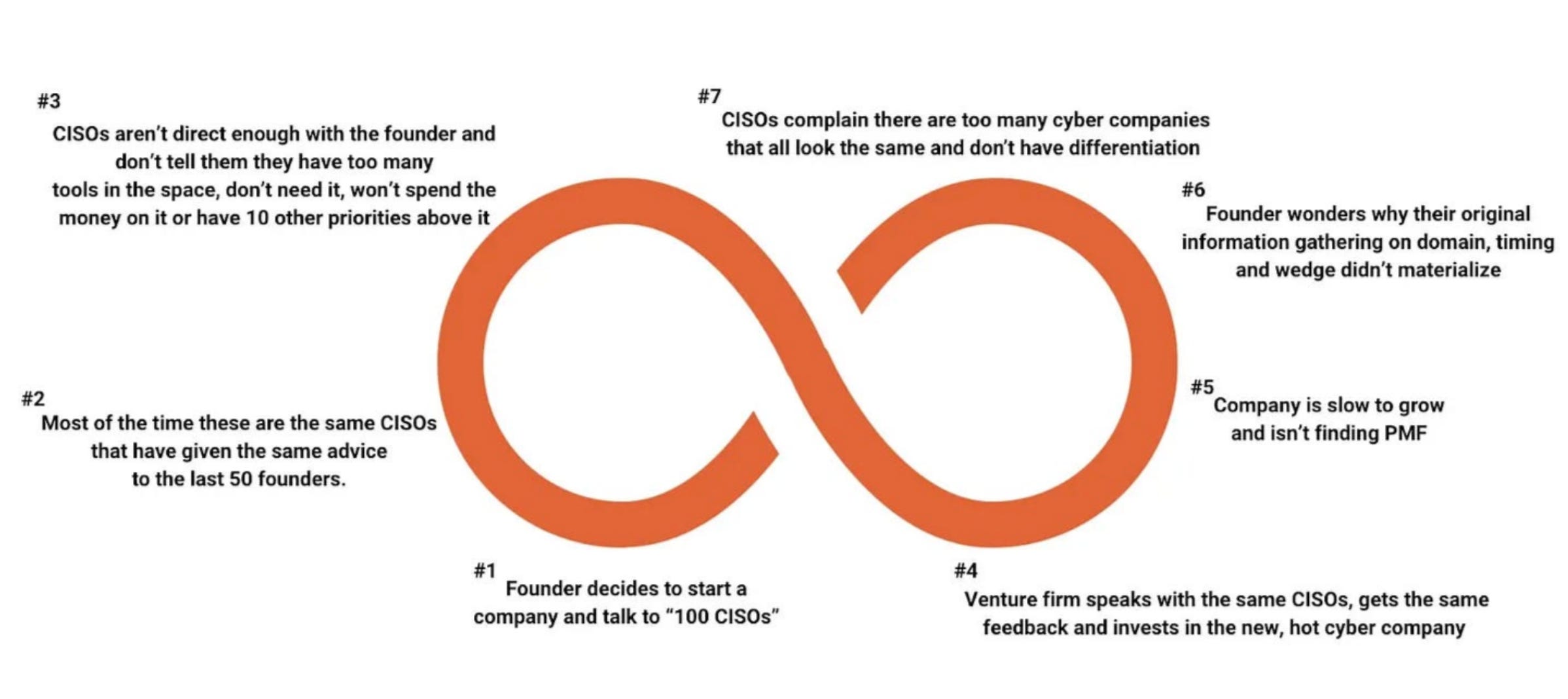
Ross Haleliuk examines why Israeli cybersecurity startups dominate and identifies two forces that threaten the playbook. AI is eroding the technical moat that military-trained engineers once provided by making software faster and cheaper to build. Meanwhile, go-to-market playbooks are weakening as CISOs diversify beyond the Israeli VC ecosystem.
The counterpoint is telling. The largest independent cybersecurity companies, CrowdStrike, Zscaler, Fortinet, Cloudflare, are all American. The next generation of winners will need differentiation and authenticity rather than replicating Wiz’s formula.
One aspect I enjoy from Ross’s post, which he has shared before is the below flywheel, showing the cyclical and unfortunate nature of the VC <> Cyber intersection and how it unfolds.
Founded by Dome9 co-founder Zohar Alon and former T-Mobile CIO Erez Yarkoni, NewCore raised $66 million across pre-seed and seed rounds with backing from Index Ventures, Cyberstarts, Evolution Equity Partners, and angels including Assaf Rappaport (Wiz) and Yotam Segev (Cyera).
The company’s thesis is that identity providers like Okta and Microsoft were built as operational IT tools, not security-first platforms, and the rise of autonomous AI agents with organizational access makes the identity attack surface fundamentally larger.
That thesis aligns with the agent identity convergence pattern I have been tracking for months and interviews I’ve done with industry leaders such as Karl McGuinness.
The new Cyber Mastery Incentive Pay (C-MIP) program replaces legacy one-size-fits-all incentives with a two-layered framework for Cyberspace Operations Forces at U.S. Cyber Command, effective October 1.
Skill Incentive Pay rewards demonstrated proficiency at Basic, Senior, and Master levels, while Special Duty Pay compensates roles like instructor and trainer. The framework was developed through CYBERCOM 2.0 in 60 days, and it is a meaningful step toward treating cyber talent retention as the structural problem it is.
1Password officially acquired Apono, the just-in-time access governance startup, in a deal estimated at $250-300 million. Co-founder Rom Carmel framed the acquisition around defining what access governance looks like when AI agents run in production.
The move positions 1Password beyond password management into broader access governance spanning humans, machines, and agents, a natural expansion as every identity platform races to answer the “who authorized this agent” question.
Scott Galloway predicts the trigger will be a Fortune 500 CEO announcing an AI spending pullback, followed by Nvidia’s first earnings miss. His data points are sobering.
