
Identity Is the Agentic AI Problem Nobody Has Solved Yet

The identity and access management industry spent decades building infrastructure to answer a relatively simple question about every request that hits an enterprise system.
Is this human who they claim to be, and are they authorized to do what they are asking to do?
That question, and the protocols built to answer it, assumed a world where the entity on the other end of every authentication flow was a person sitting at a keyboard, or at most a service account running a predictable workload with a static set of permissions.
AI agents break that assumption in ways that the existing IAM stack was never designed to handle, and the industry is now scrambling to figure out what comes next.
Enterprises are already deploying agents that authenticate to SaaS APIs, retrieve sensitive data, spawn sub-agents, chain tool invocations across multiple systems, and take actions with real business consequences, all at machine speed and with a degree of autonomy that no service account ever had.
The gap between what these agents can do and what IAM systems can govern about what they do is widening with every new deployment. As I have covered, identity is a core aspect of nearly every unresolved question about how to secure autonomous AI systems in the enterprise.
If you’re like me, and looking to think through the IAM implications of agents, I strongly recommend checking out blogs from folks such as Karl McGuinness and Christian Posta, both who have excellent thought provoking content on the topic.
I recently had a chance to sit down with Christian to discuss Agentic IAM and soon will be doing so with Karl, so keep an eye out for that.
The IAM Assumptions That No Longer Hold
Traditional IAM operates on a set of assumptions that have been stable for decades. Identities are either human or machine. Human identities are long-lived, tied to an employee or asset lifecycle, and governed through access certifications and role-based policies. Machine identities, service accounts and API keys, are provisioned for specific workloads with predictable behavior patterns and static permission sets. The entire governance model, from provisioning to certification to revocation, is built around these two categories.
AI agents fit cleanly into neither. They are not humans, but they act with a degree of autonomy and decision-making that service accounts never possessed. They are not traditional machine identities, because their behavior is non-deterministic by design. This isn’t a flaw, it is a fundamental design characteristic of LLM’s and the agents that act as the models arms and legs, giving them autonomy and the ability to take actions.
The same agent with the same permissions can take fundamentally different actions depending on the prompt it receives, the conversation context it carries, and the outputs of upstream agents in a delegation chain. An API key provisioned for a microservice calls the same endpoints at roughly the same cadence every time. An AI agent reasons about which tools to invoke, which APIs to call, and what data to retrieve based on context that changes with every single interaction.
Karl McGuinness, former chief product architect at Okta and one of the sharper thinkers in the identity standards community, has framed this distinction in a way that cuts to the core of the problem.
Agents do not need identity passports telling the world who they are. They need authority grants telling the world what they can do. The traditional IAM model is built around the passport metaphor, authenticating an entity's identity and then mapping that identity to a set of permissions. That works when the entity behaves predictably within those permissions. It breaks when the entity is an autonomous agent that picks its tool chain at runtime, chooses its next action as the task unfolds, and shifts its behavior with every new interaction. For agents, the question that matters is not "who are you" but "what are you authorized to do right now, in this specific context, for this specific task."
This means that the static authorization models enterprises have relied on for years, define a role, assign permissions, certify periodically, are insufficient for agents. The set of actions an agent might take is not fully knowable at the time permissions are granted, which makes traditional least-privilege enforcement a design-time exercise applied to a runtime problem, and given the non-deterministic nature of agents coupled with their ability to be influenced by what enters their context window, implementing least-permissive access control, as well as emerging concepts such as least-autonomy is challenging.
The OWASP Non-Human Identity Top 10 published in 2025 already cataloged the consequences of poor NHI management, including improper offboarding, secret leakage, overprivileged identities, long-lived credentials, and cross-environment reuse.
Those risks existed before agents entered the picture. Agents inherit all of them and add new dimensions that NHI frameworks were not built to address, particularly around non-deterministic behavior, multi-hop delegation, and the need for continuous runtime authorization rather than one-time permission grants.
CoSAI Lays the Groundwork

One of the more comprehensive attempts to define what agentic IAM should look like came from CoSAI’s Workstream 4 in March 2026 with their publication on Agentic Identity and Access Management. The paper is significant not because it solves the problem but because it establishes the architectural principles and design patterns that the industry will likely converge around over the next 12 to 18 months.
