

If you’ve been around cybersecurity for some time, you’ve inevitably heard of “Threat Modeling”. While there are many interpretations and opinions, one definitive explanation of Threat Modeling is from the Threat Modeling Manifesto, which describes it as:
"Threat modeling is analyzing system representations to highlight concerns about security and privacy characteristics”.
It often involves four fundamental questions, popularized by security pioneer Adam Shostack, which are:
What are we working on?
What can go wrong?
What are we going to do about it?
Did we do a good enough job?
It seems simple enough on the surface, and is accessible to nearly anyone in the industry, including those outside of security, who often are responsible for writing the code, building the system, and doing the “thing” that needs to be secured.
Given its widely accessible nature and various implementations and thought processes, it shouldn’t be surprising that there are also various threat modeling frameworks.
These include:
STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege)
LINDDUN (Linking, Identifying, Nonrepudiation, Detecting, Data Disclosure, Unawareness, Noncompliance)
PASTA (Process for Attack Simulation and Threat Analysis)
None of these are necessarily right or wrong, and there are several other variations. My fellow cybersecurity enthusiasts will and can passionately debate why one framework is better than another, why we may not need them at all, and everything in between.
Debates and enthusiasm aside, Threat Models are great mental models for thinking about systems and software and how they can be exploited and, conversely, secured.
Frameworks tend to evolve over time, and new options are introduced. Today, I’m writing to discuss a new threat modeling framework I’ve been following that I have found helpful when approaching agentic AI architectures and systems, which are poised to see tremendous growth in the coming years.
So, with that context, let’s dive in and look at MAESTRO.
MAESTRO - An Agentic AI Threat Modeling Framework

First, every Threat Modeling framework MUST have a mnemonic (sorry, I don’t make the rules!).
MAESTRO stands for Multi-Agent Environment, Security, Threat, Risk, and Outcome, and was created by my friend Ken Huang, with whom I’ve had the honor of participating in some panels and contributing to some of his books on AI Security.
Now, you may be saying What the hell, yet another framework (YAF)? However, as Ken points out, there are some nuanced aspects of Agentic AI that the existing frameworks don’t address and warrant a new entrant in MAESTRO to address those gaps.