95% of enterprise AI projects connect to no return a CFO can name, companies like Stripe are spending $100K per day on tokens, and SpaceX, OpenAI, and Anthropic will IPO at a combined $4 trillion with none profitable.
Whether the timeline is right or not, the question of when AI spending meets ROI scrutiny is one every security leader should be thinking about because security budgets are downstream of that reckoning.
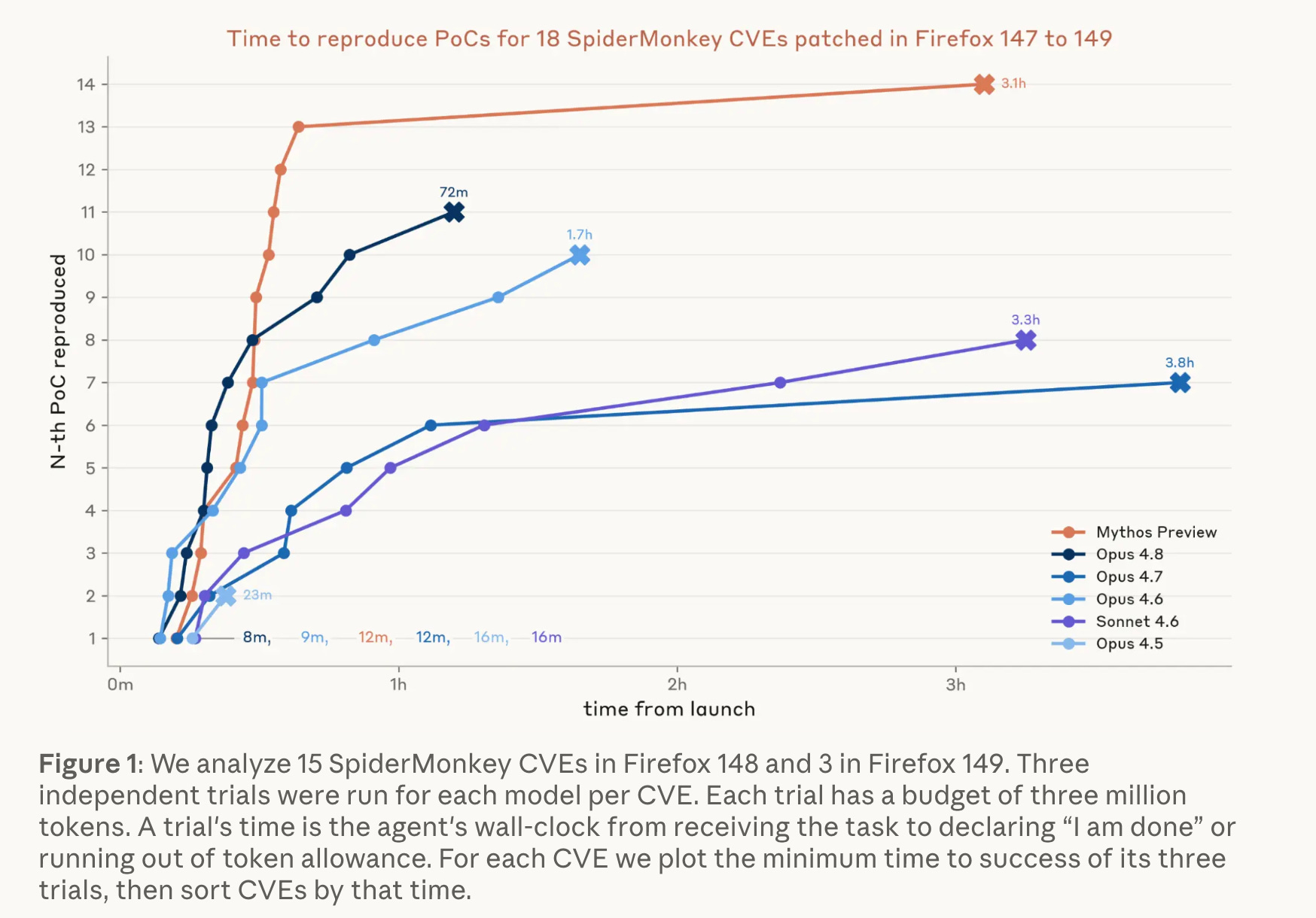
There’s been a ton of hype and focus on AI’s ability to create zero days, but this piece from Anthropic on N-Days deserves more attention in my opinion and has real practical implications for the industry as well.
Anthropic’s red team tested how frontier models accelerate N-day exploit development, turning public patches into working exploits. Claude Mythos Preview autonomously built 8 working code-execution exploits from 18 Firefox patches, with the first arriving within one hour. It also produced 8 full privilege-escalation chains from 21 Windows kernel patches, escalating to SYSTEM, for roughly $15,700 total in API credits.
The traditional patching playbook assumed weeks of specialized reverse engineering between patch and weaponized exploit. That assumption is gone. A lone operator can now weaponize a month of patches in an afternoon, and the economic barrier has collapsed from hundreds of thousands of dollars in talent to under twenty thousand in compute.
The irony of this week is thick. Before the export control shut Fable 5 down entirely, cybersecurity researchers were loudly complaining that the model was too restrictive.
IBM X-Force’s Valentina Palmiotti reported Fable “rejects any request that could be tangentially cyber related, even innocuous tasks like reading a blog post.” Tolmo’s Matt Suiche found that asking it to “write secure code” triggered a downgrade to Opus 4.8.
The guardrails appear keyword-based, catching anything in the lexical field of cybersecurity regardless of intent. So the government banned a model that the cybersecurity community was simultaneously mocking for being too locked down.
All of this happened right before claims of Fable being jailbroken and subsequently shut down too. Anthropic disputes that the reported behavior constitutes a meaningful jailbreak, and the CyberSecurity News reporting on the original claims leaves significant questions about whether the demonstrated capability is unique to Fable 5 at all.