CoSAI’s framework rests on nine core imperatives that represent a meaningful departure from how most enterprises think about identity today. The first and most fundamental is treating agents as first-class identities, not shoehorning them into the human or service account categories that existing directories support. Agents need their own identity primitive with lifecycle management, governance, and accountability structures purpose-built for autonomous non-human actors.
The second imperative, eliminating standing privilege, directly addresses the static authorization problem. CoSAI argues that agents should never hold persistent permissions. Instead, access should be granted just-in-time, scoped to the specific task, and revoked immediately upon completion. This is a principle the industry has talked about for human identities for years and largely failed to implement. Applying it to agents is both more urgent and, potentially, more achievable because agents can be designed from the ground up to request and release credentials programmatically in ways that human workflows never could.
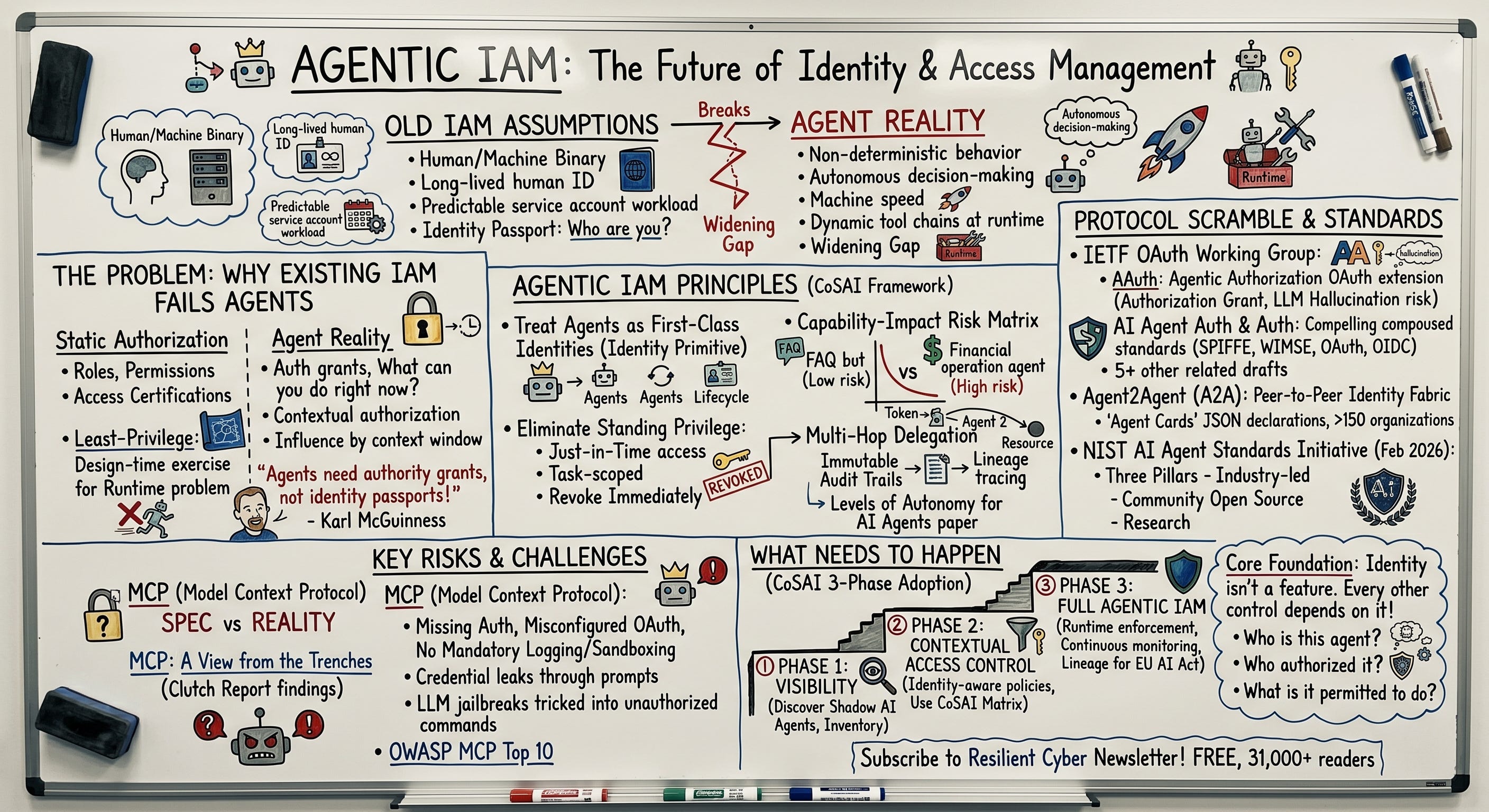
The paper introduces a capability-impact risk matrix that classifies agents from low-capability, low-risk scenarios like FAQ lookup bots through high-capability, high-risk scenarios like agents performing financial operations or administrative tasks. This classification matters because the security controls required vary dramatically across the spectrum, and organizations that apply uniform policies across all agent types will inevitably either over-constrain low-risk agents and slow down legitimate automation or under-constrain high-risk agents and create exposure they cannot see.