Ken lays out those gaps in a Cloud Security Alliance (CSA) article on Maestro, which I definitely recommend reading fully (after my article, of course!).
The gaps he lists are:
Autonomy Related Gaps
Machine Learning (ML)-Specific Gaps
Interaction-Based Gaps
System Level Gaps
As Ken argues, the historical threat modeling frameworks have several gaps. These include examples of agents' autonomous nature and independent decision-making, which can often be unpredictable, especially regarding probabilistic non-deterministic models.
The ML-specific gaps can include examples such as data poisoning and model extraction, where malicious actors seek to compromise novel aspects of AI models, such as their training data, or extract sensitive and even proprietary elements of the models in use.
The interaction-based gaps deal with the fact that agents will interact both internally and externally, which will be facilitated by emerging protocols such as Model Context Protocol (MCP) and Agent2Agent (A2A). These protocols are emerging to help facilitate agents' interactions with external services, tools, and systems, and internally among themselves in multi-agent architectures.
Below is an image that helps demonstrate their respective roles: MCP for internal and external interaction with tools, services, and systems, and A2A for its ability to facilitate inter-agent interactions.
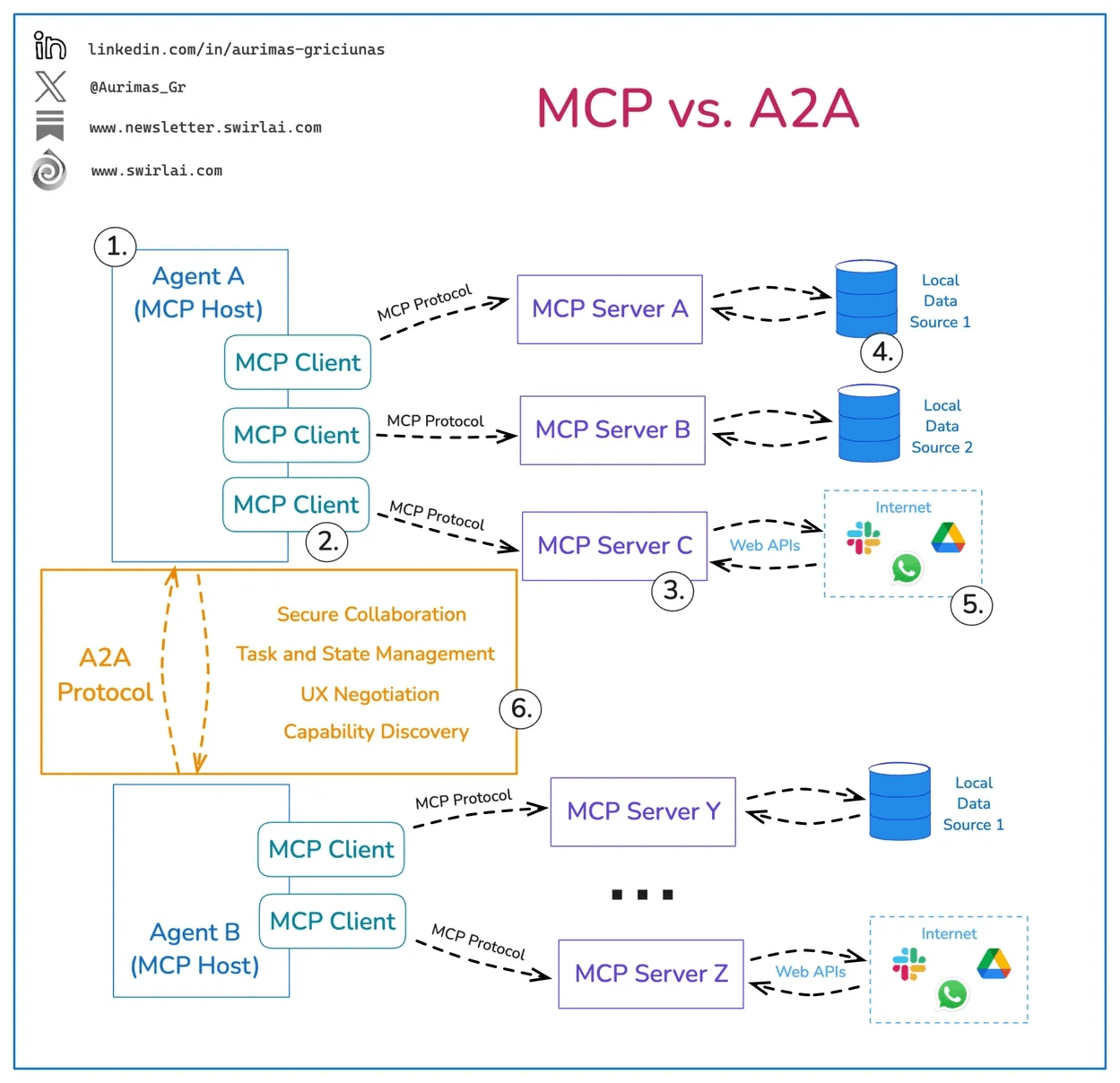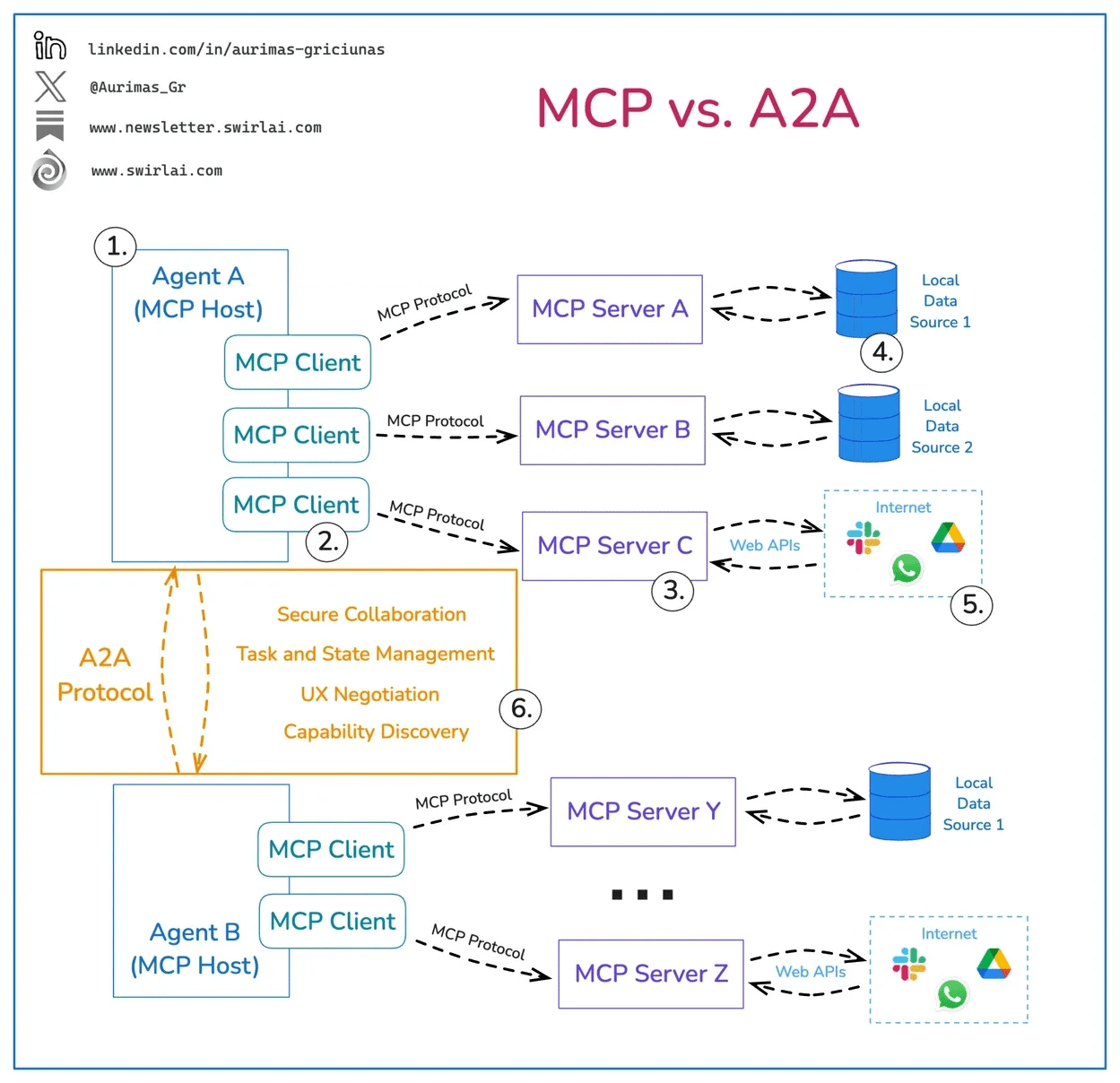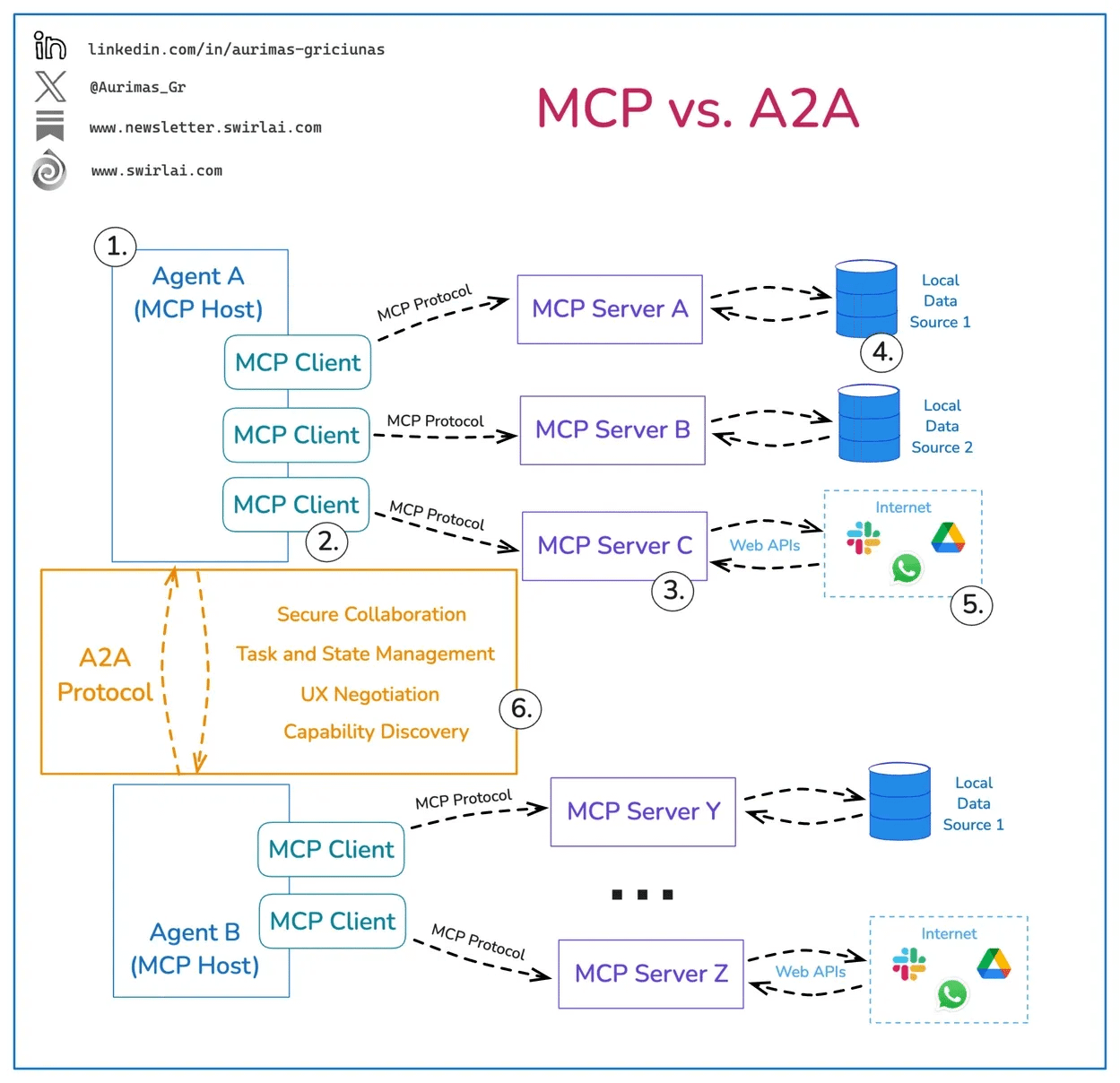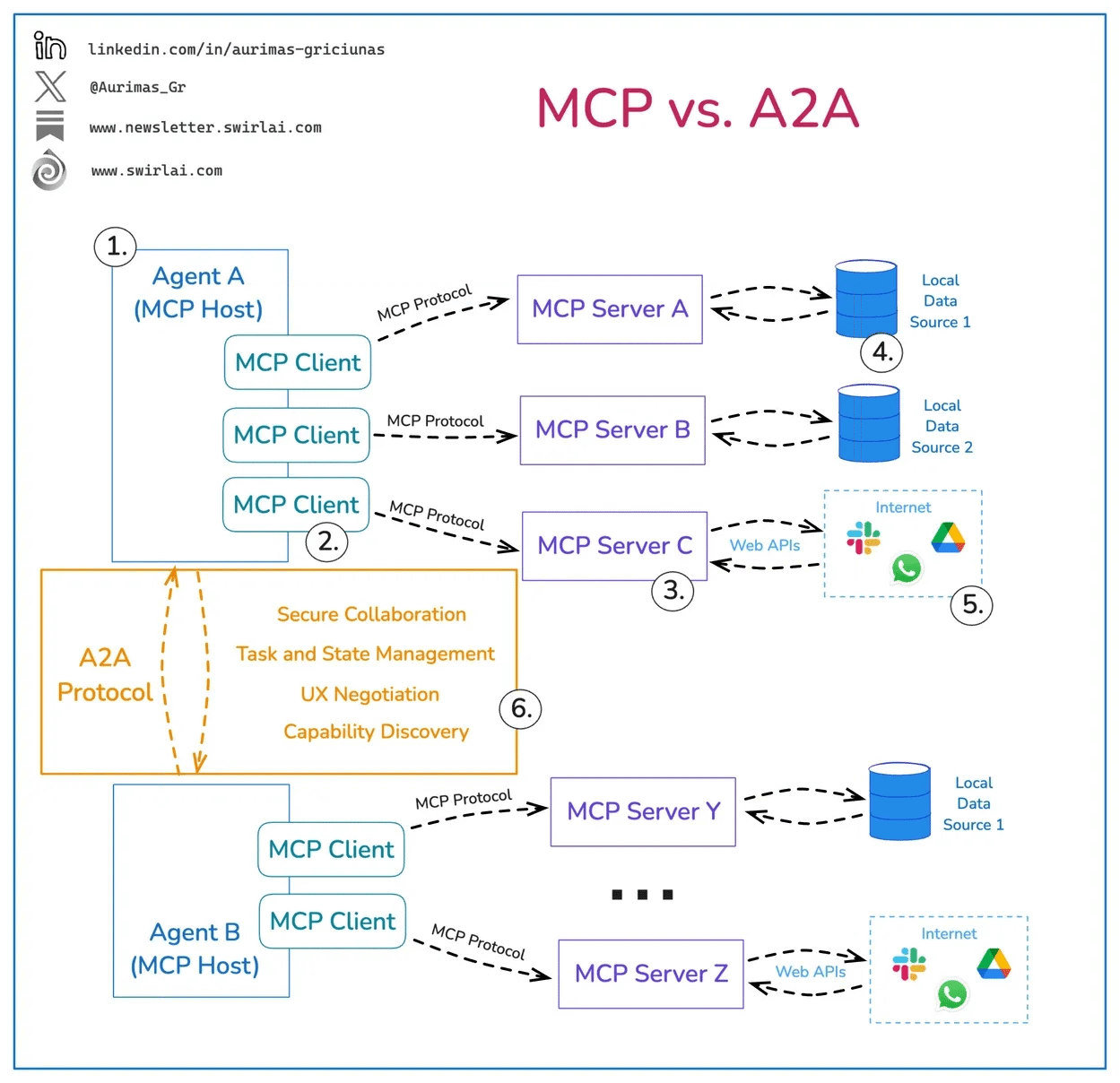
That said, MCP and A2A also have potential vulnerabilities and challenges. The image below demonstrates some potential vulnerabilities of MCP.
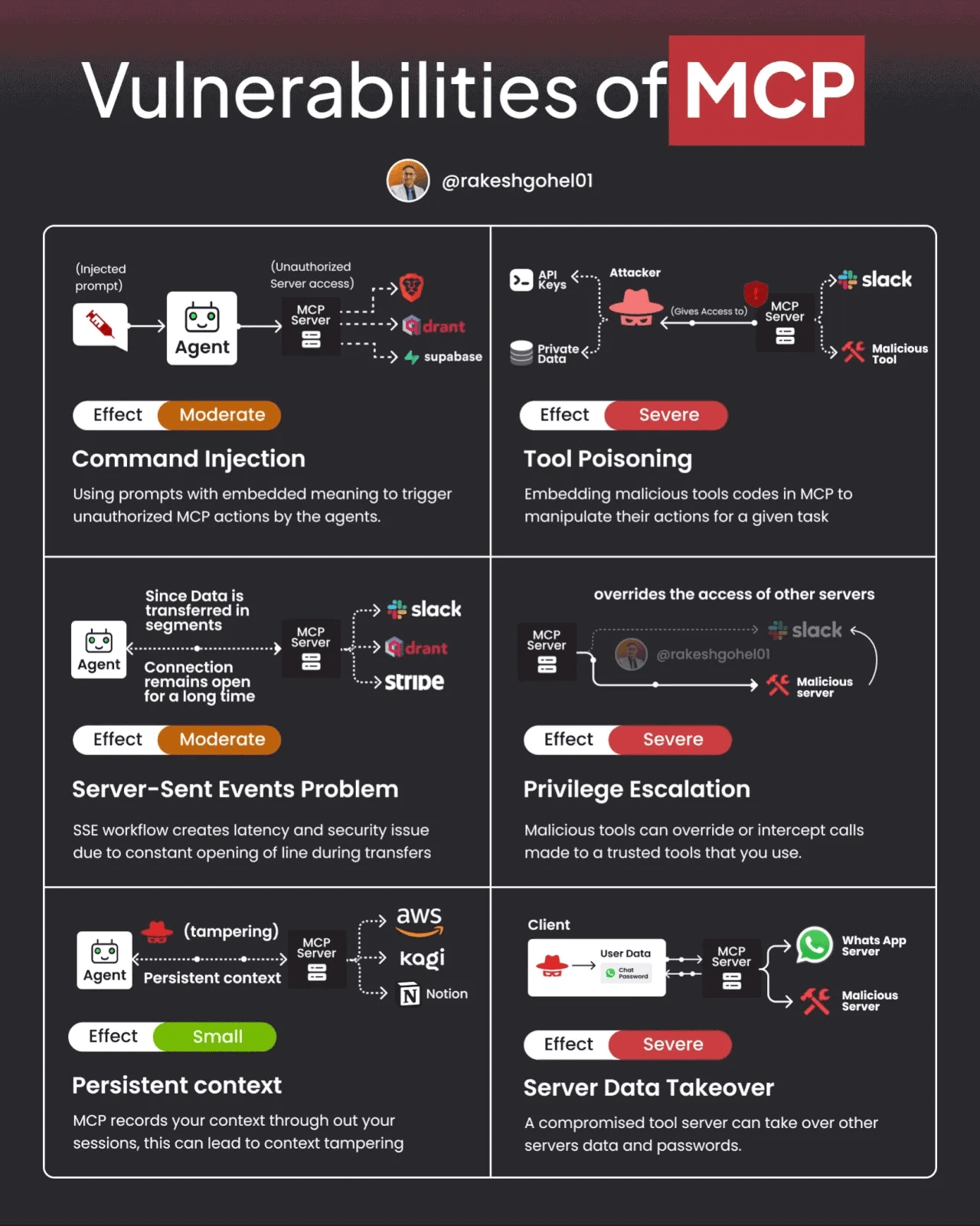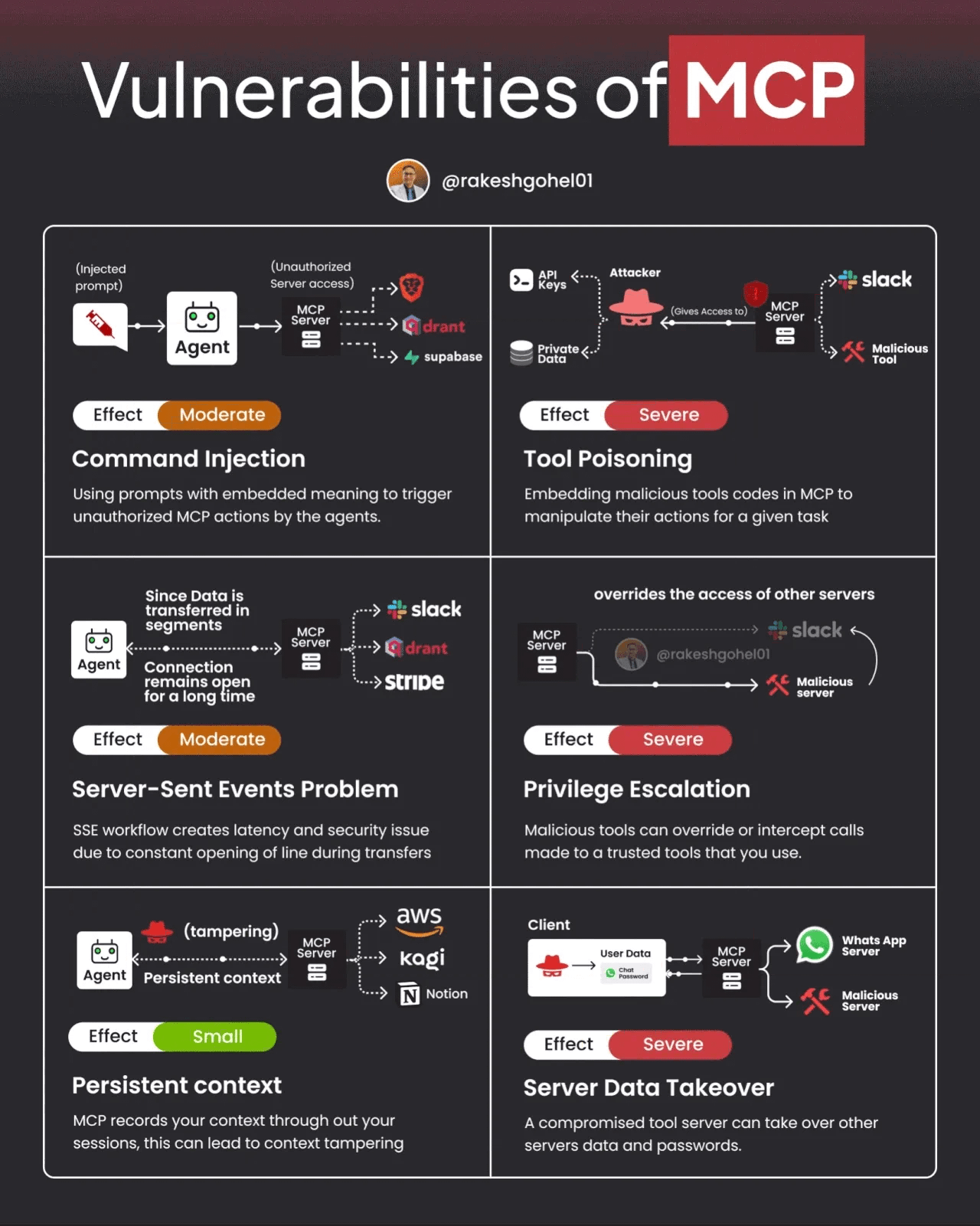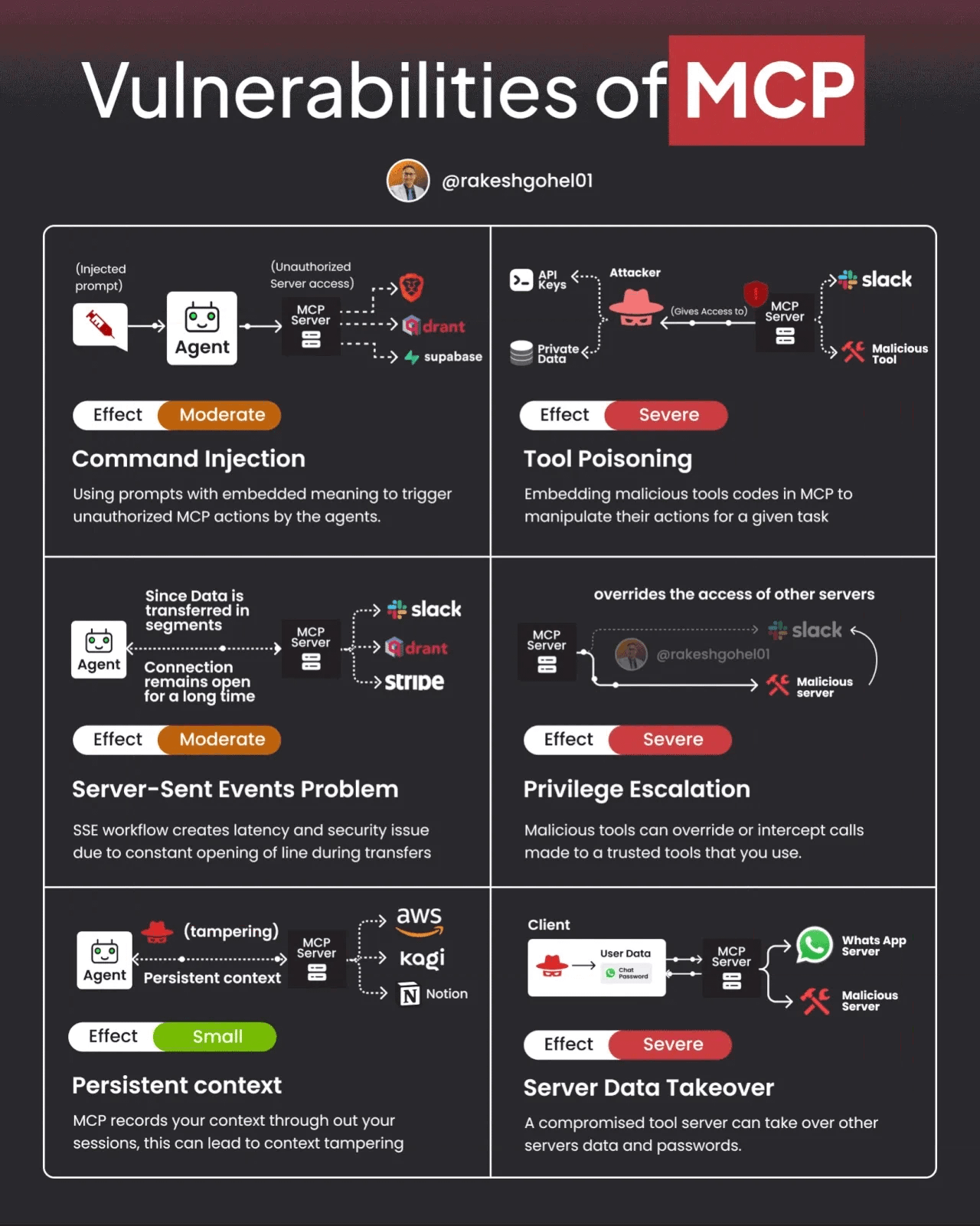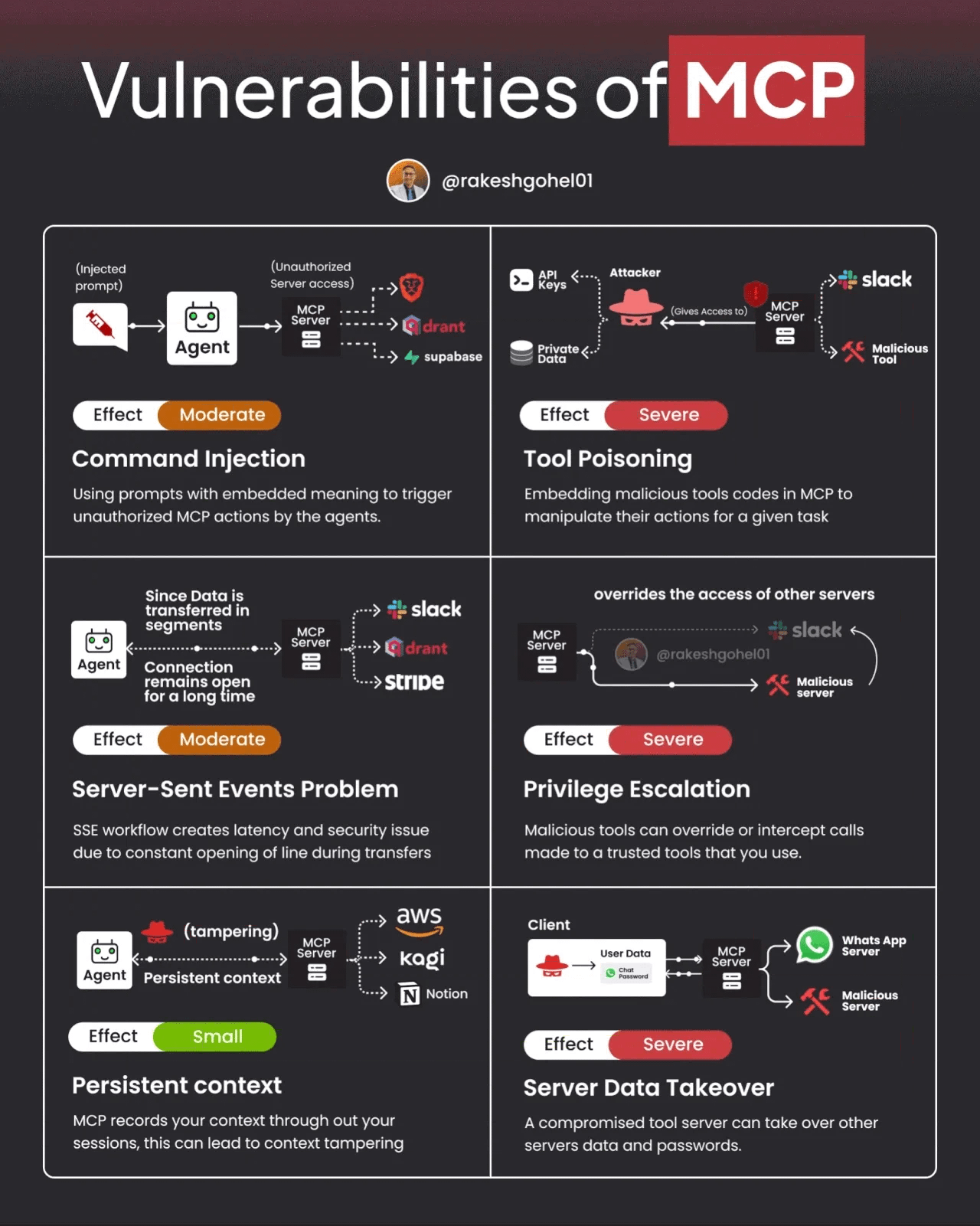
Ken and other researchers recently published a paper demonstrating the real-world application of MAESTRO to MCP and A2A. We’ve also seen security researchers demonstrate vulnerabilities in protocols such as MCP that can be used to undermine agentic systems. Below, you can see an image from the paper where they list common A2A multi-agent system threats they identified via the MAESTRO threat modeling methodology.

Lastly, Ken argues that the system-based gaps warrant the introduction of MAESTRO, including examples such as a lack of explainability and auditability in AI models. This particularly applies to proprietary non-open source models, whose inner workings may not be fully known or even fully understood, as the AI model’s complexity is challenging. Even now, additional research continues to emerge to explain complex models' functionality and activities.