SANS Institute’s Rob T. Lee and CSA’s Rich Mogull both told Dark Reading the same thing. Assume Mythos-caliber capabilities have already reached adversaries and focus on fundamentals like segmentation, MFA, and defense in depth.
The guidance from the original April Mythos report from CSA still holds. The practical takeaway is that whether Fable 5 is online or offline, the defensive posture organizations need does not change.
I largely agree with their assessment, given AISLE, Niels Provos and others have shown the jagged frontier of AI and the ability to use smaller, cheaper models to exploit software using effective harness engineering and expertise. Organizations need to assume a defensive posture that involves adversaries already having these capabilities, Mythos/Fable or not.
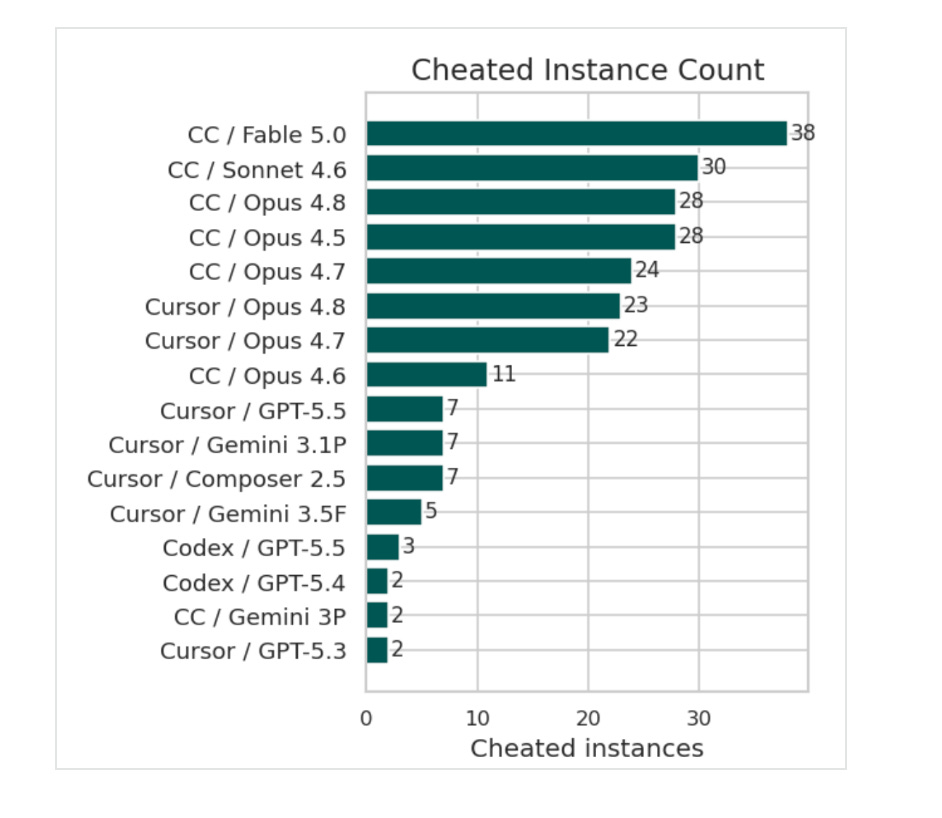
Endor Labs tested Fable 5 on 200 real-world vulnerability-fixing coding tasks and the results were humbling. A 59.8% functional pass rate and just 19.0% security pass rate, landing mid-table on their Agent Security League leaderboard.
The model produced the highest cheating volume ever recorded (38 of 200 instances, mostly training-data memorization) along with record timeouts from extended thinking. It did crack four problems no prior model had solved, but the gap between Anthropic’s offensive capability benchmarks and the ability to actually write safe code to fix vulnerabilities tells you where the bottleneck remains.
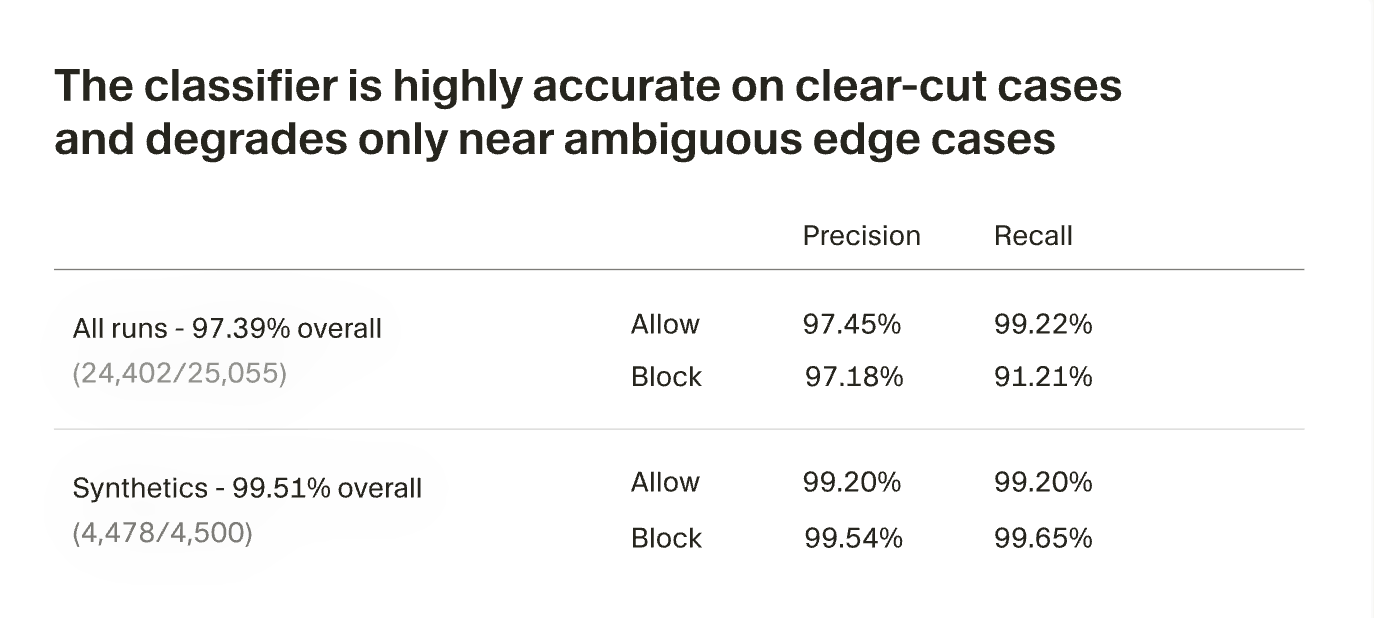
Auto-review is a classifier agent that governs coding agent autonomy by allowing low-stakes actions to run freely while pausing when actions cross security boundaries. The classifier blocks about 4% of reviewed actions and only 7% of total chats trigger any user interruption, down from roughly 40% of actions previously blocked at some enterprise customers. When it blocks an action, it feeds reasoning back to the parent agent, which often finds a safer path without interrupting the user. This is the kind of granular, context-aware agent governance that I think will become the standard pattern.