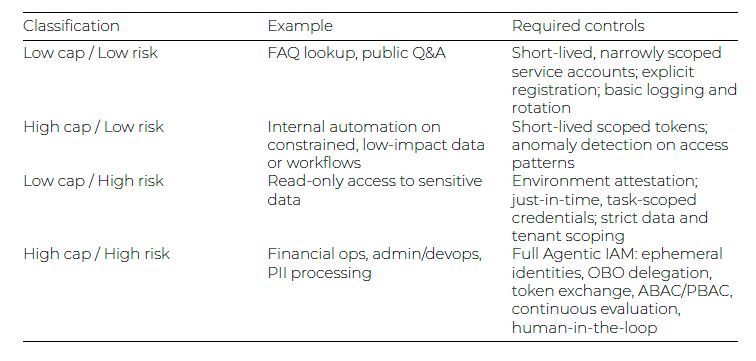
This spectrum-based approach reminds me of an excellent paper I’ve referenced lately in conversations which is “Levels of Autonomy for AI Agents”.
CoSAI’s technical patterns cover authentication through SPIFFE SVIDs and short-lived OAuth tokens, authorization through on-behalf-of token chains with scope attenuation at every hop, and governance through immutable audit trails that trace the full delegation lineage from the initiating human through every sub-agent invocation to the final resource access.
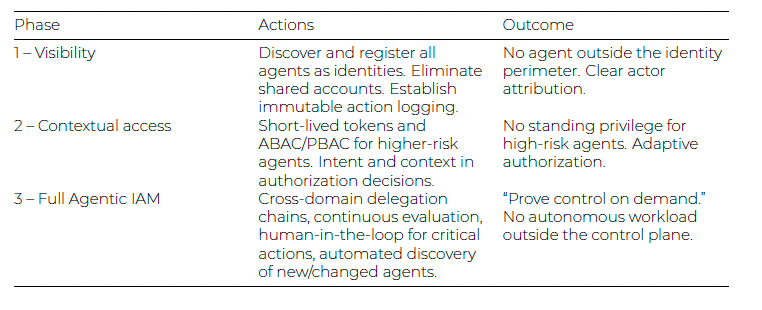
The paper also proposes a three-phase adoption strategy, moving from basic visibility into what agents exist and what they access, through contextual access controls, to full agentic IAM with runtime enforcement and continuous monitoring.
The most important contribution may be the framing of what CoSAI calls the identity primitive problem. Current security infrastructure forces a binary choice between human and service account, but agents represent something genuinely new. They act with autonomy that service accounts never had but within boundaries that should ultimately trace back to human authorization. Defining that new identity primitive, and building the protocols and infrastructure to support it, is the central unsolved challenge.
The Protocol Scramble
The recognition that agents need purpose-built identity protocols has triggered an interesting flurry of standardization activity, particularly within the IETF OAuth Working Group where multiple competing and complementary drafts are now circulating simultaneously.
The AAuth - Agentic Authorization OAuth 2.1 Extension, authored by Jonathan Rosenberg of Five9 and Patrick White of Bitwave, defines an Agent Authorization Grant as an OAuth 2.1 extension designed to let agents obtain access tokens on behalf of users through non-traditional channels where standard redirect-based OAuth flows are not possible. The draft explicitly addresses the LLM hallucination risk, recognizing that if an agent can fabricate credentials through hallucination, impersonation attacks become a first-order concern rather than an edge case.
A more comprehensive approach comes from AI Agent Authentication and Authorization, authored by contributors from Defakto Security, AWS, Zscaler, Ping Identity, and OpenAI. Rather than proposing new protocols, this draft demonstrates how existing standards including SPIFFE, WIMSE, OAuth 2.0, and OpenID Connect can be composed to solve agent authentication and authorization. The pragmatic approach of building on existing infrastructure investments rather than requiring enterprises to adopt entirely new protocol stacks gives this draft significant enterprise appeal.