Ken also cites supply chain concerns for AI models, including compromised pre-trained models, vulnerabilities in ML libraries, and a lack of provenance for model training data.
As you can see, Ken created MAESTRO to cover unique nuances of AI-specific systems, including models, agents, autonomy, and the environmental factors associated with the systems the models and agents are operating within.
The 7 Layers
A fundamental aspect of MAESTRO is the 7-layer reference architecture for agentic AI. I found this aspect particularly useful when considering agentic architectures and some of their unique threats, risks, vulnerabilities, and potential mitigations.

Above is an excellent visualization documenting each of the layers. Let’s briefly walk through each layer to better understand some of the potential risks and key considerations from a security perspective.
This layer-specific approach to the MAESTRO threat modeling framework lets practitioners work through the key aspects of the agentic architectures and the unique risks and considerations associated with each layer.
Layer 1: Foundation Models
While you don’t necessarily have to start from lowest to highest, I think looking at the models makes sense and building out from there in some context. Foundation models are often, but not always, LLMs and have some unique threats and risks to consider.
Ken cites examples such as Backdoor Attacks, Data Poisoning, and Adversarial Examples, such as malicious prompts, among other potential risks. This is far from an exhaustive list, as other references such as MITRE ATLAS, which is modeled after MITRE ATT&CK but focused on AI-specific threats and provides real-world examples of tactics and techniques that can be used to target AI systems.
I’ve covered MITRE’s ATLAS in a previous article titled “Navigating AI Risks with ATLAS”. I also interviewed Dr. Christina Liaghati of MITRE on ATLAS, which can be seen below:

I’ll add that there are some unique considerations regarding the models in terms of whether you are utilizing an open source model, from popular platforms such as HuggingFace, or consuming it from a model service provider (e.g. OpenAI) where you don’t have the same level of transparency of both the model as well as the underlying infrastructure, hosting environment and more that you would with a self-hosted open source model.
As with cloud computing before it, you’re making trade offs and leaning into a shared responsibility model. Just remember, you can’t outsource accountability, you keep that regardless.
While not perfect, my friend Mike Privette at Return on Security took an early swing at an “AI Security Shared Responsibility Model”, see below:

Layer 2: Data Operations
This layer of the model deals with the data the AI agents interact with, which may be stored, processed, prepared and transported. Data is ultimately what we’re protecting and what the adversaries are after in most cases.
Key threats Ken calls out tied to this layer include: Data poisoning, exfiltration, tampering, and model inversion/extraction among others. This involves looking to manipulate the data the model is trained on, exfiltrated sensitive data, which may vary depdending on the organization and use cases, compromising the integrating of the data and even looking to “steal” the model through API’s, prompts, and reconstruction.
A real world example of this is when one of the leading foundation model providers OpenAI claimed that China’s DeepSeek “stole” their model or at least heavily utilized ChatGPT to train its competitor DeepSeek, which caused massive headlines when it was released showing promising performance at much lower costs and requirements than competitors, and has seen significant adoption since.