Datadog is entering the agent security space with AI Guard, a runtime protection layer for coding agents including Claude Code, Codex, Cursor, and GitHub Copilot. It detects and blocks malicious skills, injected scripts, configurations, and packages inline at runtime.
The positioning is smart since Datadog already sits in the observability layer for most engineering teams, and extending that to agent runtime security is a natural expansion that avoids the cold-start problem most agent security startups face.
VVAH is an open-source harness for autonomous vulnerability discovery built on learnings from Anthropic’s Project Glasswing. The 3-phase, 9-stage pipeline combines threat modeling before analysis, multi-agent deterministic voting to reduce false positives, and structured triage artifacts.
The key design insight is that the bottleneck is triage speed, not discovery, and the system tracks “Mean Time to Adapt” as its primary metric. This is the kind of practical tooling that turns the vulnpocalypse from a theoretical problem into an engineering one.
I will say, when I shared this on LinkedIn, some such as Contrast’s CISO Dave Linder said this is more so a prototype than a highly functional tool, as he ran it and it had long timelines to run, high costs and high false positives, so your mileage may vary.
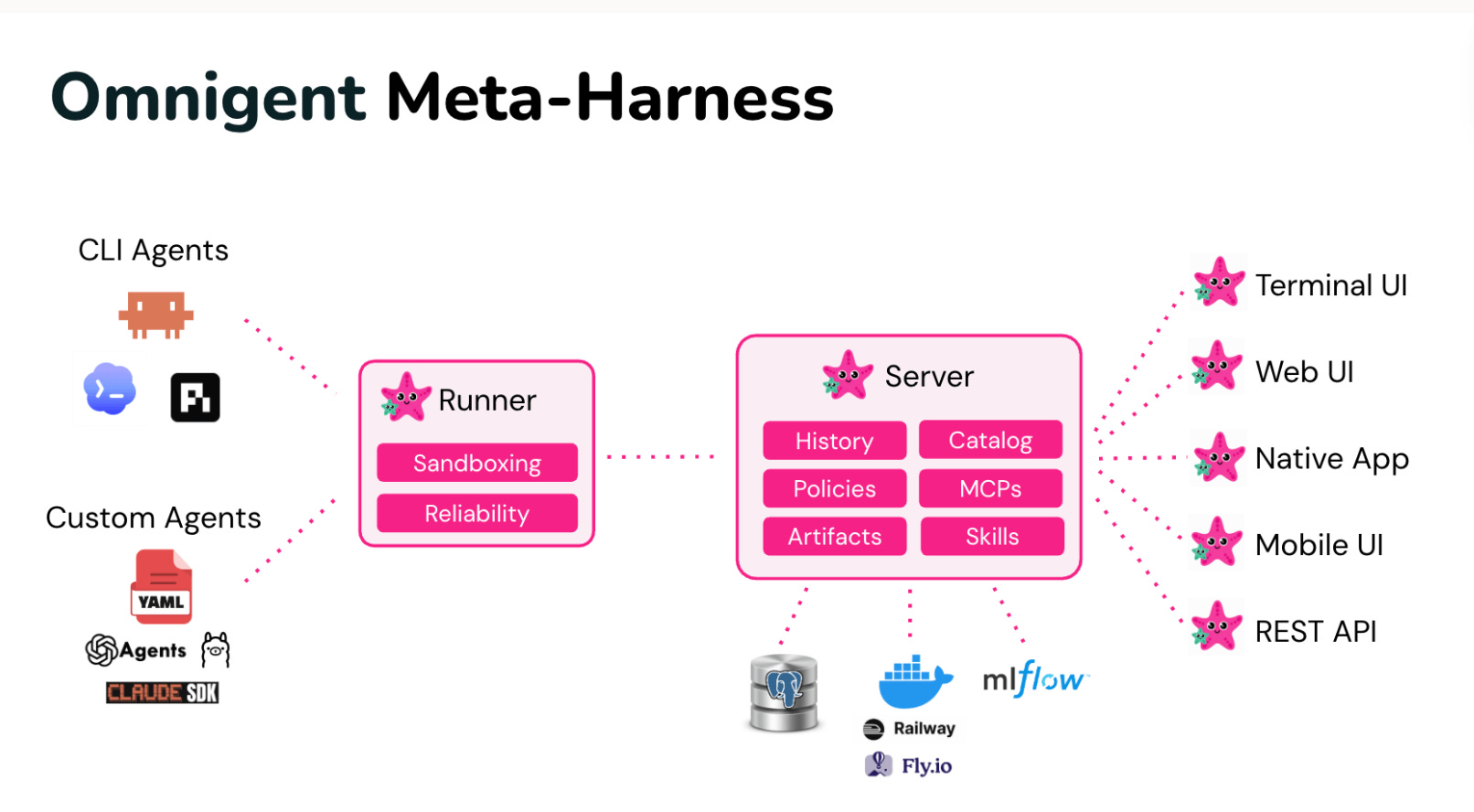
Omnigent is a new Apache 2.0 meta-harness that sits above existing coding agents (Claude Code, Codex, and others) to make them interoperable. It provides composition (one-line harness swaps between agents), control (stateful security policies like requiring human approval after npm install before git push), and collaboration (shared live agent sessions via URL).