Beyond these two, the OAuth Working Group is processing at least five additional agent-related drafts covering everything from OpenID Connect extensions for agent identity to secure intent protocols that address zero-trust drift caused by non-deterministic agent behavior. The volume of parallel proposals suggests the working group is still in a design space exploration phase, with consolidation likely over the next six to twelve months.
On the protocol layer above authentication, the Agent2Agent (A2A) protocol has emerged as the leading standard for agent-to-agent communication, now supported by over 150 organizations and integrated into leading platforms such as Azure AI Foundry, Amazon Bedrock, and Google Cloud.
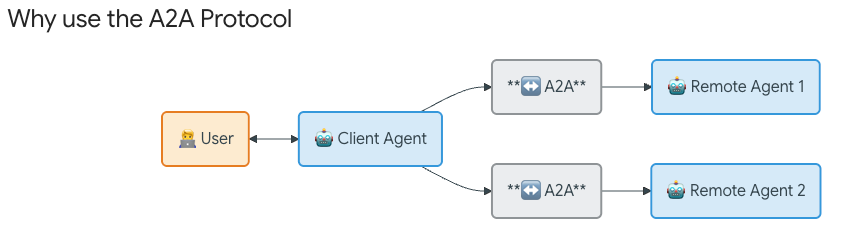
A2A handles agent identity through Agent Cards, discoverable JSON files that declare an agent’s authentication schemes, capabilities, and authorization requirements. While MCP addresses agent-to-tool interaction, A2A specifically standardizes how agents identify themselves to other agents, creating the peer-to-peer identity fabric that multi-agent architectures require. Below is a good visualization to see the difference between the two and how they compliment one another.
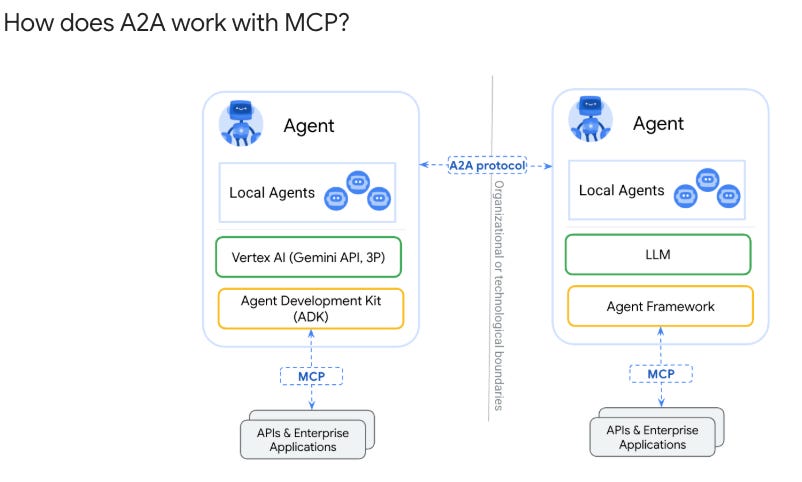
NIST launched its AI Agent Standards Initiative in February 2026, organizing work around three pillars of industry-led standards development, community-led open source protocol maintenance, and foundational research in agent security and identity.

The initiative’s concept paper asks the right questions about whether existing identity standards like OAuth, SPIFFE, and OpenID Connect are sufficient for agents or whether modifications and entirely new standards are needed. NIST’s listening sessions, which began in April 2026, are meant to identify sector-specific barriers to agent adoption and drive concrete standardization projects.