The claim was that DeepSeek built a massive database of ChatGPT 4o responses as training data, subsequently used to train their own model.
Layer 3: Agent Frameworks
With the rise of agentic AI, we’ve seen numerous agent frameworks emerge and evolve to help facilitate their implementation and operation in complex enterprise environments. While there are many examples, some include Microsoft’s AutoGen, LangChain, CrewAI and LlamaIndex.
Some of the novel threats Ken enumerates for this layer include: Compromised framework components, backdoor attacks, input validation attacks, framework evasion and DoS attacks on the frameworks API’s.
These threats look to specifically target the frameworks being used to facilitate multi-agent architectures and environments and undermine the specific functionality and configurations of the agent frameworks.
A practical example here is a recently known exploited vulnerability (KEV) cited by CISA in the popular Langflow open source tool, which is used to build and deploy AI agents through a visual interface. The vulnerability was identified by Horizon3AI and allowed unauthenticated remote attackers to fully compromise Langflow servers.
Layer 4: Deployment and Infrastructure
The Deployment and Infrastructure is a layer many of us may be more comfortable with, especially if you’ve been working in cloud security, or even traditional infrastructure security prior to cloud.
AI is overwhelmingly run in cloud environments (see the massive investments the CSPs and AI leaders are looking to make in hosting environments and even energy). This includes virtual machines, Kubernetes clusters, and cloud virtualized infrastructure more broadly. This is due to demands around processing, dynamic scaling infrastructure, on-demand compute and more.
Ken cites threats in this layer including compromised container images, orchestration attacks, Infrastructure-as-Code (IaC) manipulation, Denial-of-Service (DoS), resource hijacking and lateral movement.
This is why fundamental security controls are still essential, things such as minimizing bloated dependencies, IaC scanning, hardening VM/Containers, monitoring for anomalous usage/consumption and preventing lateral movement through effective micro-segmentation, access control and overall zero trust principles.
Layer 5: Evaluation and Observability
As agents become pervasive in enterprise environments, poised to exponentially outnumber their human counterparts, evaluation and observability will be critical. This includes monitoring what actions the agents are taking, the tools they are interacting with, the processes they are partaking in, the data they interact with, and potentially anomalous behaviors.
The last point will be specifically important, as credential compromise remains a prominent attack vector, as does vulnerability exploitation, so agents will be targets for exploitation, as well as compromise, enabling attackers to conduct activities such as privileged escalation, lateral movement and move.
Specific threats Ken enumerates at this layer include manipulation of evaluation metrics, compromising observability tools, evading detection tooling, data leakage through observability and poisoning observability data.
Additionally, we’re seeing the emergence of a new AppSec category often called Application Detection and Response (ADR) or Cloud Application Detection and Response (CADR), which I’ve written about in articles such as “How ADR Addresses Gaps in the Detection & Response Landscape” and I anticipate this category will continue to evolve for AI and agentic workflows and workloads as well.
Layer 6: Security and Compliance (Vertical Layer)
Ah, everyone’s favorite topic, Compliance.
Now, before we get too far into the layer, for the naysayers who like to quip “compliance isn’t security”, I’d like to stop you there, and point out two things:
Compliance does equal security, just not the elimination of risk
Compliance does more to drive security investments and focus than any other factor in our industry, and in its absence we would be less, not more secure.
That said, I openly acknowledge compliance has massive problems with how we address it currently and is long overdue for innovative from the methodologies, tools and processes we use. I’ll point you to two of my articles on this topic:
Ken rightfully refers to this as a vertical layer because compliance requirements cut across all of the other layers in the MAESTRO reference model. Compliance must be integrated into all AI agent operations and activities.
While Ken does cite some specific threats such as security agent data poisoning, evasion of security AI agents, lack of explainability, model extraction of AI security agents and others, I would argue that nearly all of the risks we can think of related to agentic architectures have the potential to put us in a position of failing to meet compliance requirements or violating regulatory requirements depending on the specifics of the threats and scenarios.
It is also worth calling out that compliance frameworks tend to operate as analogs in a digital world. Technology moves fast but policy (compliance) tends to move much slower, and that isn’t inherently bad, as rushing to regulate technology too quickly can also leads to stifling innovation or incoherent compliance requirements that make little to no real-world sense.
That said, we do have an environment where the EU in particular has moved out quick on robust AI regulatory requirements, such as the EU AI Act and others that provide specific requirements on the usage of AI, and subsequently will apply to agents interacting with AI systems.
Organizations implementing agentic architectures and agents will need to account for emerging compliance and regulatory requirements, including existing requirements and frameworks and how those controls tie to their agents and the agents identities, access control, actions and anything else that may begin to come into scope for assessors and auditors evaluating IT systems and environments.
Layer 7: Agent Ecosystem
Rounding out the seven layered MAESTRO model Layer 7: Agent Ecosystem. This deals with the enterprise marketplace of agents and their implementations, from business applications, intelligent customer service platforms and enterprise automation solutions.
The risks Ken cites here include agent identity attacks, compromised agents, agent tool misuse, agent goal manipulation, marketplace manipulation and compromised agent registries among others.
Closing Thoughts
It of course is debatable if we need another threat modeling framework or which one is the “best” and more. That said, it is clear that MAESTRO represents a great mental model and additional tool for the practitioners toolbox when it comes to securing digital and cyber-physical systems, specifically those involving Agents and Agentic AI.
great insight and solid analysis. Thank you!
MAESTRO? No one is ever going to remember the words behind the Acronym 🙃