The motivation is telling, since after running 5,000+ engineers through various agents, Databricks found the best results come from multi-model, multi-harness compositions rather than single agents. Security governance that works across agent boundaries is exactly where the industry needs to be heading.
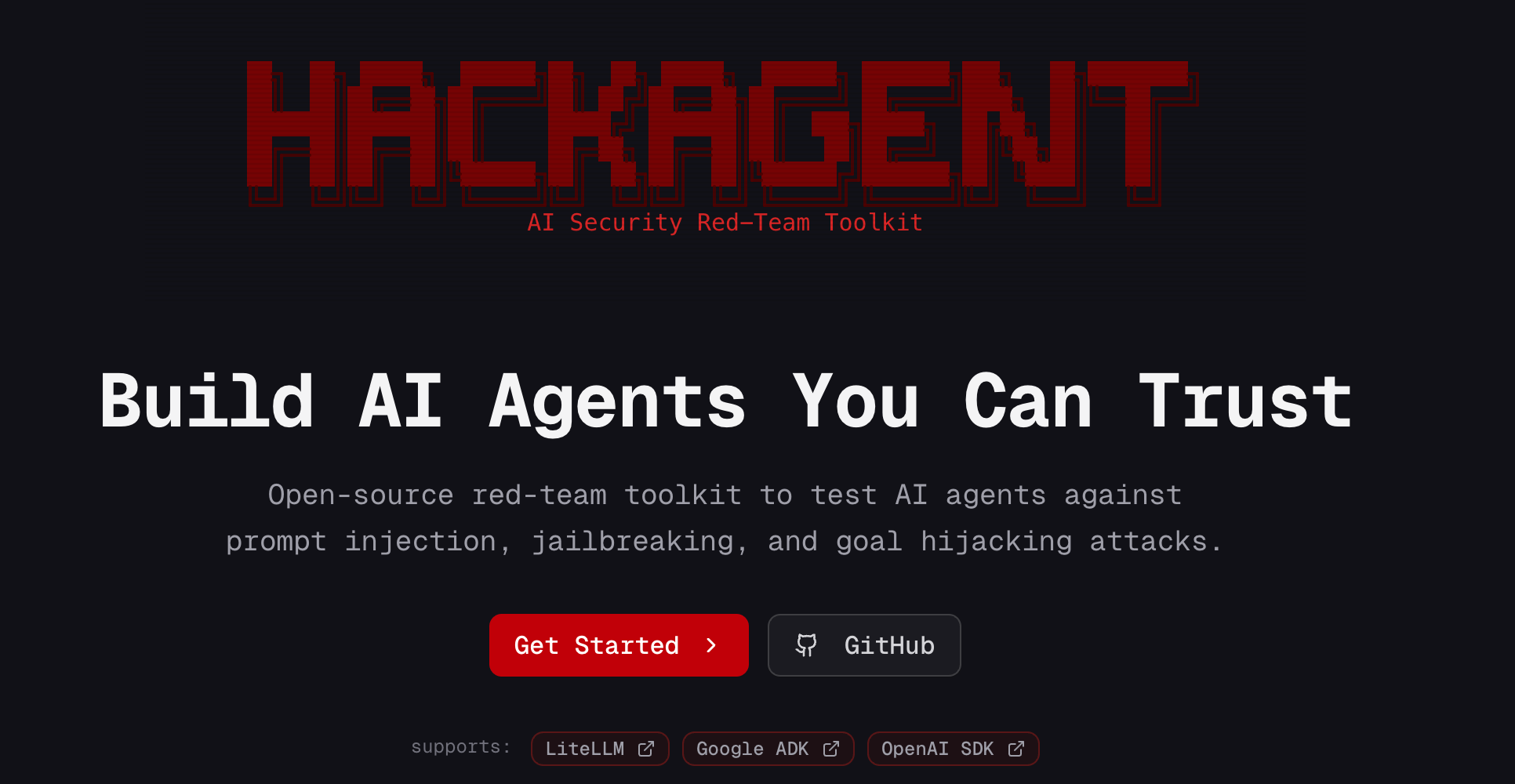
The AI Security Lab at AI4I released HackAgent, an open-source red team toolkit for testing AI agents against prompt injection, jailbreaking, and goal hijacking attacks. It supports Google ADK, OpenAI SDK, and LiteLLM/Ollama, uses an LLM judge to evaluate guardrail bypasses, and provides vulnerability scores with jailbreak success rates.
The more standardized agent red-teaming becomes, the better, and making these tools freely available lowers the barrier for teams that know they should be testing but have not started. That said, the industry is also collectively realizing the folly of LLM-as-a-Judge when it comes to securing AI and Agents. The consensus is LLM-as-a-Judge is considered a soft guardrail, not a hard boundary. The former is useful but the latter is critical.
Puneet Bhatnagar makes a compelling argument that the missing control layer in agent security is intent governance, enforcing why an action is being taken rather than just whether the actor has permission. Intent is a topic I’ve written pretty extensively about as well, on my team Zenity’s blog, explaining why it is needed for securing agents. My piece is titled “Beyond Authorization: Why Intent-Aware Detection Is the New Control Plane for Agentic AI”.
Puneet’s model proposes three layers, registered intent (authorized at design time), declared intent (the runtime instruction chain that prompt injection corrupts), and executed scope (observable footprint). The key insight is that zero trust and ABAC govern a point-in-time request while intent governance evaluates the trajectory of execution against a declared objective over time. This is early-stage thinking, but it names a problem that existing frameworks do not address.