MCP and the Authentication Gap
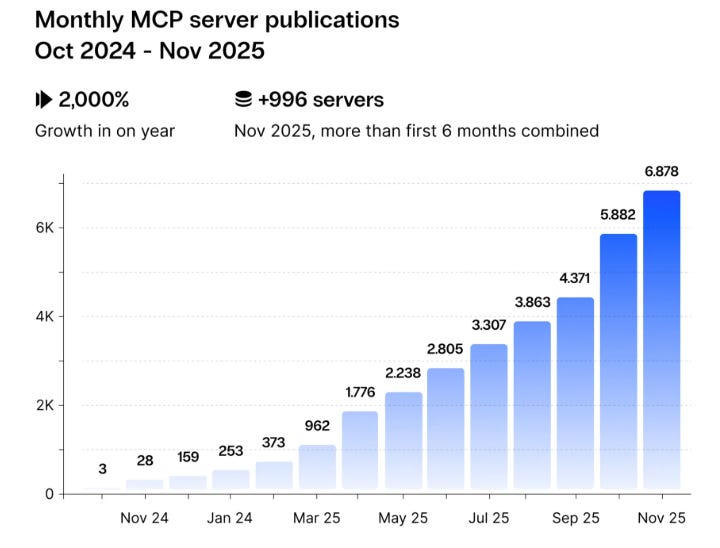
The Model Context Protocol deserves specific attention because it has become the de facto standard for how agents connect to tools and resources, with over 13,000 MCP servers deployed on GitHub in 2025 alone. MCP’s June 2025 specification update integrated OAuth 2.1 and adopted RFC 9728 for protected resource metadata, which lets agents dynamically discover authorization requirements rather than relying on hardcoded configurations.
The problem is that the specification and the reality of deployments are two different things. I previously shared an excellent report from Clutch Security titled “MCP: A View from the Trenches” that had some insightful (and alarming) findings.

Many MCP servers in the wild lack proper authentication entirely. OAuth implementations are frequently misconfigured. The specification does not enforce audit logging, sandboxing, or verification mechanisms, and as MCP expanded beyond simple synchronous tool calls into long-running governed workflows in its November 2025 update, the attack surface grew faster than the security controls keeping pace with it.
Security research through 2025 and 2026 has documented identity spoofing, credential leakage through prompts, cascading hallucinations that propagate false information through connected MCP servers, and LLM jailbreaks that trick agents into executing unauthorized commands through MCP integrations. OWASP even published an initial MCP Top 10, documenting these key risks.
This is the gap that organizations deploying agents at scale need to understand. The protocols are evolving in the right direction, but the deployed infrastructure is running ahead of the security controls, and the identity layer underneath most agent deployments today is held together with long-lived API keys, inconsistent access controls, and audit trails that would not survive a serious incident investigation.
What Needs to Happen
The path forward requires work at multiple layers simultaneously, and CoSAI’s three-phase adoption model provides a reasonable roadmap for how organizations should sequence it.
Phase one is visibility, a foundational critical security control for years in sources such as CIS Critical Controls and it applies here too. You cannot secure agents you do not know exist, and shadow AI is already a serious problem in most enterprises. Employees are provisioning agents that connect to enterprise systems through personal accounts, hardcoded credentials, and unmonitored API integrations. Establishing a discovery and inventory capability for agents is the prerequisite for everything else.
Phase two is contextual access control. Once organizations know what agents exist and what they connect to, the next step is applying identity-aware policies that account for agent type, delegation model, and risk classification. This is where the CoSAI capability-impact matrix becomes operationally useful, because the controls appropriate for a low-risk FAQ bot are wildly different from those required for an autonomous agent executing financial transactions. It’s this organizational and use case context that can help drive appropriate security controls and safeguards.
Phase three is full agentic IAM with runtime enforcement, continuous monitoring, and the kind of attribution and lineage tracking that regulators under frameworks like the EU AI Act are already beginning to require. This phase demands the protocol maturity that the IETF drafts are working toward and the infrastructure investment that most enterprises have not yet made.
The honest assessment is that the industry is somewhere between phase one and phase two for most organizations, with a small number of forward-leaning enterprises beginning to experiment with phase three capabilities. The standards are not yet settled, the protocols are not yet consolidated and the tooling is not yet mature. But the agents are already deployed and operating with permissions that most security teams cannot fully enumerate, let alone govern.
The organizations that will navigate this transition successfully are the ones that recognize identity is not a feature of their agent security strategy, it is a core part of the foundation. Every other control, runtime monitoring, policy enforcement, anomaly detection, incident response, depends on a functioning identity layer that can answer three questions about every agent interaction.
Who is this agent?
Who authorized it to act?
What exactly is it permitted to do?
The industry built that capability for humans over two decades and even now still struggles to implement it effectively at scale, as evident by year-after-year of credential compromise and incidents persisting.
With the pace of agentic adoption, it does not have two decades to build it for agents.
Agent Transfer Protocol - AGTP.io solves these problems.