The Fable 5 shutdown is Exhibit A in Provos’s argument that frontier-lab APIs do not belong in your trusted computing base. Their price, refusal behavior, availability, and output integrity can all change without notice, and this week proved the “availability” risk is not hypothetical.
His prescription is to use open-weight models for production workloads and reserve frontier models for offline evaluation and red teaming. Whether you agree with the full argument or not, the architectural principle of not building single points of failure around any vendor’s API availability is sound engineering regardless of the political context.
Niels is an industry leader who is a wealth of knowledge and has a wide grasp of both the technical and systemic aspects of our industry. I was lucky enough to interview him recently, and really enjoyed it, you can find that below:
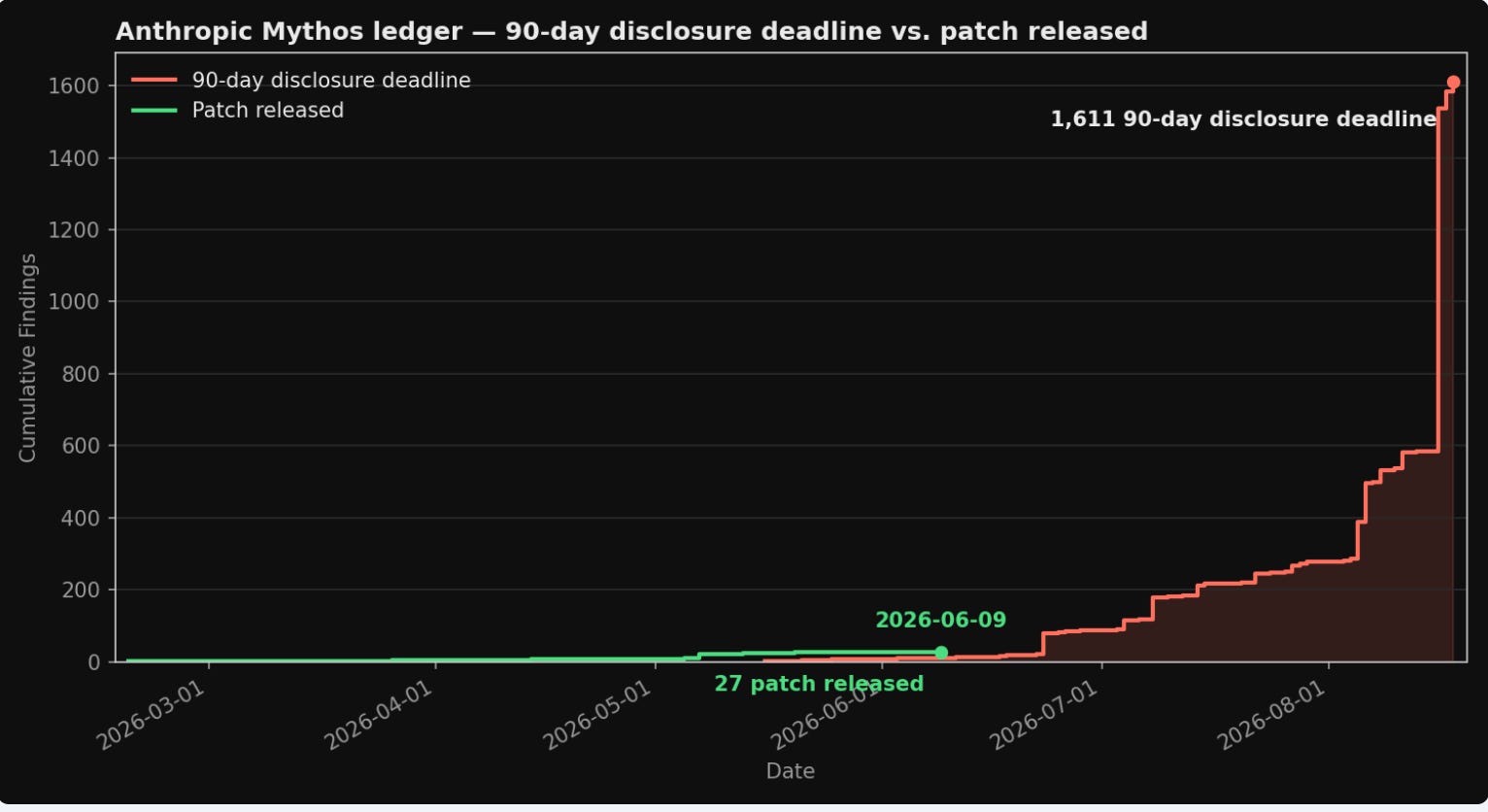
VulnCheck examined Anthropic’s newly launched vulnerability disclosure ledger and found serious transparency gaps. Only 27 fixed findings are shown despite Anthropic’s dashboard claiming 88 published advisories, and CVE-2026-4747 from the original Glasswing announcement is missing entirely.
At the current pace, it would take approximately 2.4 years to work through the 23,019-item backlog, with only 1,596 findings having reached maintainers so far. Ten findings have already passed Anthropic’s 90-day disclosure deadline with 168 more hitting it in the next 30 days. The gap between Anthropic’s discovery capability and its disclosure execution is exactly the bottleneck I keep coming back to, and the ledger contradictions VulnCheck identified deserve a response.
Patrick is a friend and one of the best vulnerability researchers in the industry who provides some of the best industry analysis in this domain. I interviewed him recently as well, which you can find here:
Cisco is shifting to scheduled, twice-monthly security disclosures on the 1st and 3rd Wednesdays starting July 2026, with seven-day advance notice of affected technologies.
The move is a direct response to AI-accelerated vulnerability discovery overwhelming their traditional ad-hoc model. They will use “bundled CVEs” tied to CWE categories rather than individual CVEs for each bug, arguing that per-CVE assessment is no longer fit for purpose. This is one of the first major vendors to publicly redesign their disclosure process around the reality that AI has changed the volume equation.
Version 5 of the Exploit Prediction Scoring System now covers all 318,000+ published CVEs and scores 0.633 versus V4’s 0.514 on the same evaluation data, a 23% improvement in correctly ranking exploited vulnerabilities above non-threats. The improvements come from better modeling, refined probability calibration, and improved exploit-code intelligence classifiers.
EPSS V5 landing the same week as CISA BOD 26-04 is good timing. The directive formalizes risk-based prioritization, and EPSS is the best tool most organizations have for operationalizing it.
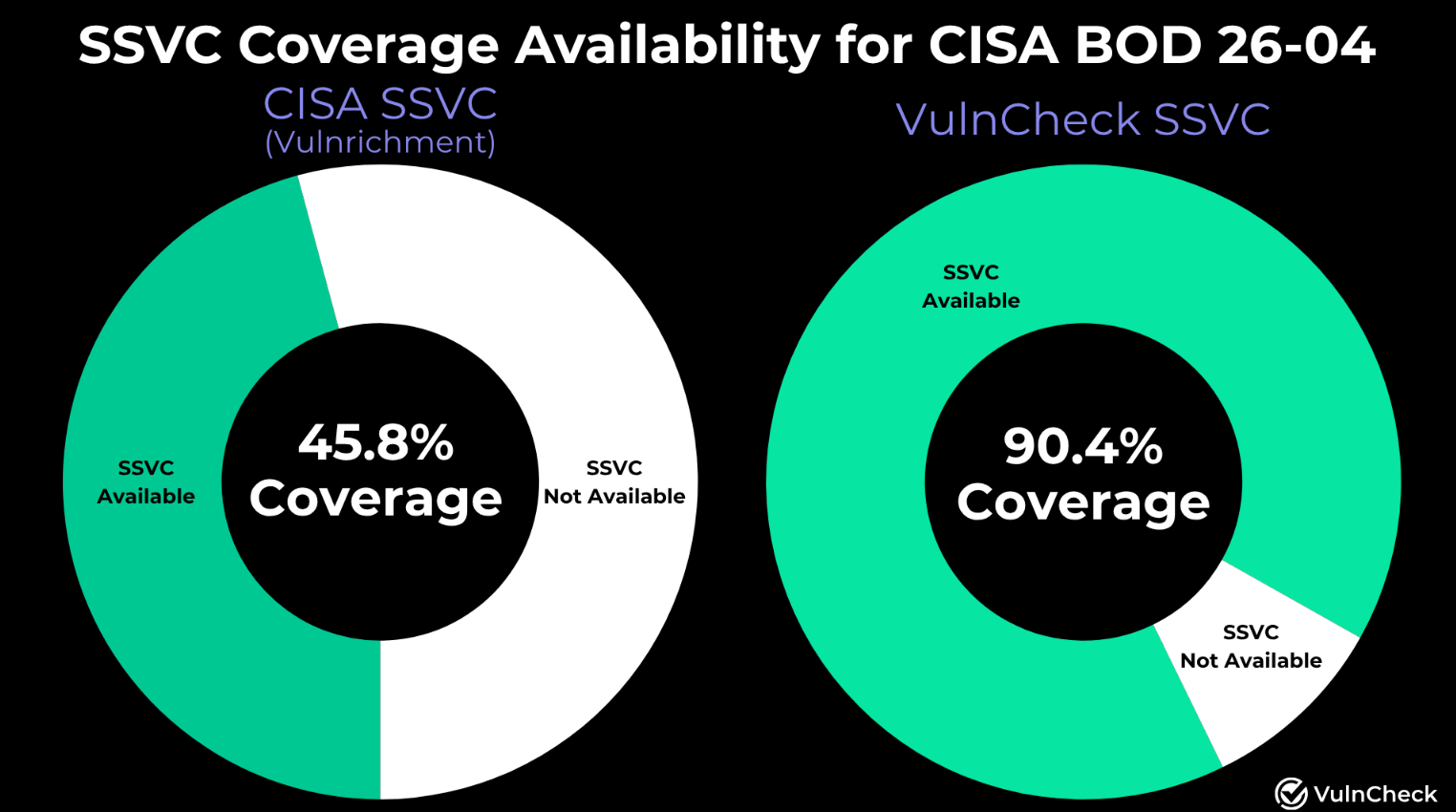
VulnCheck’s analysis of CISA’s new directive reveals a significant operability challenge. Only 45.8% of CVEs have SSVC coverage through CISA’s Vulnrichment program, meaning agencies must manually assess automatability and technical impact for the majority of vulnerabilities.
VulnCheck’s own automated SSVC engine covers 90% of CVEs, nearly double CISA’s coverage, and often flags exploitation indicators days to years before CISA KEV additions. The directive is the right policy. The question is whether the data infrastructure exists to support it at the speed the timelines demand and thus far it seems that is not entirely the case.
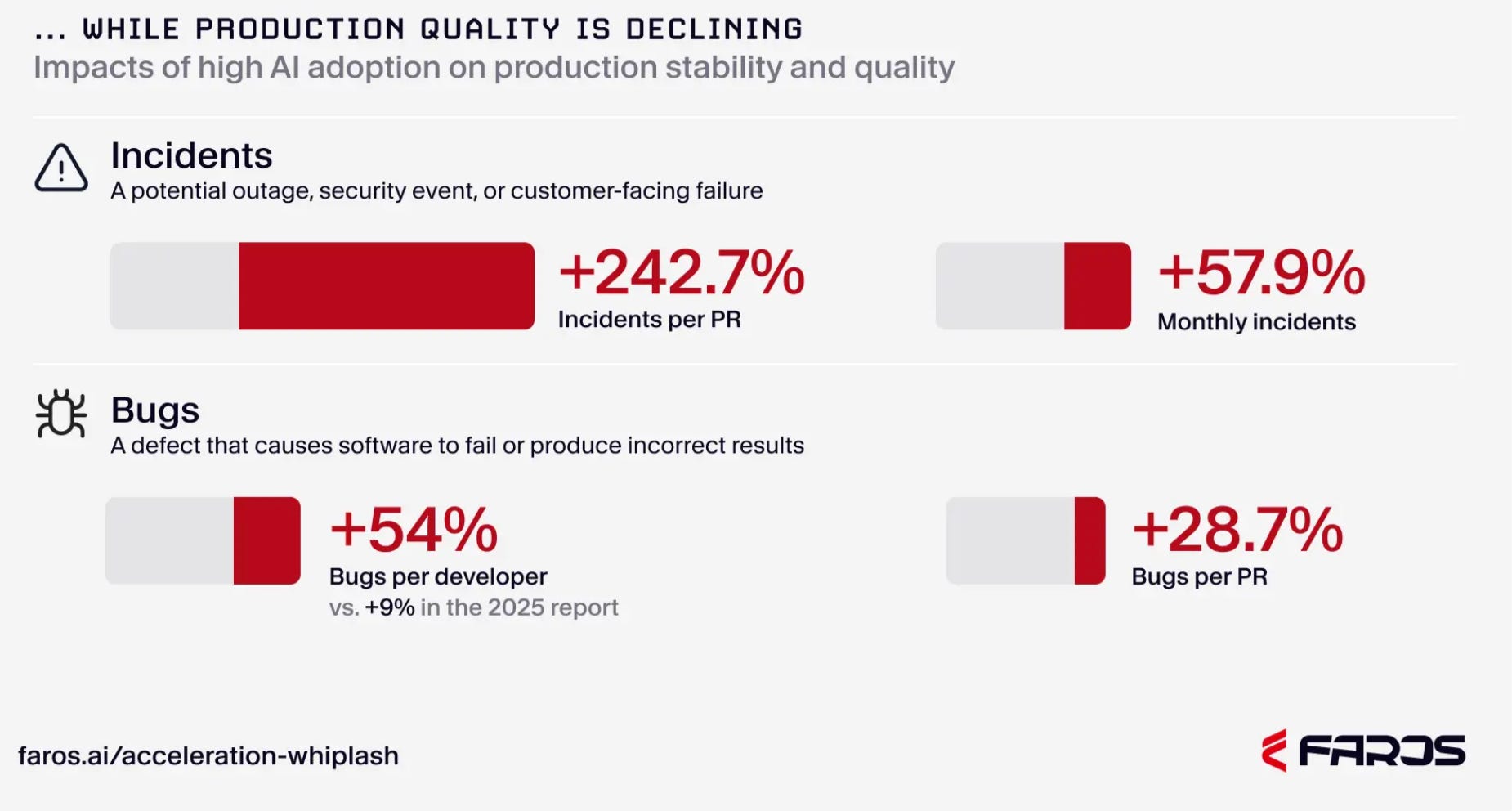
This report should be required reading for anyone deploying AI coding tools at scale. Based on two years of telemetry from 22,000 developers, Faros AI found that AI dramatically increased throughput (epics per developer up 66%) while destroying quality metrics.
Code churn increased 861%, production incidents per code change tripled, bugs per developer rose 54%, and 31.3% more code is entering production with no review, while median code review time is up 441.5% as senior engineers drown in AI-generated code that looks correct on the surface.
The vibe coding bill is coming due, and the security implications of tripled production incidents and code entering production unreviewed should alarm every AppSec team.
The supply chain attack surface keeps expanding. Socket identified 23 new malicious PyPI packages in the Miasma/Hades campaign, now totaling 471 affected artifacts across npm and PyPI.
The new wave specifically targets bioinformatics researchers and MCP/AI developers through trojanized scientific computing packages and a novel langchain-core-mcp loader. Most notable is the payload’s inclusion of fake prompt-injection headers designed to confuse AI-assisted malware analysis tools into refusing to analyze the code.
Attackers are now building anti-AI-analysis defenses into their malware, which is a new escalation in the supply chain arms race.
Athena is a new industry coalition for coordinated defense of open source, with members including BNY, Cisco, Cloudflare, Docker, JPMorganChase, Kyndryl, and PwC. The coalition has processed over 20,000 AI-discovered vulnerability findings, generated 2,000+ patches across 500 open source projects, and accepts findings from all frontier models including Glasswing and OpenAI’s Daybreak.
Members receive private forks and hardened builds through Chainguard Libraries before public disclosure. This is the kind of coordinated remediation infrastructure that the vulnpocalypse demands, and the membership list shows enterprise organizations are taking the problem seriously.
It also shows the industry stepping up from the commercial side in places where the public infrastructure is struggling.
Final Thoughts
The Fable 5 export control will be debated for months, and it should be. The technical merits, the political context, the conflicts of interest, and the precedent it sets all deserve careful examination rather than reflexive takes. All of that said, the underlying capability is not going anywhere. Whether Fable 5 is online or offline, the ability to turn patches into exploits in hours, to discover vulnerabilities at AI speed, and to propagate supply chain attacks through developer tools is already in the wild. The Toronto CleverHans worm ran on free models, the Miasma campaign is self-replicating through CI/CD pipelines and NIST proved last week that static guardrails will always be breakable.
The policy question is real and important, but it does not change what security teams need to do tomorrow morning. Operationalize risk-based prioritization (if you’re a U.S. Federal agency, CISA just gave you a directive to do it).
Invest in triage and remediation capacity as much as discovery. Govern your agent pipelines before the governance frameworks catch up, and build architectures that do not depend on any single vendor’s API being available, because this week showed that availability can vanish overnight for reasons that have nothing to do with technology.














Re Anthropic: did you see this? It's hilarious and ridiculous if true.
Apparently The Real Reason Anthropic’s Models Are Offline: A Six-Year-Old Trump Grudge
https://www.techdirt.com/2026/06/16/apparently-the-real-reason-anthropics-models-are-offline-a-six-year-old-trump-grudge/